本文主要是介绍清华MEM作业-利用管理运筹学的分析工具slover求解最优解的实现 及 通过使用文件或者套节字来识别进程的fuser命令,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、清华MEM作业-利用管理运筹学的分析工具slover求解最优解的实现
最近又接触了一些线性求解的问题,以前主要都是在高中数学里接触到,都是使用笔算,最后通过一些函数式得出最小或者最大值,最近的研究生学业上接触到了一个Excel solver分析工具,对这种线性求最优解的问题感觉使用起来真是得心应手。在使用这个工具前,EXCEL里需要先装上solver工具,装起来很也简单,网上搜一下。
另外就是需要知道SUMPRODUCT这个函数的使用,SUMPRODUCT是SUM方法的提升版,可以实现将两个长度相同的数组,每个对应的成员相乘最后求和,比如实现一个数组是含有3种水果的价格数组,一个是这三种水果各买多少斤的数组,SUMPRODUCT就可以实现一次性计算这三样水果总共需要付多少钱。
solver适合题目:给定一些条件求最优解或者极值等。接下来我们就看一下下面这个线性规划的题目。关于某咨询公司对一些有孩子无孩子白天晚上的调查问题,题目截图如下:

不同家庭不同时间的调查费用如下表所示:
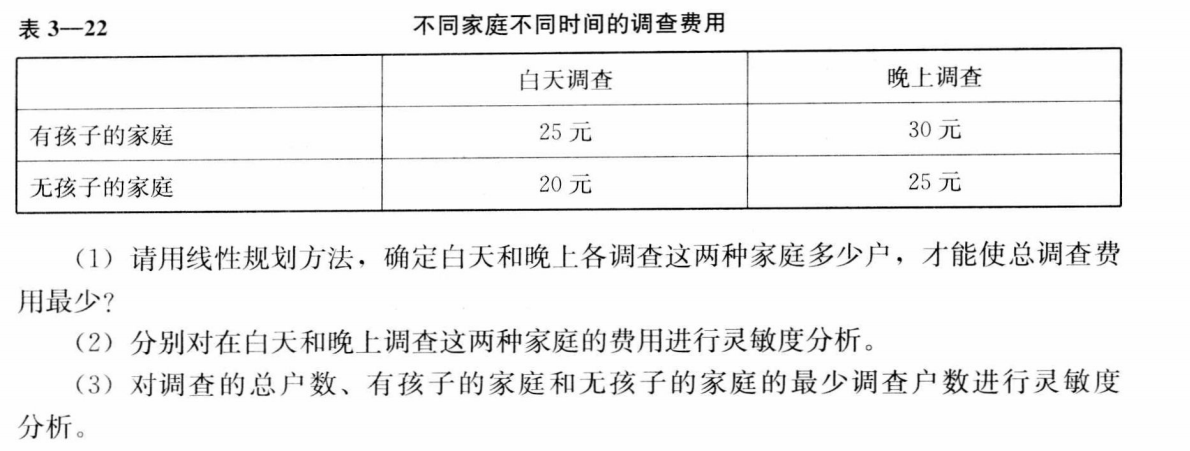
使用solver求解前,我们需要将这些数据罗列显示在EXCEL上并对一些数据进行计算。EXCEL上的数据显示图以及功能函数图如下:
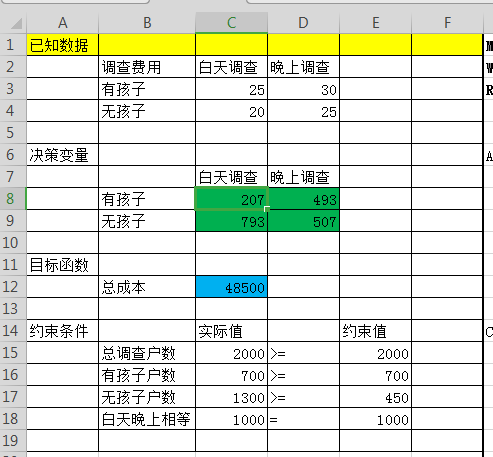
函数显示如下:
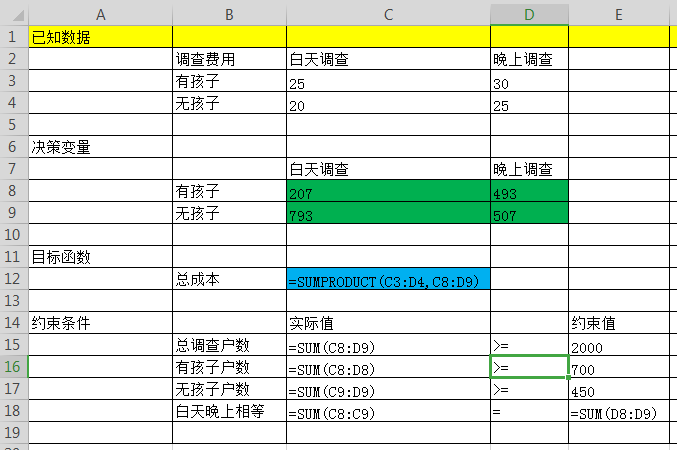
绿色背景的数据是我们要求的最优解,蓝色的是我们的目标值,使这个成本最小。这些数据和公式到位后,我们就可以使用Solver进行规划求解,设定求解目标,设定变量和约束条件进行求解。绿色背景中就会自动计算出最优值出来,非常方便。我这里不方便截图,只留一个简单的笔记在这里。最优解计算出来之后,还可以进行敏感度分析,可以分析出各个因素的数据进行的变动对结果的影响。如下:
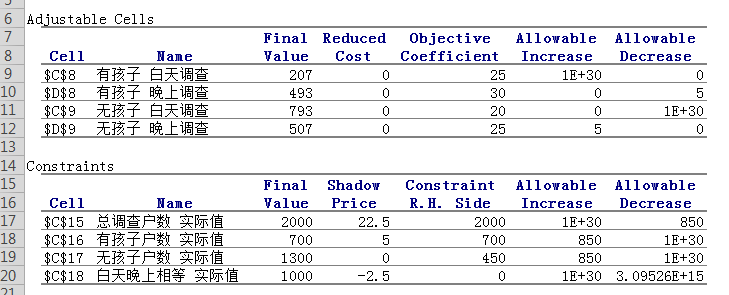
备注: 此为一次清华MEM作业,在此作个记录而已。
二、通过使用文件或者套节字来识别进程的fuser命令
fuser的作用是通过使用文件或者套节字来表示识别进程,fuser可以直接通过可执行文件或者pid文件查找到所有在使用它的进程,甚至还可以通过指定端口号查看哪些进程在占用。如下使用实例:
[hello@007 ~]# fuser /usr/local/nginx/sbin/nginx
/usr/local/nginx/sbin/nginx: 9661e 18128e 18129e
#通过上面得到的进程ID查看进程
[hello@007 ~]# ps -ef | grep -E '9661|18128|18129'
root 9661 1 0 Mar20 ? 00:00:00 nginx: master process /usr/local/nginx/sbin/nginx
www 18128 9661 0 Jun15 ? 01:16:23 nginx: worker process
www 18129 9661 0 Jun15 ? 01:18:36 nginx: worker process
root 19193 18035 0 12:06 pts/0 00:00:00 grep --color -E 9661|18128|18129
