本文主要是介绍[置顶]论如何优雅的处理回文串 - 回文自动机详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
写在前面
最近无意中看到了这个数据结构,顺便也就学习了一下。
而且发现网上关于这个算法的描述有很多地方是错的,在这里做了一些更正。
处理字符串的算法很多:
KMP,E-KMP,AC自动机,后缀三兄弟:后缀树、后缀数组、后缀自动机,Trie树、Trie图,符串hash...
但以上数据结构在处理回文串上还是稍有欠缺,用这些来处理回文显得太小题大做。
于是有了Manacher算法,代码短、容易理解、时间O(n)、无需考虑奇偶回文情况,很完美的算法!
当然这篇博客的重点不在Manacher算法,有关Manacher算法请点击这里!
Manacher算法可以在O(n)时间内处理出S串每个位置的最长回文串,但如果要统计S串中有多少回文串,
或者S串的所有子串的回文串的个数,这时就要用到一种和Manacher一样优雅的数据结构:回文自动机。
What Is Palindromic auto-machine?
回文自动机,又叫回文树,是由俄罗斯人 MikhailRubinchik于2014年夏发明的,参看链接。
这是一种比较新的数据结构,在原文中已有详细介绍与代码实现。
回文树其实不是严格的树形结构,因为它有是两棵树,分别是偶数长度的回文树和奇数长度的回文树,树中每个节点代表一个回文串。
为了方便,第一棵树的根是一个长度为0的串,第二棵就是为-1的串,不要感到奇怪,就是-1。
可以证明,最多只有n个结点(n是串的长度)。这个可以用Manacher算法来证明。
如果某结点代表的是串ccabacc,那么它的父亲代表的串就是去掉前后两个字符cabac。
每个点还有一个fail指针,表示这个串的后缀中最长的回文串,比如babab的fail指向bab,bab的指向b。
方法的思想和KMP,AC自动机很类似,如果你理解了KMP与AC自动机,那么这个算法基本可以一看就懂。
数据说明
- len[i]:节点i的回文串的长度
- next[i][c]:节点i的回文串在两边添加字符c以后变成的回文串的编号(和字典树的next指针类似)
- fail[i]:类似于AC自动机的fail指针,指向失配后需要跳转到的节点
- cnt[i]:节点i表示的回文串在S中出现的次数(建树时求出的不是完全的,count()加上子节点以后才是正确的)
- num[i]:以节点i回文串的末尾字符结尾的但不包含本条路径上的回文串的数目。(也就是fail指针路径的深度)
- last:指向最新添加的回文结点
- S[i]表示第i次添加的字符
- p表示添加的节点个数
How To Build Palindromic auto-machine?
假设现在我们有串S='abbaabba'。
首先我们添加第一个字符'a',S[++ n] = 'a',然后判断此时S[n-len[last]-1]是否等于S[n]
即上一个串-1的位置和新添加的位置是否相同,相同则说明构成回文,否则,last=fail[last]。
此时last=0,我们发现S[1-0-1]!=S[1],所以last=fail[last]=1,
然后我们发现S[1-(-1)-1]==S[1](即自己等于自己,所以我们让len[1]等于-1可以让这一步更加方便)。
令cur等于此时的last(即cur=last=1),判断此时next[cur]['a']是否已经有后继,
如果next[cur]['a']没有后继,我们就进行如下的步骤:
新建节点(节点数p++,且之后p=3),并让now等于新节点的编号(now=2),
则len[now]=len[cur]+2(每一个回文串的长度总是在其最长子回文串的基础上在两边加上两个相同的字符构成的,所以是+2,
同时体现出我们让len[1]=-1的优势,一个字符自成一个奇回文串时回文串的长度为(-1)+2=1)。
然后我们让fail[now]=next[get_fail ( fail[cur] )]['a'],即得到fail[now](此时为fail[2] = 0),
其中的get_fail函数就是让找到第一个使得S[n-len[last]-1]==S[n]的last。然后next[cur]['a'] = now。
当上面步骤完成后我们让last = next[cur][c](不管next[cur]['a']是否有后继),然后cnt[last] ++。
此时回文树为下图状态:
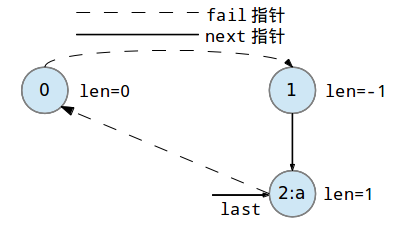

