本文主要是介绍MySQL调优学习笔记(四):MySQL优化器(CBO),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
MySQL优化器(CBO)
mysql索引一般建立在高选择性字段上,也有例外
总结
参考资料:姜承尧的MySQL实战宝典
MySQL优化器(CBO)
MySQL优化器决定了具体某一索引的选择,也就是常说的执行计划。优化器的选择是基于成本,它会分析所有可能的执行计划,哪个索引的成本越低,优先使用哪个索引。这种优化器称之为:CBO(Cost-based Optimizer,基于成本的优化器)。
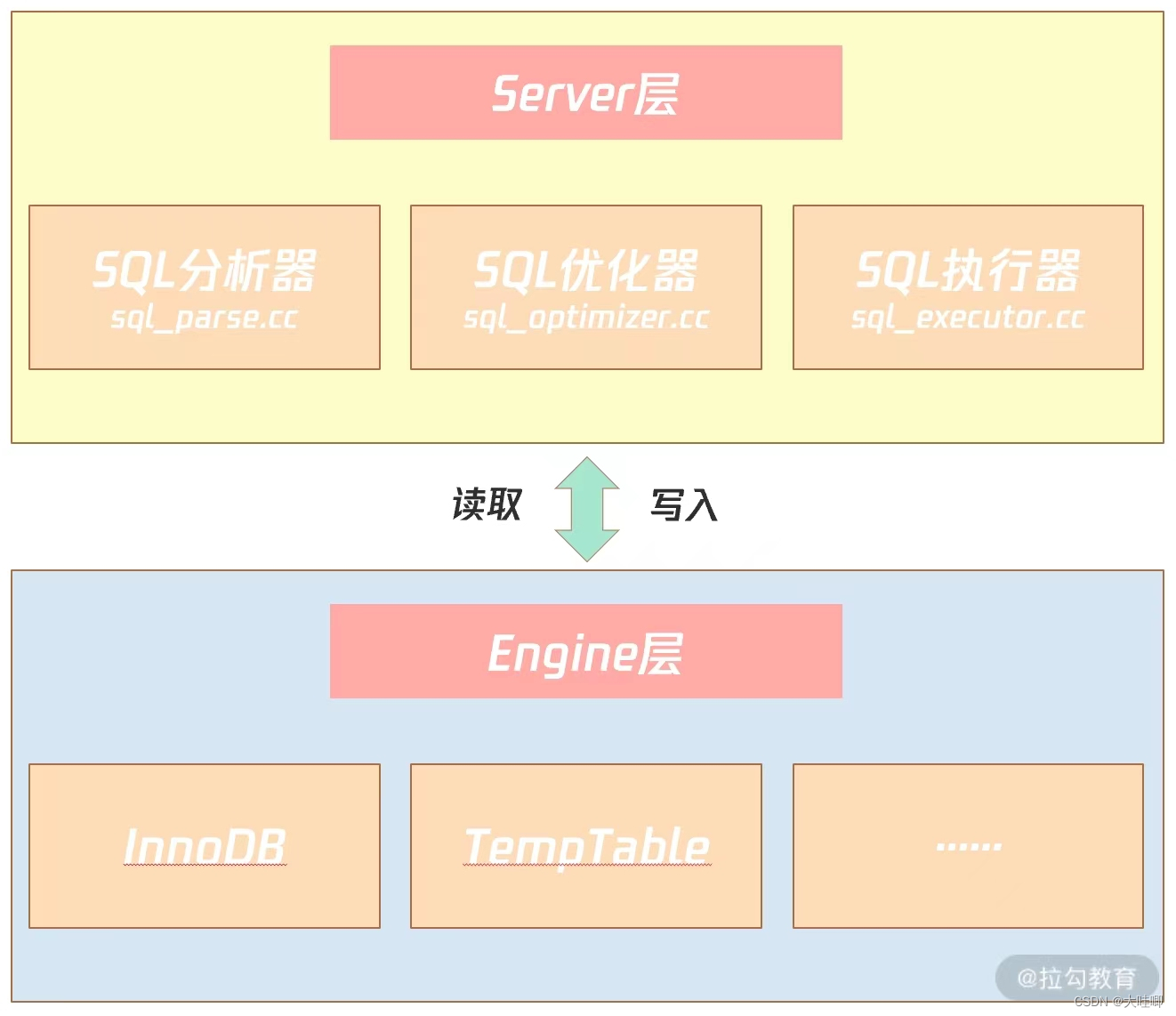
MySQL 数据库由 Server 层和 Engine 层组成。Server 层有 SQL 分析器、SQL优化器、SQL 执行器,用于负责 SQL 语句的具体执行过程;Engine 层负责存储具体的数据,如最常使用的 InnoDB 存储引擎,还有用于在内存中存储临时结果集的 TempTable 存储引擎。
在 MySQL中,一条 SQL 的计算成本公式如下:
Cost = Server Cost + Engine Cost = CPU Cost + IO Cost
其中,CPU Cost 表示计算的开销,比如索引键值的比较、记录值的比较、结果集的排序……;IO Cost 表示引擎层 IO 的开销,包括读取内存 IO 开销以及读取磁盘 IO 开销。
数据库 mysql 下的表 server_cost、engine_cost 记录了对于各种成本的计算。
SELECT * FROM mysql.server_cost;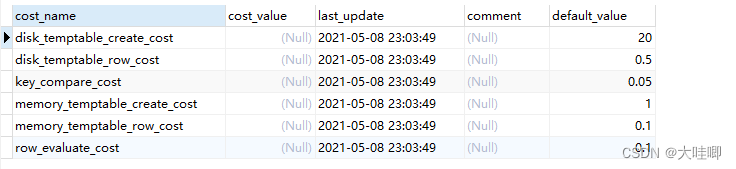 表 server_cost 记录了 Server 层优化器各种操作的成本,这里面包括了所有 CPU Cost,具体含义如下。
表 server_cost 记录了 Server 层优化器各种操作的成本,这里面包括了所有 CPU Cost,具体含义如下。
- disk_temptable_create_cost:创建磁盘临时表的成本,默认为20。
- disk_temptable_row_cost:磁盘临时表中每条记录的成本,默认为0.5。
- memory_temptable_create_cost:创建内存临时表的成本:默认为1。
- memory_temptable_row_cost:内存临时表中每条记录的成本,默认为0.1。
- key_compare_cost:索引键值比较的成本,默认为0.05。
- row_evaluate_cost:记录间的比较成本,默认为0.1。
可以看到, MySQL 优化器认为如果一条 SQL 需要创建基于磁盘的临时表,则这时的成本是最大的,其成本是创建基于内存临时表的 20 倍。而索引键值的比较、记录之间的比较,其实开销是非常低的,但如果要比较的记录数非常多,则成本会变得非常大。
SELECT * FROM mysql.engine_cost;
而表 engine_cost 记录了 Engine 层各种操作的成本,这里包含了所有的 IO Cost,具体含义如下。
