本文主要是介绍【itext7】使用itext7将多个PDF文件、图片合并成一个PDF文件,图片旋转、图片缩放,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这篇文章,主要介绍使用itext7将多个PDF文件、图片合并成一个PDF文件,图片旋转、图片缩放。
目录
一、itext7合并PDF
1.1、引入依赖
1.2、合并PDF介绍
1.3、采用字节数组方式读取PDF文件
1.4、合并多个PDF文件
1.5、合并图片到PDF文件
1.6、旋转图片
1.7、完整案例代码
(1)PDFUtil工具类
(2)测试类代码
(3)合并效果
一、itext7合并PDF
1.1、引入依赖
我这里使用的是itext-core7.1.16版本,只需要引入一个itext-core依赖即可,因为这个依赖里面已经给我们引入了itext所需要的依赖。
<!-- 引入 itext7-core 依赖 -->
<dependency><groupId>com.itextpdf</groupId><artifactId>itext7-core</artifactId><version>7.1.16</version><type>pom</type>
</dependency>1.2、合并PDF介绍
最简单的合并方式,那就是读取两个PDF文件,然后将其合并成一个新的PDF文件,保存到服务器上面之后,在将这个新的PDF文件和下一个待合并的PDF文件进行合并,以此类推,最终可以得到一个完整的PDF文件,但是这种方式缺点在于,每一次合并之后,都需要新生成一个PDF文件,并且下一次合并之后,还要再读取这个PDF文件,这就会导致多次读取文件的过程,效率不是很理想。
这篇文章,我主要是将PDF作为字节数组读取到内存里面,然后在内存中合并两个PDF的字节数据,这样可以减少读取和生成PDF文件的次数,执行效率方面也就会更加好一些了,合并两个PDF字节数组的方法如下所示:
/*** 基于内存中的字节数组进行PDF文档的合并* @param firstPdf 第一个PDF文档* @param secondPdf 第二个PDF文档*/
private static byte[] mergePdfBytes(byte[] firstPdf, byte[] secondPdf) throws IOException {if (firstPdf != null && secondPdf != null) {// 创建字节数组,基于内存进行合并ByteArrayOutputStream baos = new ByteArrayOutputStream();PdfDocument destDoc = new PdfDocument(new PdfWriter(baos));// 合并的pdf文件对象PdfDocument firstDoc = new PdfDocument(new PdfReader(new ByteArrayInputStream(firstPdf)));PdfDocument secondDoc = new PdfDocument(new PdfReader(new ByteArrayInputStream(secondPdf)));// 合并对象PdfMerger merger = new PdfMerger(destDoc);merger.merge(firstDoc, 1, firstDoc.getNumberOfPages());merger.merge(secondDoc, 1, secondDoc.getNumberOfPages());// 关闭文档流merger.close();firstDoc.close();secondDoc.close();destDoc.close();return baos.toByteArray();}return null;
}1.3、采用字节数组方式读取PDF文件
合并PDF文件的时候,有些PDF文件可能是网络上的,也有些是本地磁盘上的,所以这里需要做下判断,如果是网络上的PDF文件,则需要首先访问网络,再将其保存到字节数组里面,如果是本地磁盘文件,则需要读取本地文件。
/*** 将pdf文档转换成字节数组* @param pdf PDF文档路径* @return 返回对应PDF文档的字节数组*/
private static byte[] getPdfBytes(String pdf) throws Exception {ByteArrayOutputStream out = new ByteArrayOutputStream();InputStream is;if (pdf.startsWith("http://") || pdf.startsWith("https://")) {is = new URL(pdf).openStream();} else {is = new FileInputStream(pdf);}byte[] data = new byte[2048];int len;while ((len = is.read(data)) != -1) {out.write(data, 0, len);}return out.toByteArray();
}1.4、合并多个PDF文件
