本文主要是介绍2024高教社杯全国大学生数学建模竞赛C题原创python代码,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
2024高教社杯全国大学生数学建模竞赛C题原创python代码
C题题目:农作物的种植策略
思路可以参考我主页之前的文章
以下均为python代码,推荐用anaconda中的notebook当作编译环境
from gurobipy import Model
import pandas as pd
import gurobipy as gp
from gurobipy import GRB
import numpy as np# 读取execl数据
data1 = pd.read_excel('附件1-乡村现有耕地和农作物的基本情况.xlsx')
data2 = pd.read_excel('附件2-2023 年乡村农作物种植和相关统计数据.xlsx')
# 读取execl数据的表2
data11 = pd.read_excel('附件1-乡村现有耕地和农作物的基本情况.xlsx',sheet_name='乡村种植的农作物')
data22 = pd.read_excel('附件2-2023 年乡村农作物种植和相关统计数据.xlsx',sheet_name='2023年统计的相关数据')
# 显示前十个数据
data1.head(10)
# 地块数据
land_data = {"地块名称":['A1', 'A2', 'A3', 'A4', 'A5', 'A6', 'B1', 'B2', 'B3', 'B4', 'B5', 'B6', 'B7', 'B8', 'B9', 'B10', 'B11', 'B12', 'B13', 'B14', 'C1', 'C2', 'C3', 'C4', 'C5', 'C6', 'D1', 'D2', 'D3', 'D4', 'D5', 'D6', 'D7', 'D8', 'E1', 'E2', 'E3', 'E4', 'E5', 'E6', 'E7', 'E8', 'E9', 'E10', 'E11', 'E12', 'E13', 'E14', 'E15', 'E16', 'F1', 'F2', 'F3', 'F4'],"地块类型":["平旱地"]*6 + ["梯田"]*14 + ["山坡地"]*6 + ["水浇地"]*8 + ["普通大棚"]*16 + ["智慧大棚"]*4,
}
land_df = pd.DataFrame(land_data)
# 在land_df中添加地块面积data1['地块面积/亩']
land_df['地块面积/亩'] = data1['地块面积/亩']
land_df# 作物数据
# 从data11中获取作物名称和作物编号作为crop_data
crop_data = {"作物名称":data11['作物名称'],"作物编号":data11['作物编号'],"作物类型":data11['作物类型']
}
crop_df = pd.DataFrame(crop_data)
crop_df
# 创建地块名称的列表
land = data1['地块名称'].tolist()
# 创建地块面积的列表
area = data1['地块面积/亩'].tolist()
# 创建作物名称的列表,去重
crop = list(set(data2['作物名称'].tolist()))# 根据作物名称设计一个字典,key是作物名称,value是data11中作物编号和作物种类和种植耕地的列表
crop_dict = {}
for i in range(len(data11)):crop_dict[data11['作物名称'][i]] = [data11['作物编号'][i],data11['作物类型'][i],data11['种植耕地'][i]]
# 显示crop_dict
print(crop_dict)
data24 = pd.read_excel('附件2-2023 年乡村农作物种植和相关统计数据.xlsx', sheet_name='2023的农作物种植情况汇总')
