本文主要是介绍SQL left join 左表合并去重技巧总结,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
建表:
- CREATE TABLE `table1` (
- `id` int(11) NOT NULL AUTO_INCREMENT,
- `name` varchar(60) DEFAULT NULL,
- `age` varchar(200) DEFAULT NULL,
- `sponsor_id` varchar(20) DEFAULT NULL COMMENT '业务发起人',
- `gmt_create_user` int(11) NOT NULL COMMENT '创建人id',
- `gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
- `gmt_modified` datetime DEFAULT NULL COMMENT '修改时间',
- `gmt_modified_user` int(11) DEFAULT NULL COMMENT '修改人id',
- PRIMARY KEY (`id`)
- ) ENGINE=InnoDB AUTO_INCREMENT=12 DEFAULT CHARSET=utf8mb4 COMMENT='测试表1';
-
- CREATE TABLE `table2` (
- `kid` int(11) NOT NULL AUTO_INCREMENT,
- `name` varchar(60) DEFAULT NULL,
- `sponsor_id` varchar(20) DEFAULT NULL COMMENT '业务发起人',
- `type` int(11) NOT NULL COMMENT '创建人id',
- `gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
- `gmt_modified` datetime DEFAULT NULL COMMENT '修改时间',
- `gmt_modified_user` int(11) DEFAULT NULL COMMENT '修改人id',
- PRIMARY KEY (`kid`)
- ) ENGINE=InnoDB AUTO_INCREMENT=12 DEFAULT CHARSET=utf8mb4 COMMENT='测试表2';
插入数据:
- INSERT INTO `table1`(`id`, `name`, `age`, `sponsor_id`, `gmt_create_user`, `gmt_create`, `gmt_modified`, `gmt_modified_user`) VALUES (1, 't1', '11', '10', 1, '2018-10-10 20:34:03', NULL, NULL);
- INSERT INTO `table1`(`id`, `name`, `age`, `sponsor_id`, `gmt_create_user`, `gmt_create`, `gmt_modified`, `gmt_modified_user`) VALUES (2, 't2', '12', '10', 2, '2018-10-10 20:34:03', NULL, NULL);
- INSERT INTO `table1`(`id`, `name`, `age`, `sponsor_id`, `gmt_create_user`, `gmt_create`, `gmt_modified`, `gmt_modified_user`) VALUES (3, 't3', '13', '10', 3, '2018-10-10 20:34:03', NULL, NULL);
- INSERT INTO `table1`(`id`, `name`, `age`, `sponsor_id`, `gmt_create_user`, `gmt_create`, `gmt_modified`, `gmt_modified_user`) VALUES (4, 't4', '14', '20', 4, '2018-10-10 20:34:03', NULL, NULL);

- INSERT INTO `table2`(`kid`, `name`, `sponsor_id`, `type`, `gmt_create`, `gmt_modified`, `gmt_modified_user`) VALUES (1, 't1', '10', 1, '2018-10-10 20:38:10', NULL, NULL);