现在我们添加第二个字符字符'b'到回文树中:
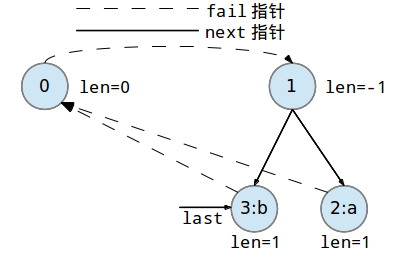

继续添加第三个字符'b'到回文树中:
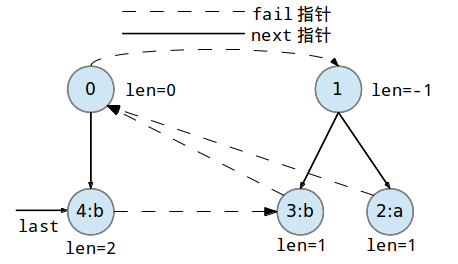

继续添加第四个字符'a'到回文树中:
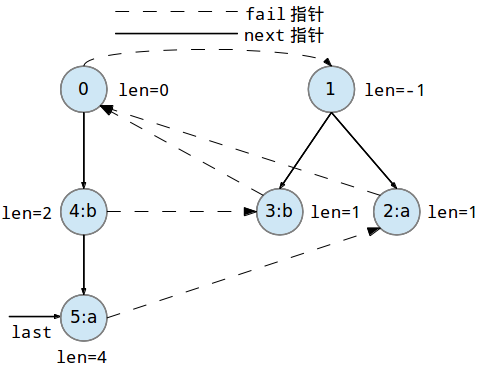

继续添加第五个字符'a'到回文树中:
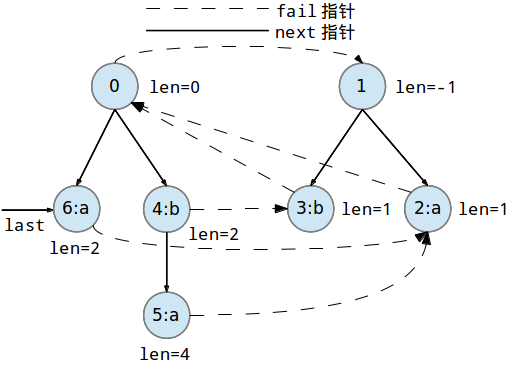

继续添加第六个字符'b'到回文树中:
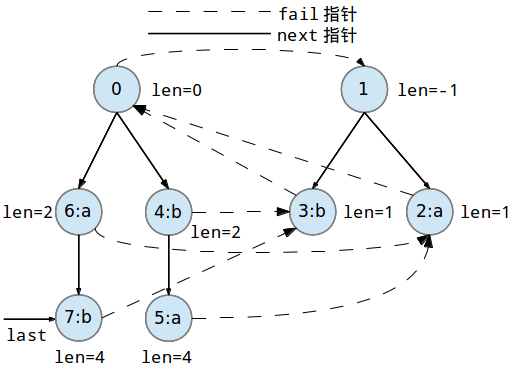

继续添加第七个字符'b'到回文树中:
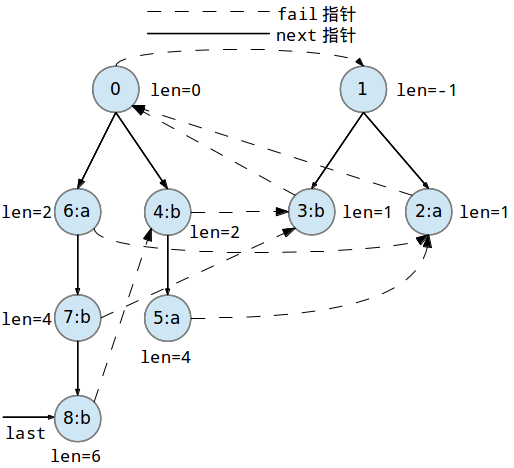

继续添加第八个字符'a'到回文树中:
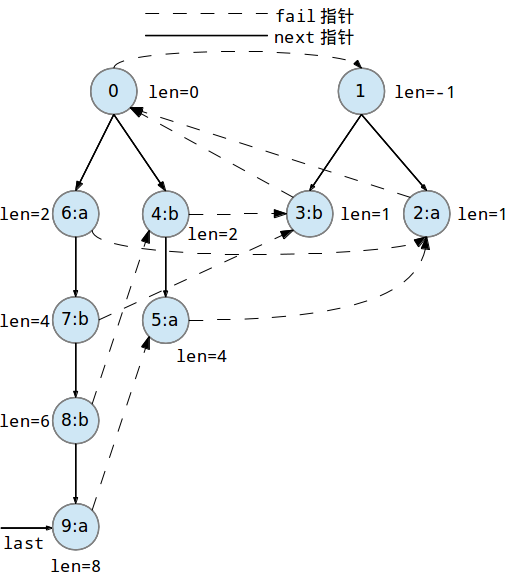

到此,串S已经完全插入到回文树中了,现在所有的数据如下:
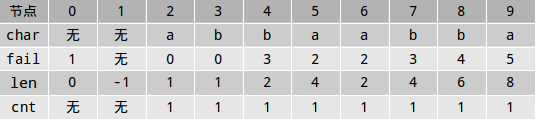
然后我们将节点x在fail指针树中将自己的cnt累加给父亲,从叶子开始倒着加,最后就能得到串S中出现的每一个本质不同回文串的个数。
构造回文树需要的空间复杂度为O(N*字符集大小),时间复杂度为O(N*log(字符集大小)),这个时间复杂度比较神奇。如果空间需求太大,可以改成邻接表的形式存储,不过相应的要牺牲一些时间。
The Use Of Palindromic auto-machine
- 求串S前缀0~i内本质不同回文串的个数(两个串长度不同或者长度相同且至少有一个字符不同便是本质不同)
- 求串S内每一个本质不同回文串出现的次数
- 求串S内回文串的个数(其实就是1和2结合起来)
- 求以下标i结尾的回文串的个数
some problem
- 2014-2015 ACM-ICPC, Asia Xian Regional Contest G The Problem to Slow Down You
- ural1960. Palindromes and Super Abilities
- WHU1583 Palindrome
- Подпалиндромы
Template
/* * this code is made by crazyacking * Verdict: Accepted * Submission Date: 2015-08-19-21.48 * Time: 0MS * Memory: 137KB */ #include <queue> #include <cstdio> #include <set> #include <string> #include <stack> #include <cmath> #include <climits> #include <map> #include <cstdlib> #include <iostream> #include <vector> #include <algorithm> #include <cstring> #define LL long long #define ULL unsigned long long using namespace std; const int MAXN = 100005 ; const int N = 26 ; char