本文主要是介绍对《Detecting Rumors from Microblogs with Recurrent Neural Networks》 解读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
对《Detecting Rumors from Microblogs with Recurrent Neural Networks》 解读
Abstract
微博社交平台是谣言传播的理想场所, 因此自动进行谣言检测成为了目前的关键问题。在以往的方法中, 主要通过自己设置特征向量并利用机器学习方法进行检测。本文所利用的方法是通过RNN 来进行谣言检测, 因为循环神经网络在时序问题解决较好, 能够捕捉上下文信息。此模型在两个社交平台上做实验, 并取得了以下结果:
- RNN 方法超过了目前主流的利用手工制作特征的模型
- 通过循环神经单元和抽取的隐藏层, RNN算法性能得到了较好的改善
- RNN方法的谣言检测比存在的技术侦测谣言更快且准确
Introduction
此论文的贡献与上述摘要的结果大同小异, 这里只是截图展现出来。

RNN-based Rumor Detection
在此论文中, 第三部分介绍了传统RNN 、LSTM和GRU的算法流程, 第四部分也就是这一部分才说明如何用以上模型或者怎么联合以上模型来进行谣言检测。
同样的, 我们有许多微博, 然后在微博下方有许多评论。这些评论的内容是有先后顺序的, 这正好可以与RNN的内容相对应。但是从我们所训练的数据集来看, 有的微博的下方评论可能有上千条,有的甚至或许有上万条。这对时序模型RNN来说,训练会花费很长时间,而且并没有GPU并行进行补救。所以再将RNN这些模型应用到谣言检测前,故需要对这些评论内容进行数据处理。

如上图所示, 这就是数据的处理流程。 此算法的思想是,用时间间隔代替时刻, 这样可以减少RNN的单元数目。在这里设置N为所要参考的时间间隔数目。接着初始化每个时间间隔所能达到最大的评论数, 然后就进行慢慢的迭代循环。 在图中循环内容大体意思是, 将没有评论内容的时间间隔去掉, 然后选取最多的连续的非空的时间间隔数目。若所选的时间间隔数量小于N 并且此时的时间间隔数量比上轮的大, 则就需要将原来的时间间隔进行划分,流程图中以一半作为单位。这样就有很大的机会使连续的时间间隔数变多, 更容易达到N的数量。 所以 最后所得到的整体数量与N相差不大。