data24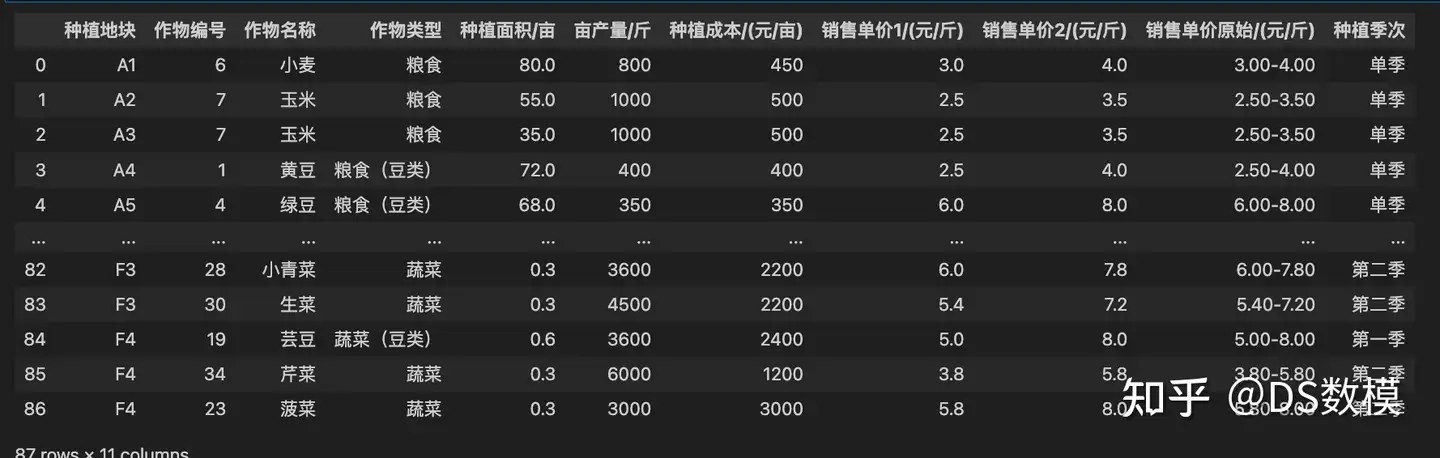
# data24的销售单价1和销售单价2取平均值,作为销售单价
data24['销售单价'] = (data24['销售单价1/(元/斤)']+data24['销售单价2/(元/斤)'])/2# 将作物名称作为索引,销售单价作为值,创建一个字典
price_dict = data24.set_index('作物名称')['销售单价'].to_dict()
# 将作物名称作为索引,种植成本/(元/亩)作为值,创建一个字典
cost_dict = data24.set_index('作物名称')['种植成本/(元/亩)'].to_dict()
# 将作物名称作为索引,亩产量/斤作为值,创建一个字典
yield_dict = data24.set_index('作物名称')['亩产量/斤'].to_dict()
# 将地块名称作为索引,地块面积/亩作为值,创建一个字典
area_dict = data1.set_index('地块名称')['地块面积/亩'].to_dict()# 创建模型
model = gp.Model("crop_optimization")# 定义决策变量
crop_fields = ['A1', 'A2', 'A3', 'A4', 'A5', 'A6', 'B1', 'B2', 'B3', 'B4', 'B5', 'B6', 'B7', 'B8', 'B9', 'B10', 'B11', 'B12', 'B13', 'B14', 'C1', 'C2', 'C3', 'C4', 'C5', 'C6', 'D1', 'D2', 'D3', 'D4', 'D5', 'D6', 'D7', 'D8', 'E1', 'E2', 'E3', 'E4', 'E5', 'E6', 'E7', 'E8', 'E9', 'E10', 'E11', 'E12', 'E13', 'E14', 'E15', 'E16', 'F1', 'F2', 'F3', 'F4']
crops = ['黄豆', '黑豆', '红豆', '绿豆', '爬豆', '小麦', '玉米', '谷子', '高粱', '黍子', '荞麦', '南瓜', '红薯', '莜麦', '大麦', '水稻', '豇豆', '刀豆', '芸豆', '土豆', '西红柿', '茄子', '菠菜', '青椒', '菜花', '包菜', '油麦菜', '小青菜', '黄瓜', '生菜', '辣椒', '空心菜', '黄心菜', '芹菜', '大白菜', '白萝卜', '红萝卜', '榆黄菇', '香菇', '白灵菇', '羊肚菌']
seasons = ['第一季', '第二季']
x = model.addVars(crop_fields, crops, seasons, vtype=GRB.INTEGER, name="x")# 目标函数:最大化总收益
revenue = price_dict
cost = cost_dict
# 地块面积字典(单位:亩)
field_area = area_dict
# 亩产量字典(单位:斤/亩)
yield_per_mu = yield_dict# 目标函数:最大化总收益
model.setObjective(gp.quicksum(revenue[crop] * x[field, crop, season] * yield_per_mu[crop] - cost[crop] * x[field, crop, season] for field in crop_fields for crop in crops for season in seasons), GRB.MAXIMIZE)以上仅为部分。其中更详细的思路、各题目思路、代码、讲解视频、成品论文及其他相关内容,可以点击下方名片哦:
这篇关于2024高教社杯全国大学生数学建模竞赛C题原创python代码的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





