本文主要是介绍【python PDF合并】python 合并同一个文件夹下所有PDF文件,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、需求说明
下载了网易云课堂的吴恩达免费的深度学习的pdf文档,但是每一节是一个pdf,我把这些PDF文档放在一个文件夹下,希望合并成一个PDF文件。于是写了一个python程序,很好的解决了这个问题。
二、数据形式
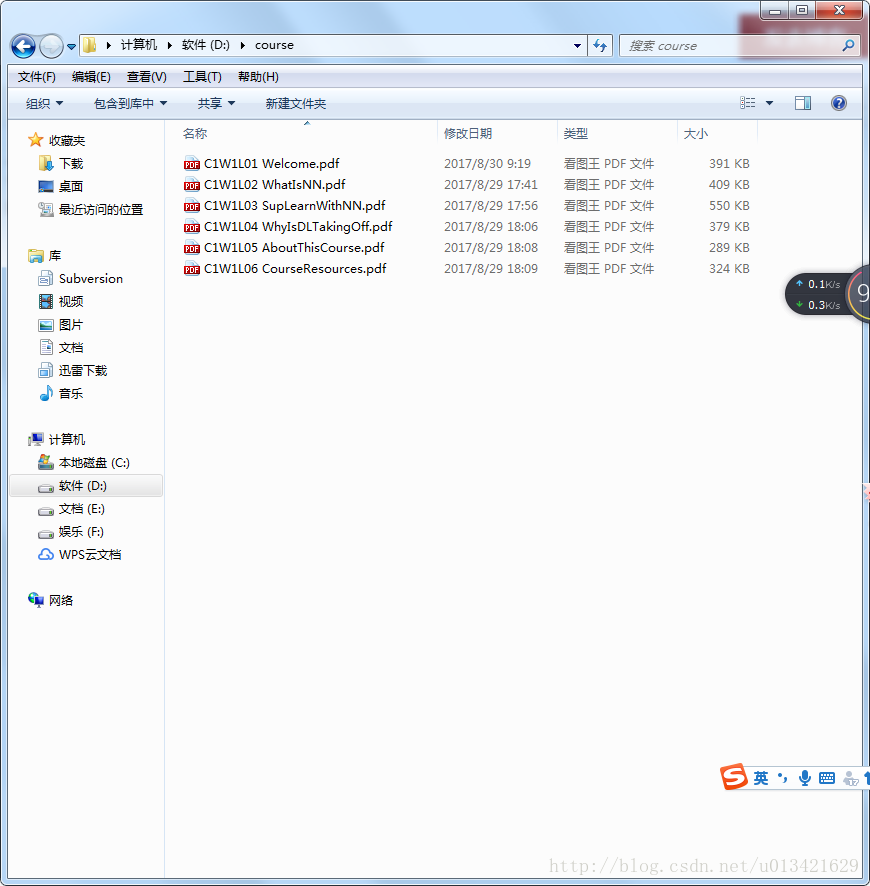
三、合并效果
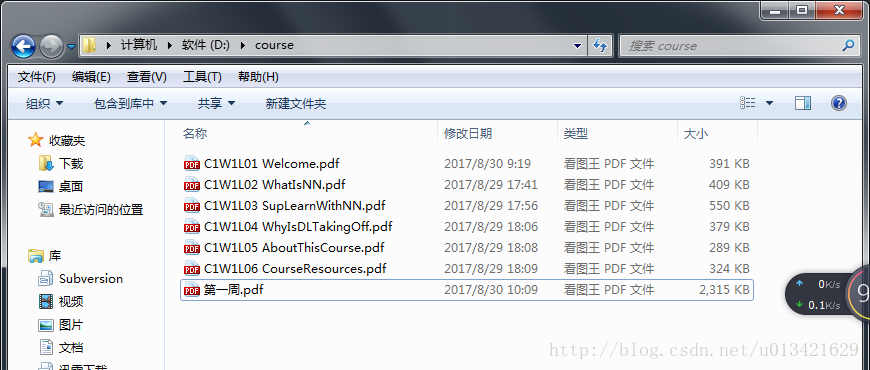
四、python代码实现
# -*- coding:utf-8*-
import sys
reload(sys)
sys.setdefaultencoding('utf-8')import os
import os.path
from pyPdf import PdfFileReader,PdfFileWriter
import time
time1=time.time()# 使用os模块walk函数,搜索出某目录下的全部pdf文件
######################获取同一个文件夹下的所有PDF文件名#######################
def getFileName(filepath):file_list = []for root,dirs,files in os.walk(filepath):for filespath in files:# print(os.path.join(root,filespath))file_list.append(os.path.join(root,filespath))return file_list##########################合并同一个文件夹下所有PDF文件########################
def MergePDF(filepath,outfile):output=PdfFileWriter()outputPages=0pdf_fileName=getFileName(filepath)for each in pdf_fileName:print each# 读取源pdf文件input = PdfFileReader(file(each, "rb"))# 如果pdf文件已经加密,必须首先解密才能使用pyPdfif input.isEncrypted == True:input.decrypt("map")# 获得源pdf文件中页面总数pageCount = input.getNumPages()outputPages += pageCountprint pageCount# 分别将page添加到输出output中for iPage in range(0, pageCount):output.addPage(input.getPage(iPage))print "All Pages Number:"+str(outputPages)# 最后写pdf文件outputStream=file(filepath+outfile,"wb")output.write(outputStream)outputStream.close()print "finished"if __name__ == '__main__':file_dir = r'D:/course/'out=u"第一周.pdf"MergePDF(file_dir,out)time2 = time.time()print u'总共耗时:' + str(time2 - time1) + 's'"D:\Program Files\Python27\python.exe" D:/PycharmProjects/learn2017/合并多个PDF文件.py
D:/course/C1W1L01 Welcome.pdf
3
D:/course/C1W1L02 WhatIsNN.pdf
4
D:/course/C1W1L03 SupLearnWithNN.pdf
4
D:/course/C1W1L04 WhyIsDLTakingOff.pdf
3
D:/course/C1W1L05 AboutThisCourse.pdf
3
D:/course/C1W1L06 CourseResources.pdf
3
All Pages Number:20
finished
总共耗时:0.128000020981sProcess finished with exit code 0这篇关于【python PDF合并】python 合并同一个文件夹下所有PDF文件的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