Structures of Models
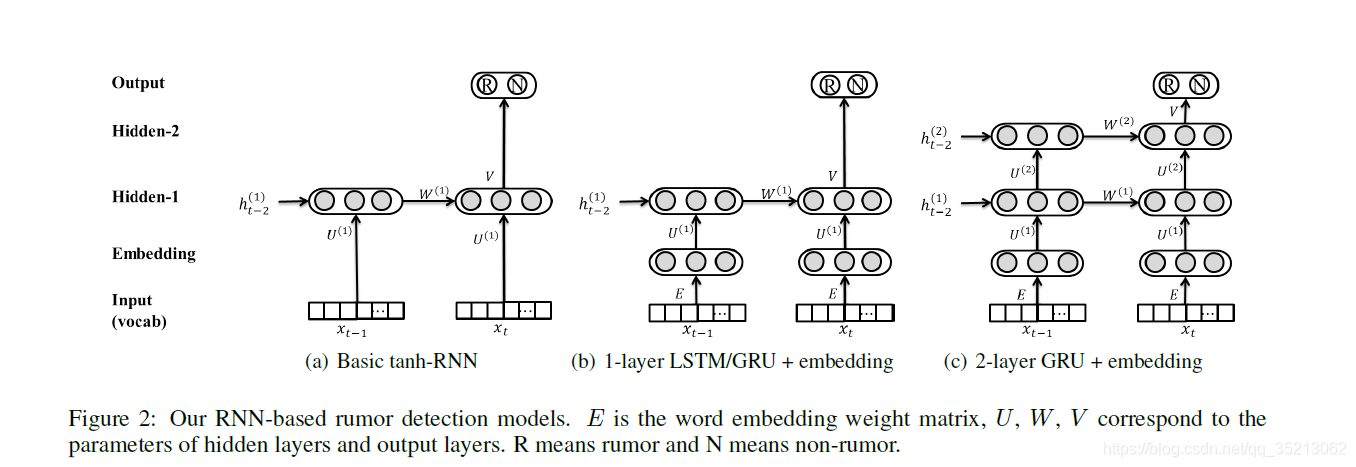
图中所示, 为论文所提出的三个模型,接下来简要介绍下。
这三个模型输入都为tf * idf 向量
第一个模型为 tanh-RNN, 这是一个基础架构,其中并不含有门单元, 就是传统的rnn模型, 不过在损失函数中加了第二范式。
第二个模型, 为 1-layer LSTM/GRU + embedding . LSTM 和 GRU 模型可以捕获句子长时间依赖, 不过其带有门机制,就会导致它们的参数巨大 , 故 在输入上加了embedding层, 将长维度以短维度来表示, 以减少计算量。
第三个模型,在第二个模型的基础上增添了一个隐藏层, 目的为了获取更高等级的特征表示, 来捕获不同时间步之间的关联信息。详细公式如下。
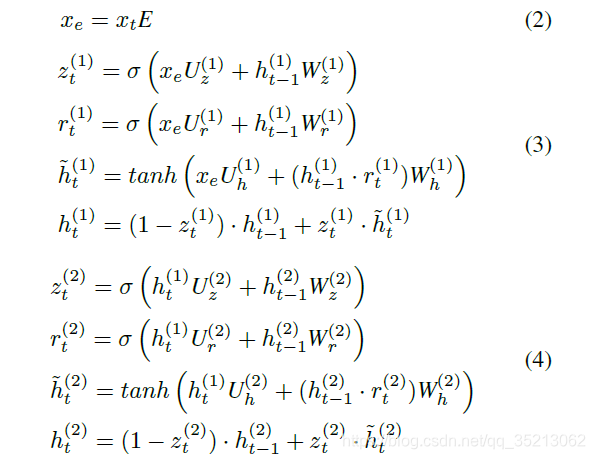
Experiments and Results
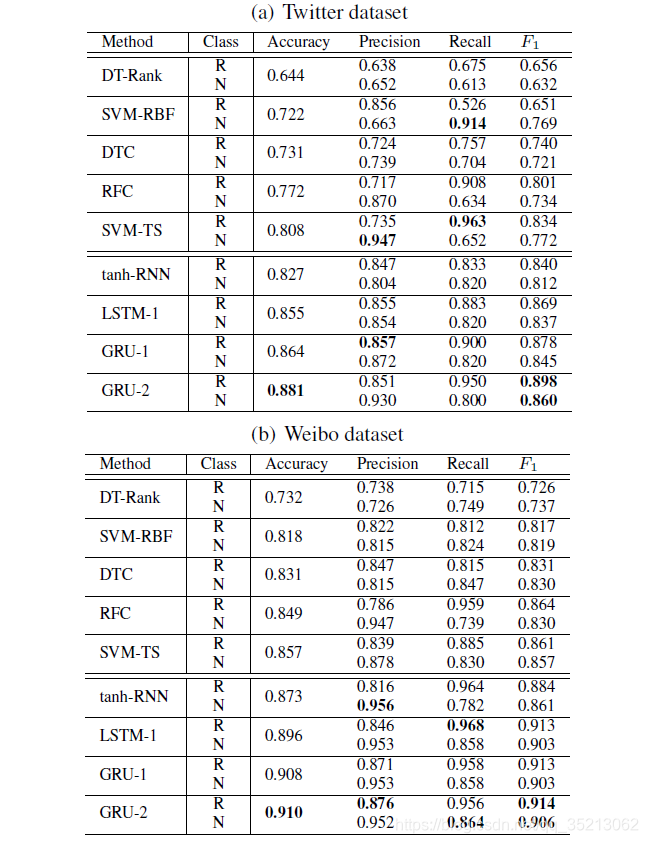
此论文在谣言检测应用中应该是使用深度学习模型的第一篇文章, 故引用量可想而知。 这篇文章实验部分是在Twitter and Sina Weibo两个数据集上。
此为对比试验。
以下图三展示了随着训练时间的增长, 损失也慢慢在收敛。
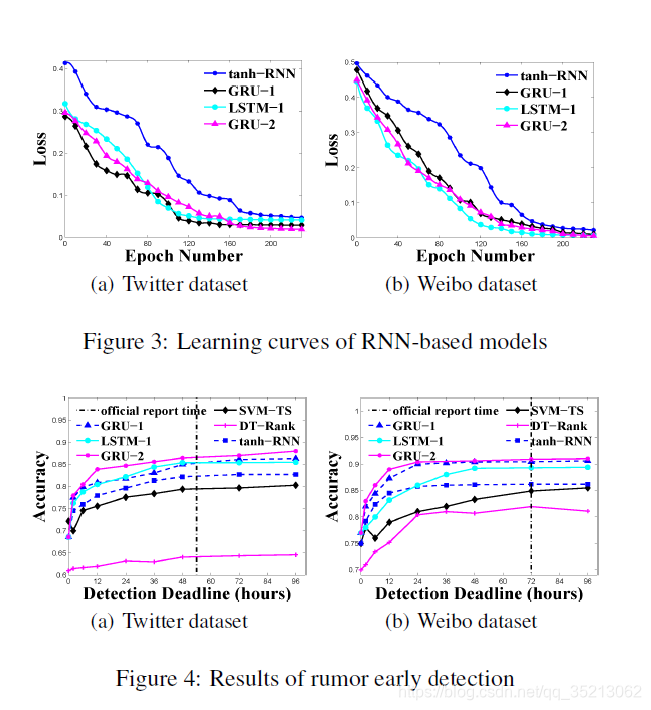
图四是展示将模型应用在谣言检测早期的结果。横坐标代表deadline, 纵坐标为在每个时刻时, 检测的准确度值。
这篇关于对《Detecting Rumors from Microblogs with Recurrent Neural Networks》 解读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