- io_block_read_cost:从磁盘读取一个页的成本,默认值为1。
- memory_block_read_cost:从内存读取一个页的成本,默认值为0.25。
也就是说, MySQL 优化器认为从磁盘读取的开销是内存开销的 4 倍。
不过,上述所有的成本都是可以修改的,比如如果数据库使用是传统的 HDD 盘,性能较差,其随机读取性能要比内存读取慢 50 倍,那可以通过下面的 SQL 修改成本:
INSERT INTO
mysql.engine_cost(engine_name,device_type,cost_name,cost_value,last_update,comment)
VALUES ('InnoDB',0,'io_block_read_cost',12.5,CURRENT_TIMESTAMP,'Using HDD for InnoDB');
FLUSH OPTIMIZER_COSTS;mysql索引一般建立在高选择性字段上,也有例外
B+ 树索引通常要建立在高选择性的字段或字段组合上,如订单 ID、日期等,因为这样每个字段值大多并不相同。但在有些低选择性的列上,也是有必要创建索引的。
比如电商的核心业务表 orders,其有字段orderstatus,表示当前的状态。状态是有限的,一般仅为已完成、支付中、超时已关闭这几种。在电商业务中会有一个这样的逻辑:即会定期扫描字段 orderstatus 为支付中的订单,然后强制让其关闭,从而释放库存,给其他有需求的买家进行购买。通常订单状态绝大部分都是已完成,只有绝少部分会是支付中,因此订单状态是存在数据倾斜的。
虽然orderstatus是低选择性的,但是由于其有数据倾斜,且我们只是从索引查询少量数据,因此可以对orderstatus创建索引,根据索引查询的效率会更高。但优化器会认为数据是比较均匀的,为了避免通过二级索引再回表,使用全表扫描的效率会更高。这种情况下,我们可以利用 MySQL 8.0 的直方图功能,创建一个直方图,让优化器知道数据的分布,从而更好地选择执行计划。此时再去查询支付中的订单时,就会使用到索引了。
直方图的创建命令如下所示:
ANALYZE TABLE orders UPDATE HISTOGRAM ON orderstatus;在创建完直方图后,MySQL会收集到字段 orderstatus 的数值分布,可以通过下面的命令查询得到:
SELECT * FROM information_schema.column_statistics
WHERE column_name = 'orderstatus';总结
- MySQL 优化器是 CBO 的,MySQL 会选择成本最低的执行计划;
- 一般只对高选择性的字段和字段组合创建索引;
- 当低选择性的字段数据存在倾斜,通过索引找出少部分数据,可以考虑创建索引。若数据存在倾斜,可以创建直方图,让优化器知道索引中数据的分布,进一步校准执行计划。
这篇关于MySQL调优学习笔记(四):MySQL优化器(CBO)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