- INSERT INTO `table2`(`kid`, `name`, `sponsor_id`, `type`, `gmt_create`, `gmt_modified`, `gmt_modified_user`) VALUES (2, 't2', '10', 1, '2018-10-10 20:38:10', NULL, NULL);
- INSERT INTO `table2`(`kid`, `name`, `sponsor_id`, `type`, `gmt_create`, `gmt_modified`, `gmt_modified_user`) VALUES (3, 't3', '10', 1, '2018-10-10 20:38:10', NULL, NULL);
- INSERT INTO `table2`(`kid`, `name`, `sponsor_id`, `type`, `gmt_create`, `gmt_modified`, `gmt_modified_user`) VALUES (4, 't4', '10', 1, '2018-10-10 20:38:10', NULL, NULL);
- INSERT INTO `table2`(`kid`, `name`, `sponsor_id`, `type`, `gmt_create`, `gmt_modified`, `gmt_modified_user`) VALUES (5, 't5', '10', 1, '2018-10-10 20:38:10', NULL, NULL);
- INSERT INTO `table2`(`kid`, `name`, `sponsor_id`, `type`, `gmt_create`, `gmt_modified`, `gmt_modified_user`) VALUES (6, 't6', '10', 1, '2018-10-10 20:38:10', NULL, NULL);
- INSERT INTO `table2`(`kid`, `name`, `sponsor_id`, `type`, `gmt_create`, `gmt_modified`, `gmt_modified_user`) VALUES (7, 't7', '10', 2, '2018-10-10 20:38:10', NULL, NULL);
- INSERT INTO `table2`(`kid`, `name`, `sponsor_id`, `type`, `gmt_create`, `gmt_modified`, `gmt_modified_user`) VALUES (8, 't1', '11', 1, '2018-10-10 20:38:10', NULL, NULL);
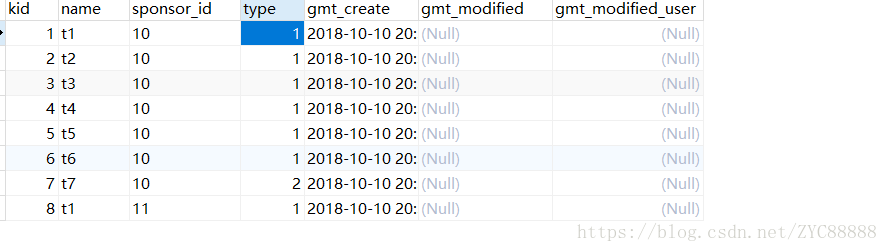
查询异常:
- SELECT
- a.*,
- b.type
- FROM
- table1 a
- LEFT JOIN table2 b ON a.sponsor_id = b.sponsor_id
- WHERE
- b.type = 1
- AND a.sponsor_id = 10;
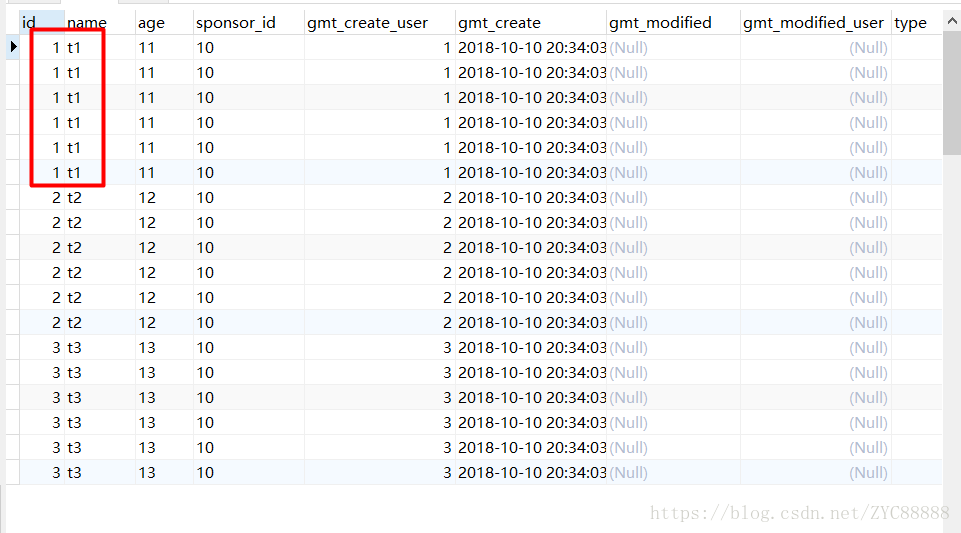
简单说明问题出现的原因:
MySQL left join 语句格式为: A LEFT JOIN B ON 条件表达式
left join 是以A表为基础,A表即左表,B表即右表。
左表(A)的记录会全部显示,而右表(B)只会显示符合条件表达式的记录,如果在右表(B)中没有符合条件的记录,则记录不足的地方为NULL。
- 使用left join, A表与B表所显示的记录数为 1:1 或 1:0,A表的所有记录都会显示,B表只显示符合条件的记录。
-
- 但如果B表符合条件的记录数大于1条,就会出现1:n的情况,这样left join后的结果,记录数会多于A表的记录数。
所以解决办法 都是从一个出发点出发,使A表与B表所显示的记录数为 1:1对应关系。
解决方法:
使用非唯一标识的字段做关联
1 DISTINCT
select DISTINCT(id) from a left join b on a.id=b.aid DISTINCT查询结果是 第一个表唯一的数据 重复的结果没显示出来
- SELECT
