本文主要是介绍Python批量读取身份证信息录入系统和重命名,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
大家好,
如果你对自动化处理身份证图片感兴趣,可以尝试以下操作:从身份证图片中快速提取信息,填入表格并提交到网页系统。如果你无法完成这个任务,我们将在“Python自动化办公2.0”课程中详细讲解实现整个过程。
实现过程概述:
模块与功能:
re 模块:用于从 OCR 识别出的文本中提取所需的信息。
日期模块:计算年龄。
pandas:处理和操作表格数据。
PaddleOCR:百度的 OCR 模块,适合中文文本识别。
concurrent.futures:实现并发处理,提高图片识别效率。请注意,CPU 性能较弱时,过多的并发可能导致识别不准确。
SimpleAutomation:封装了 Selenium 操作网页的功能,也可以直接使用 Selenium 实现网页自动化。
装饰器使用:
我们使用装饰器来分离代码逻辑,使代码更加清晰。装饰器可以用于日志记录、异常处理和函数计时等公共功能的重用。
过程安排:
批量处理:我们批量处理身份证图片,通过并发操作加快处理速度。
信息提取:利用 OCR 技术识别身份证中的文本信息,并使用正则表达式提取所需字段。
数据处理:使用 pandas 将提取的信息整理成表格。
信息提交:将处理后的数据填写到网页表单中,并提交。
这个过程涉及多个步骤和技术,代码需要经常编写和调试,以提高编程能
实现最终结果
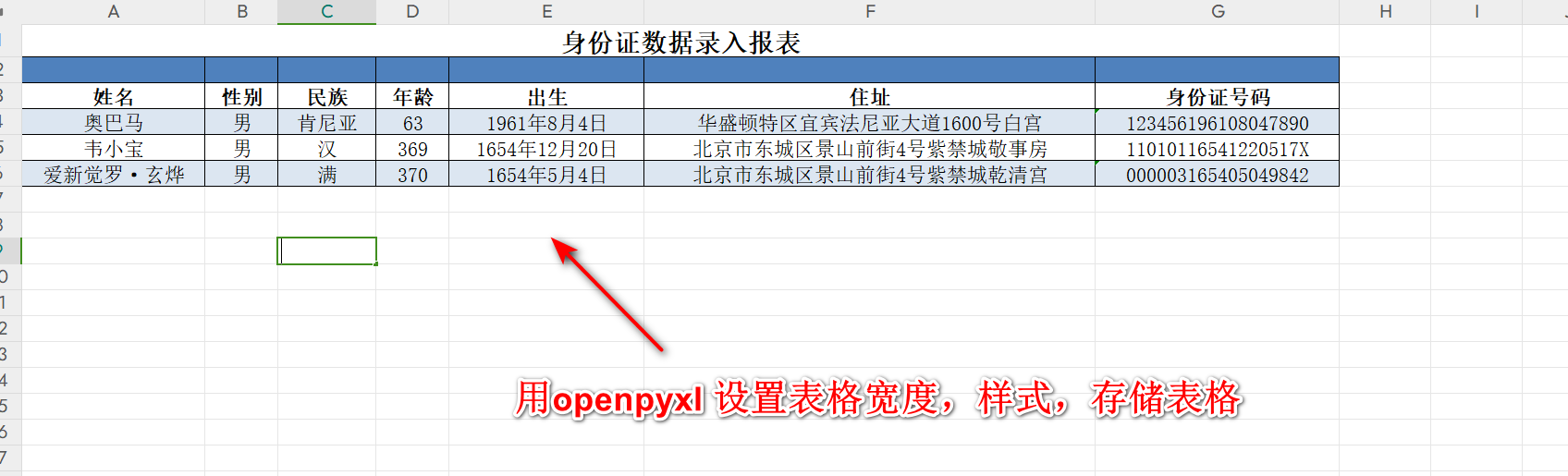
需要把下面三张身份证,识别的文字,填入到对应下面的Excel 报表中。
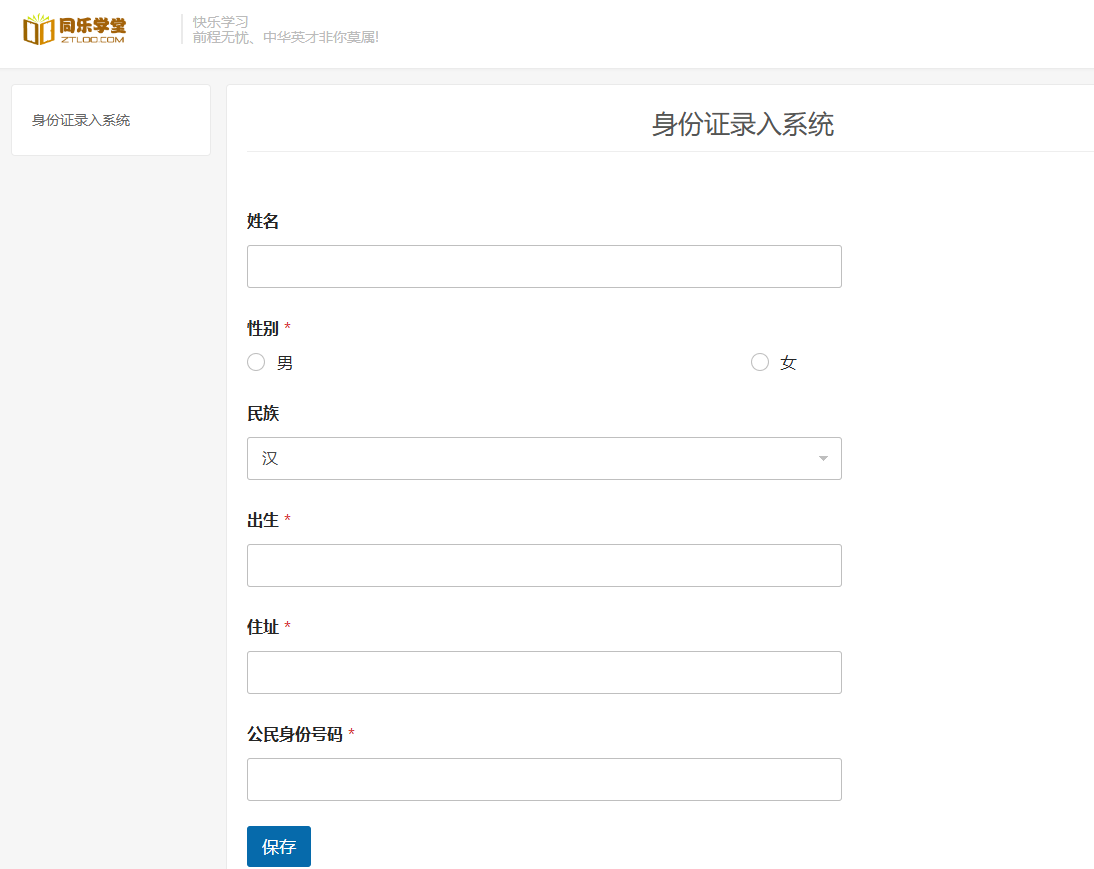
并通过https://www.ztloo.com/profile__trashed/card/ 身份证录入页面,进行web自动化填入。



1. 导入所需库
logging: 标准库日志模块,用于记录日志信息。
os: 提供操作系统接口,主要用于文件路径操作。
re: 提供正则表达式支持,用于从文本中提取信息。
shutil: 提供高级文件操作功能,例如文件复制。
time: 提供时间相关功能,如延时。
datetime: 提供日期和时间处理功能。
loguru: 现代化的日志库,用于记录日志信息。
pandas: 提供数据结构和数据分析工具,用于处理和分析数据。
paddleocr: OCR 工具,用于文本识别。
