本文主要是介绍面试官:synchronized的锁升级过程是怎样的?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
大家好,我是大明哥,一个专注「死磕 Java」系列创作的硬核程序员。
回答
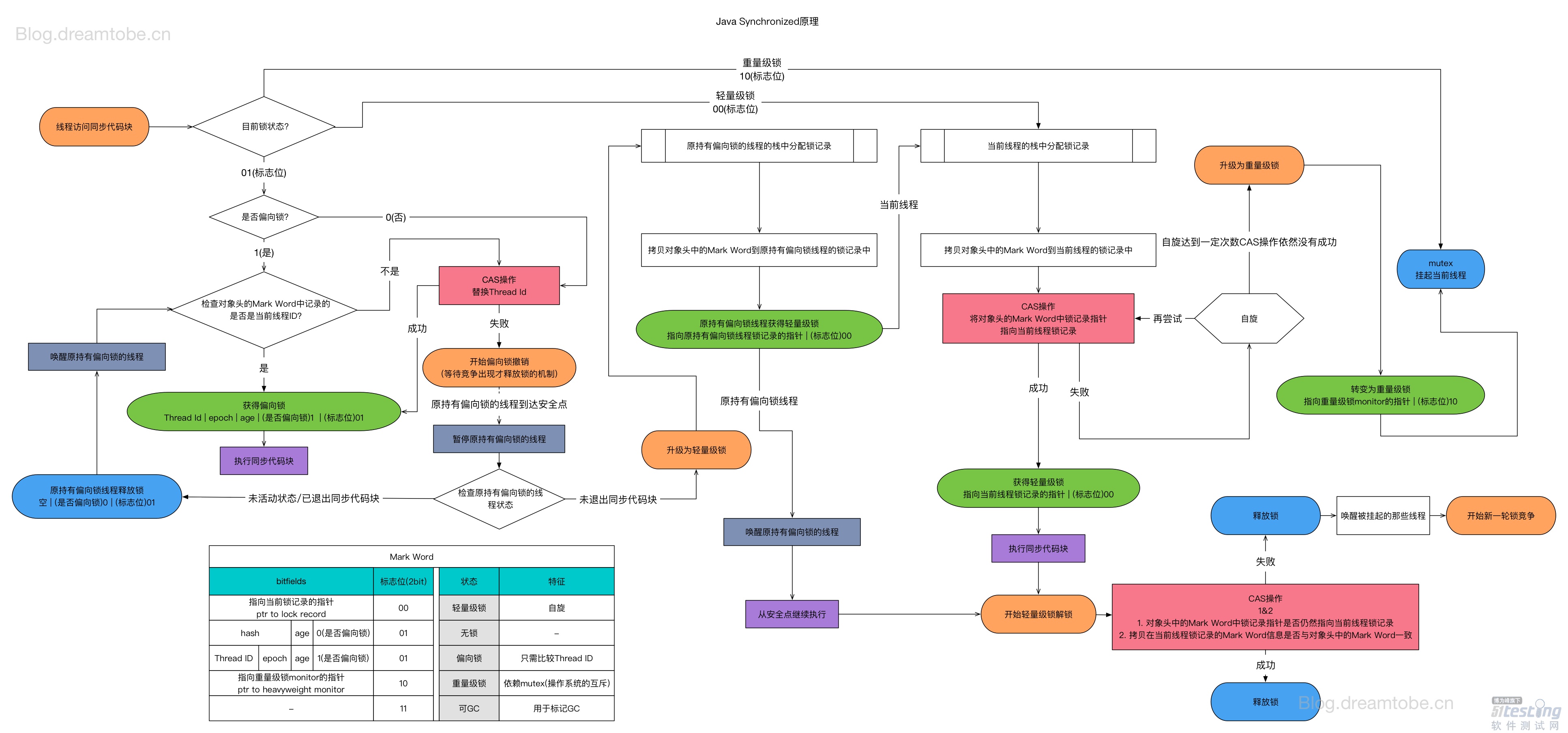
在 JDK 1.6之前,synchronized 是一个重量级、效率比较低下的锁,但是在JDK 1.6后,JVM 为了提高锁的获取与释放效,,对 synchronized 进行了优化,引入了偏向锁和轻量级锁,至此,锁的状态有四种,级别由低到高依次为:无锁、偏向锁、轻量级锁、重量级锁。
锁升级就是无锁 —> 偏向锁 —> 轻量级锁 —> 重量级锁 的一个过程,注意,锁只能升级,不能降级。
原理详解
对象头
HotSpot 虚拟机中,对象在内存中存储布局可以分为三块区域:对象头(Header)、实例数据(Instance Data)和对齐填充(Padding):