合并PDF时候,直接传递需要合并的PDF文件路径就可以啦,调用下面方法,就可以完成合并。
/*** 将给定List集合中的pdf文档,按照顺序依次合并,生成最终的目标PDF文档* @param pdfPathLists 待合并的PDF文档路径集合,可以是本地PDF文档,也可以是网络上的PDF文档* @param destPath 目标合并生成的PDF文档路径*/
public static boolean mergeMultiplePdfs(List<String> pdfPathLists, String destPath) {try {int size = pdfPathLists.size();byte[] pdfData = getPdfBytes(pdfPathLists.get(0));for (int i = 1; i < size; i++) {pdfData = mergePdfBytes(pdfData, getPdfBytes(pdfPathLists.get(i)));}if (pdfData != null) {FileOutputStream fis = new FileOutputStream(destPath);fis.write(pdfData);fis.close();}return true;} catch (Exception e) {logger.error("合并PDF异常:", e);}return false;
}1.5、合并图片到PDF文件
如何将图片也一起合并到PDF文件里面呢???这里我是将图片直接添加到PDF文件的空白页面中实现的,一张图片占据一个页面,当然,你也可以设置显示在相同页面,超过之后页面高度之后,图片会自动显示到下一个页面。
/*** 将给定集合中的图片合并到一个pdf文档里面* @param imagePathList 图片路径集合* @param destPath 合并之后的PDF文档*/
public static boolean mergeImagesToPdf(List<String> imagePathList, String destPath) {try {PdfDocument pdfDocument = new PdfDocument(new PdfWriter(destPath));Document document = new Document(pdfDocument);if (imagePathList != null && imagePathList.size() > 0) {int size = imagePathList.size();for (int i = 0; i < size; i++) {String imgPath = imagePathList.get(i);ImageData imageData;if (imgPath.startsWith("http://") || imgPath.startsWith("https://")) {imageData = ImageDataFactory.create(new URL(imgPath));} else {imageData = ImageDataFactory.create(imgPath);}Image image = new Image(imageData);/*设置旋转的弧度值,默认是逆时针旋转的。弧度、角度换算公式:1° = PI / 180°1 rad = 180° / PI*/image.setRotationAngle(- Math.PI / 2); // 顺时针旋转90°// 设置图片自动缩放,即:图片宽高自适应image.setAutoScale(true);document.add(image);if (i != size - 1) {// 最后一页不需要新增空白页document.add(new AreaBreak(AreaBreakType.NEXT_PAGE));}}}pdfDocument.close();return true;} catch (Exception e) {logger.error("合并图片到PDF异常:", e);}return false;
}1.6、旋转图片
在某些需求下,你可以想某个图片竖向摆放、某些图片横向摆放,那么这个时候,就可以调用itext7中【Image】图片对象的【setRotationAngle()】方法,对其进行旋转,需要注意的是:setRotationAngle方法设置的旋转弧度,而不是旋转角度,并且它是逆时针旋转的。弧度和角度之间有一个转换公式,如下所示:
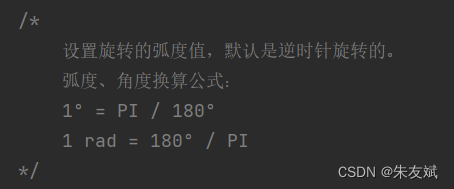
1.7、完整案例代码
(1)PDFUtil工具类
package com.gitcode.itext.util;import com.itextpdf.io.image.ImageData;
import com.itextpdf.io.image.ImageDataFactory;
import com.itextpdf.kernel.pdf.PdfDocument;
import com.itextpdf.kernel.pdf.PdfReader;