concurrent.futures: 提供并发执行任务的功能。
2. 配置日志记录
设置了日志文件 ocr_task.log,并关闭了 PaddleOCR 的日志输出,以减少冗余日志信息。
3. OCRProcessor 类
3.1 初始化
init: 初始化 PaddleOCR 引擎和数据列表。
3.2 识别文本
recognize_text: 使用 PaddleOCR 对图片进行文本识别,返回识别的文本。
3.3 提取信息
extract_info: 使用正则表达式从识别的文本中提取身份证相关信息,包括姓名、性别、民族、出生日期、住址和身份证号码。
3.4 列出图片
list_images: 列出指定目录中的所有图片文件,支持 .png、.jpg、.jpeg 格式。
3.5 处理图片
process_img: 处理单张图片,进行 OCR 识别,提取信息并将结果记录到 self.data 列表中。
3.6 处理图片目录
process_imgs: 并行处理目录中的所有图片,使用 ThreadPoolExecutor 执行任务,并将处理结果保存在 ocr_results.xlsx 文件中。调用了 add_age_and_sort 方法对数据进行排序和添加年龄列。
3.7 计算年龄
calculate_age: 根据出生日期计算年龄。
3.8 添加年龄并排序
add_age_and_sort: 为数据添加年龄列,并按年龄从小到大排序。使用 pandas 处理数据。
3.9 重命名并保存图片
rename_and_save_images: 根据提取的身份证信息重命名图片,并保存到指定目录中。
3.10 处理和提交
process_and_submit: 执行完整的处理流程,包括初始化自动化工具、批量处理图片、重命名图片、提交信息到系统。使用 SimpleAutomation 进行网页操作,填写身份证系统表单。
3.11 提交信息到系统
write_idcard_system: 将提取的信息填写到身份证系统的表单中,包括姓名、性别、出生日期、地址、身份证号码。选择性别和民族选项,提交表单。
4. 使用示例
在 main 部分,创建了 OCRProcessor 实例,并调用 process_and_submit 方法处理指定目录下的图片并提交信息到系统。
这篇关于Python批量读取身份证信息录入系统和重命名的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