- DISTINCT(a.id), a.*,
- b.type
- FROM
- table1 a
- LEFT JOIN table2 b ON a.sponsor_id = b.sponsor_id
- WHERE
- b.type = 1
- AND a.sponsor_id = 10;
- SELECT
- DISTINCT a.*,
- b.type
- FROM
- table1 a
- LEFT JOIN table2 b ON a.sponsor_id = b.sponsor_id
- WHERE
- b.type = 1
- AND a.sponsor_id = 10;
2 GROUP BY
select * from a left join(select id from b group by id) as b on a.id=b.aid 拿出b表的一条数据关联 使A表与B表所显示的记录数为 1:1对应关系。
- SELECT
- a.*,
- b.type
- FROM
- table1 a
- LEFT JOIN ( SELECT * FROM table2 GROUP BY sponsor_id ) AS b ON a.sponsor_id = b.sponsor_id
- WHERE
- b.type = 1
- AND a.sponsor_id = 10;
3 max取唯一
select * from a left join (select max(id) from table group by id) as b on a.id=b.aid 拿出b表的最后一条数据关联
- SELECT
- a.*,
- b.type
- FROM
- table1 a
- LEFT JOIN ( SELECT MAX( kid ), type, sponsor_id FROM table2 GROUP BY sponsor_id ) AS b ON a.sponsor_id = b.sponsor_id
- WHERE
- b.type = 1
- AND a.sponsor_id = 10;
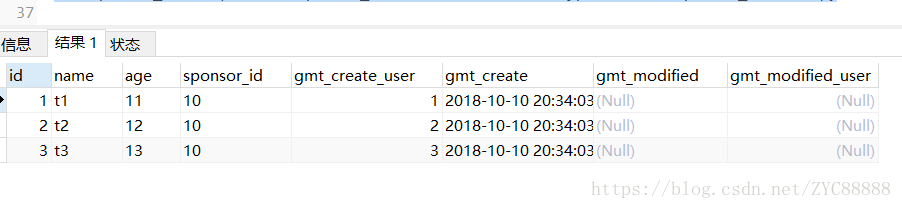
4 IN巧用
- SELECT
- a.*
- FROM
- table1 a
- WHERE
- a.sponsor_id IN ( SELECT sponsor_id FROM table2 WHERE type = 1 AND sponsor_id = 10 );
- SELECT
- a.*,
- 1
- FROM
- table1 a
- WHERE
- a.sponsor_id IN ( SELECT sponsor_id FROM table2 WHERE type = 1 AND sponsor_id = 10 );
相信对于熟悉SQL的人来说,LEFT JOIN非常简单,采用的时候也很多,但是有个问题还是需要注意一下。假如一个主表M有多个从表的话A B C …..的话,并且每个表都有筛选条件,那么把筛选条件放到哪里,就得注意喽。
比如有个主表M,卡号是主键。
| 卡号 | 客户号 |
|---|---|
| 6223123456781001 | 1001 |
| 6223123456781002 | 1002 |
| 6223123456781003 | 1003 |
有个从表A,客户号、联系方式是联合主键,其中联系方式,1-座机,2-手机号码
| 客户号 | 联系方式 | 联系号码 |
|---|---|---|
| 1001 | 1 | 010-78586 |
| 1001 | 2 | 18810123456 |
| 1002 | 1 | 010-837433 |
| 1003 | 1 | 010-837433 |
如果想要查询所有卡号对应的手机号码两个字段,很简单,SQL语句如下:
- SELECT A.卡号,B.手机号码
- FROM A
- LEFT JOIN B
- ON A.客户号=B.客户号
- WHERE B.联系方式='2'
相信很多人这样写,估计实际工作中也会看到这样的语句,并不是说这么写一定会错误,实际SQL表达的思想一定是要符合业务逻辑的。
前面已经说清楚,所有卡号对应的手机号码。所有卡号,所以首先肯定以A表作为主表,并且左关联B表,这样A表所有的卡号一定会显示出来,但是如果B表的筛选条件放到最外层,这样就相当于将A表关联B表又做了一遍筛选,结果就是
| 卡号 | 手机号码 |
|---|---|
| 6223123456781001 | 18810123456 |
