本文主要是介绍因果推断--双重差分法(DID)的原理和实际应用(一),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、应用场景
二、DID知识介绍
2.1 理论知识介绍
2.2 DID图形化解释
三、应用案例:
3.1 构造对照组
3.2 平行趋势检验
3.3 因果效应评估
四、优缺点总结
一、应用场景
在精细化运营场景中,常常会面临如下问题,不方便或者不允许进行常规的实验设计(AB实验)来考察策略的效果,只能采用全量上线的方式进行,但仍需分析策略的效果,以进行优化和推广。在如下场景中:上线了某付费产品活动,用户可付费开通xx卡,该卡可绑定一名亲友,亲友和自己都能使用该卡进行支付。这种场景很难通过实验的方式进行变量控制,我们不能简单的对某一类用户进行限制,限制其不可进行购买或被绑定,这样对用户体验的伤害很大,也会让用户感到奇怪甚至被歧视。对于这种无法进行实验设计但又必须知道策略是否给业务带来收益的场景,因果推断中的双重差分法就可解决以上问题。
二、DID知识介绍
2.1 理论知识介绍
双重差分法(Differences-in-Differences,DID)主要应用于评价某一事件或政策的影响程度。该方法基于反事实理论框架评估策略发生和不发生两种情况下待解释变量的变化。反事实理论框架是指通过分析策略干预后,实验组待解释变量的变化和假设实验组未被策略干预下,待解释变量变化之间的差异,从而评价策略的影响。策略干预后,实验组待解释变量的变化,我们是可以观测到的,但同一时期内,若实验组未被策略干预,待解释变量呈什么样的数据变化,我们是无法观测到的。于是,我们需要引入对照组,这个对照组的待解释变量随时间的变化趋势等同于实验组待解释变量随时间的变化趋势,才可以用双重差分法进行分析,也就是要满足如下两个假设:
1、个体处理稳定性假设: 实验中每个实验参与单元的行为是相互独立的,独立是指一个用户的行为不受其他用户影响。
2、平行趋势假设:在没有策略干预的情况下,对照组和实验组待解释变量之间的差异不随时间变化。
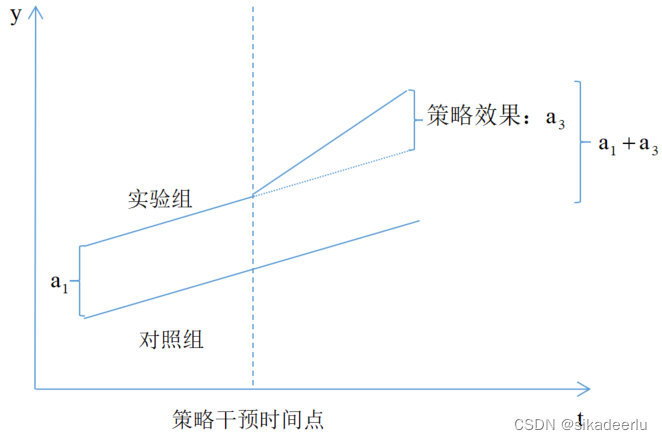
2.2 DID图形化解释
如下图所示:策略干预前实验组和对照组待解释变量的差异是,当对实验组施加干预后,实验组和对照组待解释变量的差异变成了
,那么
即为策略干预效果。
三、应用案例:
在上述应用场景中,该付费产品上线了一段时间后,我们需要评估该活动带来的单量及收益提升情况,辅助进行活动推广和优化。假设在2022年10月的开卡用户共20w,这些用户就是实验组用户,是需要进行评估的对象。根据双重差分法,我们需要构造一个相似的用户群体,让其历史的下单和开卡用户的历史下单满足平行趋势,且这个相似用户群体,历史未曾开通过该卡。如下是DID进行因果效应评估的关键步骤:
3.1 构造对照组
在10月的用户中,按照开卡用户历史下单频次分布进行分层抽样,同样抽取20w未曾开通过该卡的用户作为对照组。

3.2 平行趋势检验
验证实验组(开卡用户)和对照组(抽样用户)的历史单量是否满足平行趋势,我们分别取这些用户在2022年4月至2022年10月的单量进行检验。如果满足平行趋势,我们需考察其在2022年10月以后的单量差异。下图是实验组、对照组用户在2022年10月前后的人均单量趋势:
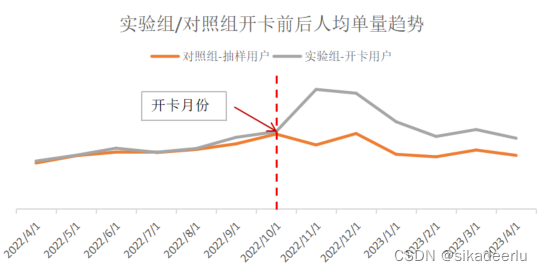
从图中可以看出,在2022年10月及以前,构造的虚拟对照组用户的人均单量基本和实验组-开卡用户保持一致,因此满足平行趋势假设,可用双重差分法对策略效果进行评估。
3.3 因果效应评估
从图中可以看出,在2022年10月开卡以后,实验组用户的人均单量较对照组有明显的提升,人均单量提升在0.96-3.11,由此可计算开卡后,实验组用户在每个月的单量提升以及收入的提升情况。

2022年10月之前实验组与对照组人单量差异均值为0.13,10月之后实验组较对照组人均单量提升差异需减去开通之前人均单量差异的均值0.13,下表为开卡后按照DID模型测算的实际人均单量、总单量以及收入的提升情况:

由上表可以看出,实验组开卡用户在11月实际人均单量提升为2.98,总量提升为59.6w,收入提升为893.3w,在后续每个月中,实际人均单量差异逐渐缩小到0.83,总单量较对照组提升缩小至16.6w,收入提升为248.5w。
四、优缺点总结
优点:
通过以上案例可以看到,在没有AB实验数据的情况下,如果我们有实验前后的时间序列数据,并能构造一个和实验组待解释变量满足平行趋势的对照组的话,我们就可以用DID进行因果效应评估。使用DID时不需要考虑实验组和对照组之间的差异,在构造虚拟的对照组时,不需要和实验组完全一样,这个操作相对来说较为简单,因果效应的测算过程也较简单。
局限性:
首先需要有实验前后的时间序列数据,其次是平行趋势假设,这个是一个很强的假设,我们需要构造一个和实验组用户在待解释指标上满足平行趋势假设的虚拟对照组才能进行接下来的效果评估,而这有时候并不好构造。
这篇关于因果推断--双重差分法(DID)的原理和实际应用(一)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