import com.itextpdf.kernel.pdf.PdfWriter;
import com.itextpdf.kernel.utils.PdfMerger;
import com.itextpdf.layout.Document;
import com.itextpdf.layout.element.AreaBreak;
import com.itextpdf.layout.element.Image;
import com.itextpdf.layout.property.AreaBreakType;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;import java.io.*;
import java.net.URL;
import java.util.List;/*** @version 1.0.0* @Date: 2023/10/04 10:07* @Author ZhuYouBin* @Description: PDF工具类【基于 itext7 组件实现】*/
public class PDFUtil {private static final Logger logger = LoggerFactory.getLogger(PDFUtil.class);/*** 将给定List集合中的pdf文档,按照顺序依次合并,生成最终的目标PDF文档* @param pdfPathLists 待合并的PDF文档路径集合,可以是本地PDF文档,也可以是网络上的PDF文档* @param destPath 目标合并生成的PDF文档路径*/public static boolean mergeMultiplePdfs(List<String> pdfPathLists, String destPath) {try {int size = pdfPathLists.size();byte[] pdfData = getPdfBytes(pdfPathLists.get(0));for (int i = 1; i < size; i++) {pdfData = mergePdfBytes(pdfData, getPdfBytes(pdfPathLists.get(i)));}if (pdfData != null) {FileOutputStream fis = new FileOutputStream(destPath);fis.write(pdfData);fis.close();}return true;} catch (Exception e) {logger.error("合并PDF异常:", e);}return false;}/*** 将给定集合中的图片合并到一个pdf文档里面* @param imagePathList 图片路径集合* @param destPath 合并之后的PDF文档*/public static boolean mergeImagesToPdf(List<String> imagePathList, String destPath) {try {PdfDocument pdfDocument = new PdfDocument(new PdfWriter(destPath));Document document = new Document(pdfDocument);if (imagePathList != null && imagePathList.size() > 0) {int size = imagePathList.size();for (int i = 0; i < size; i++) {String imgPath = imagePathList.get(i);ImageData imageData;if (imgPath.startsWith("http://") || imgPath.startsWith("https://")) {imageData = ImageDataFactory.create(new URL(imgPath));} else {imageData = ImageDataFactory.create(imgPath);}Image image = new Image(imageData);/*设置旋转的弧度值,默认是逆时针旋转的。弧度、角度换算公式:1° = PI / 180°1 rad = 180° / PI*/image.setRotationAngle(- Math.PI / 2); // 顺时针旋转90°// 设置图片自动缩放,即:图片宽高自适应image.setAutoScale(true);document.add(image);if (i != size - 1) {// 最后一页不需要新增空白页document.add(new AreaBreak(AreaBreakType.NEXT_PAGE));}}}pdfDocument.close();return true;} catch (Exception e) {logger.error("合并图片到PDF异常:", e);}return false;}/*** 基于内存中的字节数组进行PDF文档的合并* @param firstPdf 第一个PDF文档* @param