就会筛选出来这么一条数据,丢失了A表中其他的卡号。
实际工作中表结构肯定没这么简单,关联的表也会很多,当有很多条件时,最好这么写
- SELECT A.卡号,B.手机号码
- FROM A
- LEFT JOIN (
- SELECT * FROM B
- B.联系方式='2'
- )B
- ON A.客户号=B.客户号
这么写的话,A表中的数据肯定会完全保留,又能与B表的匹配,不会丢失数据。
PS:
- 1、表结构
- 2、Left Join
- 3、Right Join
- 4、Inner Join
- 5、表的关联修改和删除
- 6、笛卡尔积
1、表结构
表A 表B

2、Left Join
示例:2.1
Select * From A left join B on A.aid = B.bid;
left join是以A表的记录为基础的,A可以看成左表,B可以看成右表,left join是以左表为准的。 换句话说,左表A的记录将会全部表示出来,而右表B只会显示符合搜索条件的记录(例子中为: A.aid = B.bid),B表记录不足的地方均为NULL.
- A表所有记录都会显示,A表中没有被匹配的行(如aid=5、6的行)相应内容则为NULL。
- 返回的记录数一定大于A表的记录数,如A表中aid=7行被B表匹配了3次(因为B表有三行bid=7)。
注意:在Access中A.aid、B.bid不能缩写成aid、bid,否则会提示“不支持链接表达式”,这一点不同于Where查询。
3、Right Join
示例:3.1
Select * From A right join B on A.aid = B.bid;
仔细观察一下,就会发现,和left join的结果刚好相反,这次是以右表(B)为基础的,A表不足的地方用NULL填充。
4、Inner Join
示例:4.1
Select * From A inner join B on A.aid = B.bid;
这里只显示出了 A.aid = B.bid的记录.这说明inner join并不以谁为基础,它只显示符合条件的记录。
inner join 等同于Where查询如:
Select * From A, B Where A.aid = B.bid
5、表的关联修改和删除
5.1修改
示例:5.1.1

上述SQL实际操作的表为"Select * From A left join B on A.aid = B.bid",因此Access会提示更新13条记录(Select查询出的记录就是13条)。对比“示例:2.1”返回的结果,分析update后的A表:
- aid=5、6的记录,被更新为NULL
- aid=7的记录,被更新了3次,依次是“b1997-1”、“b1997-2”、“b1997-3”,因此其结果为最后一次更新“b1997-3”
对于上述SQL同样可以将“A.aname = B.bname”改成“B.bname = A.aname”,执行后B表将会被修改,但是执行后B表会增加三行“0, a2005-1;0, a2005-2;0, a2006”,这也不难理解,因为Left Join执行后,B表会出现三行空值。
示例:5.1.2
Where条件查询在上面的SQL中同样可以使用,其作用的表也是Select查询出的关联表。如下SQL
- update A left join B on A.aid = B.bid
- set A.aname = B.bname
- where A.aid <> 5
执行后A表的结果:
对比第一次update可以发现,aid=5的并没有被更新。
这里只讲述left join,因为right join 和 inner join的处理过程等同于left join。另外Access中update语句中不能含有From关键字,这一点不同于其他数据库。
5.2删除
在Access中是不可以通过Left Join、Right Join、Inner Join来删除某张表的记录
示例:5.2.2
上述SQL的本意是删除A表中aid=1的记录,但执行后表A和表B均未发生任何变化。若想实现此目的,下述SQL可以实现
6、笛卡尔积
如果A表有20条记录,B表有30条记录,则二者关联后的笛卡尔积工20*30=600条记实录。也就是说A表中的每条记录都会于B表的所有记录关联一次,三种关联方式实际上就是对“笛卡尔积”的处理方式不同。
这篇关于SQL left join 左表合并去重技巧总结的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