s[MAXN]; struct Palindromic_Tree { int next[MAXN][N] ;//next指针,next指针和字典树类似,指向的串为当前串两端加上同一个字符构成 int fail[MAXN] ;//fail指针,失配后跳转到fail指针指向的节点 int cnt[MAXN] ; int num[MAXN] ; // 当前节点通过fail指针到达0节点或1节点的步数(fail指针的深度) int len[MAXN] ;//len[i]表示节点i表示的回文串的长度 int S[MAXN] ;//存放添加的字符 int last ;//指向上一个字符所在的节点,方便下一次add int n ;//字符数组指针 int p ;//节点指针 int newnode(int l) //新建节点 { for(int i = 0 ; i < N ; ++ i) next[p][i] = 0 ; cnt[p] = 0 ; num[p] = 0 ; len[p] = l ; return p ++ ; } void init() //初始化 { p = 0 ; newnode(0) ; newnode(-1) ; last = 0 ; n = 0 ; S[n] = -1 ;//开头放一个字符集中没有的字符,减少特判 fail[0] = 1 ; } int get_fail(int x) //和KMP一样,失配后找一个尽量最长的 { while(S[n - len[x] - 1] != S[n]) x = fail[x] ; return x ; } void add(int c,int pos) { printf("%d:",p); c -= 'a'; S[++ n] = c ; int cur = get_fail(last) ; //通过上一个回文串找这个回文串的匹配位置 printf("%d ",cur); if(!next[cur][c]) //如果这个回文串没有出现过,说明出现了一个新的本质不同的回文串 { int now = newnode(len[cur] + 2) ; //新建节点 fail[now] = next[get_fail(fail[cur])][c] ; //和AC自动机一样建立fail指针,以便失配后跳转 next[cur][c] = now ; num[now] = num[fail[now]] + 1 ; for(int i=pos-len[now]+1; i<=pos; ++i) printf("%c",s[i]); } last = next[cur][c] ; cnt[last] ++ ; putchar(10); } void count() { for(int i = p - 1 ; i >= 0 ; -- i) cnt[fail[i]] += cnt[i] ; //父亲累加儿子的cnt,因为如果fail[v]=u,则u一定是v的子回文串! } } run; int main() { scanf("%s",&s); int n=strlen(s); run.init(); for(int i=0; i<n; i++) run.add(s[i],i); run.count(); return 0; }
这篇关于[置顶]论如何优雅的处理回文串 - 回文自动机详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