secondPdf 第二个PDF文档*/private static byte[] mergePdfBytes(byte[] firstPdf, byte[] secondPdf) throws IOException {if (firstPdf != null && secondPdf != null) {// 创建字节数组,基于内存进行合并ByteArrayOutputStream baos = new ByteArrayOutputStream();PdfDocument destDoc = new PdfDocument(new PdfWriter(baos));// 合并的pdf文件对象PdfDocument firstDoc = new PdfDocument(new PdfReader(new ByteArrayInputStream(firstPdf)));PdfDocument secondDoc = new PdfDocument(new PdfReader(new ByteArrayInputStream(secondPdf)));// 合并对象PdfMerger merger = new PdfMerger(destDoc);merger.merge(firstDoc, 1, firstDoc.getNumberOfPages());merger.merge(secondDoc, 1, secondDoc.getNumberOfPages());// 关闭文档流merger.close();firstDoc.close();secondDoc.close();destDoc.close();return baos.toByteArray();}return null;}/*** 将pdf文档转换成字节数组* @param pdf PDF文档路径* @return 返回对应PDF文档的字节数组*/private static byte[] getPdfBytes(String pdf) throws Exception {ByteArrayOutputStream out = new ByteArrayOutputStream();InputStream is;if (pdf.startsWith("http://") || pdf.startsWith("https://")) {is = new URL(pdf).openStream();} else {is = new FileInputStream(pdf);}byte[] data = new byte[2048];int len;while ((len = is.read(data)) != -1) {out.write(data, 0, len);}return out.toByteArray();}
}
(2)测试类代码
package com.gitcode.itext;import com.gitcode.itext.util.PDFUtil;import java.io.FileNotFoundException;
import java.util.ArrayList;
import java.util.List;/*** @version 1.0.0* @Date: 2023/10/4 11:12* @Author ZhuYouBin* @Description:*/
public class ImageDemo {public static void main(String[] args) throws FileNotFoundException {// 图片合并之后生成的PDF路径String imagePath = "F:\\pdf-demo\\imagePath.pdf";List<String> imageList = new ArrayList<>();imageList.add("F:\\pdf-demo\\01.jpg");imageList.add("F:\\pdf-demo\\02.jpg");// 先合并图片PDFUtil.mergeImagesToPdf(imageList, imagePath);// 在合并PDFString destPath = "F:\\pdf-demo\\merge.pdf";List<String> pdfPath = new ArrayList<>();pdfPath.add("F:\\pdf-demo\\demo01.pdf");pdfPath.add("F:\\pdf-demo\\demo02.pdf");pdfPath.add(imagePath);PDFUtil.mergeMultiplePdfs(pdfPath, destPath);}
}
(3)合并效果
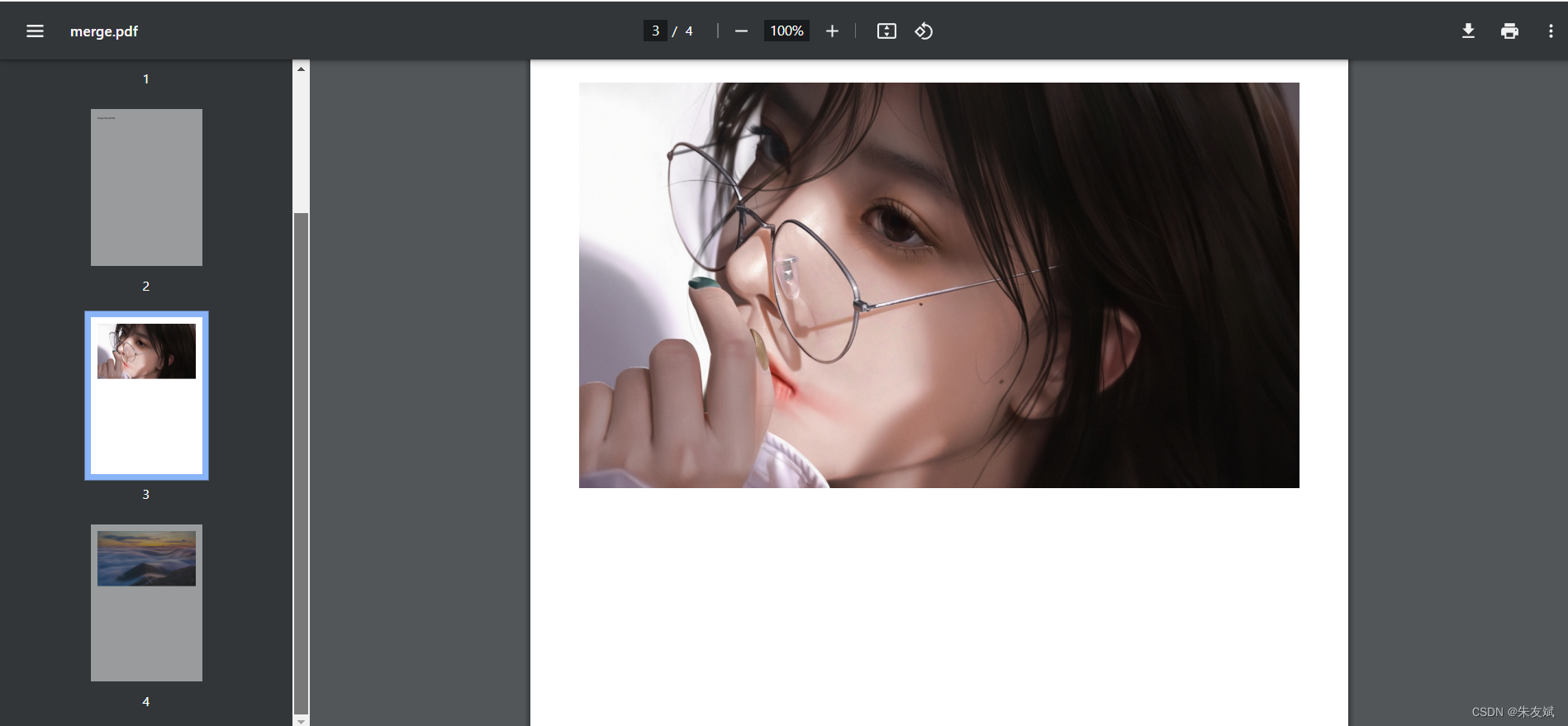
到此,itext7合并PDF文件就介绍完啦。
综上,这篇文章结束了,主要介绍使用itext7将多个PDF文件、图片合并成一个PDF文件,图片旋转、图片缩放。
这篇关于【itext7】使用itext7将多个PDF文件、图片合并成一个PDF文件,图片旋转、图片缩放的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