- 对象头:分为Mark Word 和 对象指针
- Mark Word:存储对象自身的运行时数据,如哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等。
- 对象指针:存储指向类元数据的指针,使得能够访问对象属于的类的信息。
- 实例数据:存储对象的实际有效信息,也就是我们在类中所定义的各种类型的字段内容。
- 对齐填充:可选字段,通常存在于对象的末尾,用于确保对象的大小是8字节的倍数(因为许多JVM都使用8字节的对象对齐)。这是出于性能考虑,使得对象的地址在内存中是对齐的。
synchronized 锁相关的信息主要是在 Mark Word 区域,我们先看看 Mark Word。
Mark Word
synchronized 用的锁存在锁对象的对象头的Mark Word中,我们先看 Mark Word 到底长什么样。

锁分类
无锁

无锁可以理解为单线程轻松愉快地运行,没有其他的线程来和其竞争。但是无锁不代表没有同步,它只是表示锁对象目前没有被任何线程显式锁定。
偏向锁
偏向锁 JDK 1.6 引入的一种锁优化机制。

何谓“偏向”?就是锁对象会偏向于第一个获得它的线程。什么意思呢。
当一个线程访问同步代码块并获取锁时,该锁会进入偏向模式,锁标志的状态将被设置为偏向(01),并且锁的拥有者被设置为当前线程(偏向锁线程 id = 当前线程 id)。当该线程执行完同步代码块后,线程并不会主动释放偏向锁。当线程再次进入同步代码块时,会首先判断此时持有锁的线程与它是否为同一线程,如果是则正常往下执行,由于此前是没有释放锁的,所以这次就不会有任何的获取锁操作。
所以,偏向锁是指当一段同步代码一直被同一个线程所访问时,就不存在所谓的多线程竞争了,那么该线程在后续访问时便会自动获得锁,从而降低获取锁带来的消耗,即提高性能。
偏向锁的锁释放是一个被动过程,线程不会主动释放偏向锁,只有当其他线程来竞争偏向锁时,JVM 才会检测到锁的状态并触发撤销。但是撤销需要等待全局安全点(所有线程会暂停),JVM 会在全局安全点时判断锁对象是否处于被锁定状态,如果没有被锁定,且持有锁的线程不处于活动状态,则将对象头设置为无锁状态,并撤销偏向锁。
所以,引入偏向锁的目的是认为当前环境下是不存在多线程竞争的场景,可以认为是单线程环境,同一个线程多次持有锁,减少单线程环境下获取锁带来的不必要。
流程图如下:

轻量级锁
当一个线程持有偏向锁时,另外一个线程来竞争锁,这时偏向锁就会升级为轻量级锁。

轻量级锁的竞争方式一种比较轻量级的竞争方式,当某个线程没有获取到锁,它并不是立刻被挂起,而是采取自旋的方式来竞争锁资源。在竞争较少的情况下,轻量级锁通过减少线程阻塞和唤醒操作,可以提高性能。
轻量级锁的目的在于它认为系统当前的竞争环境不是激烈,如果采取阻塞和唤醒线程的方式,则会过多地消耗系统资源。如果某个线程没有获取到轻量级锁,则采取自旋的方式来判断锁资源是否已被释放。这种方式减少了上线文的切换。
但是长时间的自旋操作是非常消耗资源的,一个线程获取了轻量级锁,其他线程就只能在那里“空耗”,它们不释放 CPU 资源,但也不做任何事,这种现象叫做忙等(busy-waiting)。所以,我们是允许短时间的忙等,用它来换取线程在用户态和内核态之间切换的开销。
触发轻量级锁的条件是两个:
- 关闭偏向锁(
-XX:-UseBiasedLocking) - 多个线程竞争偏向锁导致偏向锁升级为轻量级锁
流程图如下:

重量级锁
轻量级锁自旋是要有限度的,你不能一直在那里空转,所以如果锁竞争环境比较严重,当自旋次数达到某个阈值(默认 10 次,可自动调整)后,就是停止自旋,此时锁膨胀为重量级锁。当其膨胀为重量级锁后,其他线程就不再是等待了,而是阻塞等待。重量级锁依赖对象内部的监视器(monitor)实现,而 monitor 依赖的是操作系统的 MutexLock(互斥锁)。
由于是重量级锁,那么等待锁资源的线程都会被阻塞,虽然阻塞的线程不会消耗 CPU,但是阻塞或者唤醒一个线程都需要通过底层操作系统来实现,它会涉及到上下文切换,用户态和内核态之间的转换,这本身就是一个非常重量级、高开销的操作。

锁升级过程
锁升级就是无锁 —> 偏向锁 —> 轻量级锁 —> 重量级锁 的一个过程,注意,锁只能升级,不能降级。流程图如下:

- JVM 启动后,锁资源对象直到有第一个线程访问时,它都是无锁状态,此时 Mark Word 内容如下:

偏向锁标识为 0,锁标识为 01。
- 当锁对象首次被某个线程(假如为线程 A,id 为
1000001)时,锁就会从无锁状态升级偏向锁。偏向锁会在 Mark Word 中的偏向锁线程 id 存储当前线程的id(1000001),偏向锁标识为 1,锁标识为 01,如下:

如果当前线程再次获取该锁对象,只需要比较偏向锁线程 id 即可。
- 当有其他线程(假如为线程 B,id 为
1000002)来竞争该锁对象,此时锁为偏向锁,这个时候会比较偏向锁的线程 id 是否为线程 B1000002,我们可以判断不是,所以会利用 CAS 尝试修改 Mark Word,如果成功,则线程 B 获取偏向锁成功,此时 Mark Word 中的偏向锁线程 id 为线程 B id1000002:

- 但如果失败了,就说明当前环境可能存在锁竞争,则需要执行偏向锁撤销操作。等到全局安全点时,JVM 会暂停持有偏向锁的线程 A,检查线程 A 的状态,若线程 A状态为不活跃或者已经执行完了同步代码块,则设置锁对象为无锁状态(线程 ID 为空,偏向锁 0 ,锁标志位为01)重新偏向,同时恢复线程 A,继续获取偏向锁。如果线程 A 的同步代码块还没执行完,则需要升级为轻量级锁。
- 在升级为轻量级锁之前,持有偏向锁的线程 A是暂停的,JVM 首先会在线程 A 的栈中创建一个名为锁记录的空间(
Lock Record),用于存放锁对象目前的 Mark Word 的拷贝,然后拷贝对象头中的 Mark Word 到线程 A 的锁记录中(官方称之为 Displaced Mark Word ),若拷贝成功,JVM 将使用 CAS 尝试将对象头重的 Mark Word 更新为指向线程 A 的Lock Record的指针,成功,线程 A 获取轻量级锁,此时 Mark Word 的锁标志位为 00,指向锁记录的指针指向线程 A 的锁记录地址,如下图:

- 对于其他线程而言,也会在栈帧中建立锁记录,存储锁对象目前的 Mark Word 的拷贝。也利用 CAS 尝试将锁对象的 Mark Word 更正指向自身线程的 Lock Record,如果成功,表明竞争到轻量级锁,则执行同步代码块。如果失败,那么线程尝试使用自旋的方式来等待持有轻量级锁的线程释放锁。当然,它不会一直自旋下去,因为自旋的过程也会消耗 CPU,而是自旋一定的次数,如果自旋了一定次数后还是失败,则升级为重量级锁,阻塞所有未获取锁的线程,等待释放锁后唤醒。
最后是,锁升级过程的详细流程(此图来源于网上):
本文已收录到我的技术网站:https://www.skjava.com。有全网最优质的系列文章、Java 全栈技术文档以及大厂完整面经
这篇关于面试官:synchronized的锁升级过程是怎样的?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