[hello@007 ~]# fuser /opt/modules/coreseek4.1/var/searchd_mysql.pid
/opt/modules/coreseek4.1/var/searchd_mysql.pid: 1920
#查看端口被哪些进程ID占用
[hello@007 ~]# fuser -n tcp 80
80/tcp: 9661 18128 18129
[hello@007 ~]# fuser .
.: 18035c 18749cfuser的参数是文件,但可以是文件名也可以是TCP、UDP端口号。上面的执行过程中可以看到通过nginx可执行文件识别进程时,后面还有e字符,而在使用fuser .识别进程时其后面带有c字符(显示当前几个终端登录将此作为工作目录),这些c/e之类的字符的意义是标志字符,每个进程号后面都跟随一个字母,该字母指示进程如何使用文件,其可有以下种类:
c:指示进程的工作目录。
e:指示该文件为进程的可执行文件(即进程由该文件拉起)。
f:指示该文件被进程打开,默认情况下f字符不显示。
F:指示该文件被进程打开进行写入,默认情况下F字符不显示。
r:指示该目录为进程的根目录。
m:指示进程使用该文件进行内存映射,抑或该文件为共享库文件,被进程映射进内存。
fuser可以在找到使用该文件的进程后,批量杀死这些进程,可以应用于有很多进程使用到了该文件,可以通过fuser一次杀掉所有进程,而不需要一个一个去kill。使用如下:
fuser -k -x -u -c 文件参数 或 fuser -kxuc 文件参数fuser命令可参数意义如下:
Show which processes use the named files, sockets, or filesystems.
-a display unused files too 显示命令行中指定的所有文件
-c mounted FS
-f silently ignored (for POSIX compatibility)
-i ask before killing (ignored without -k) 杀死进程前需要用户进行确认
-k kill processes accessing the named file 杀死访问指定文件的所有进程
-l list available signal names 列出所有已知信号名
-m show all processes using the named filesystems 指定一个被加载的文件系统或一个被加载的块设备
-n SPACE search in this name space (file, udp, or tcp) 选择不同的名称空间
-s silent operation
-SIGNAL send this signal instead of SIGKILL
-u display user IDs 在每个进程后显示所属的用户名
-v verbose output
-V display version information
-4 search IPv4 sockets only
-6 search IPv6 sockets only
- reset options
这篇关于清华MEM作业-利用管理运筹学的分析工具slover求解最优解的实现 及 通过使用文件或者套节字来识别进程的fuser命令的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







