本文主要是介绍Python获取百度文库VIP内容,无需付费轻松下载,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
今天就教大家如何实现百度文库VIP内容获取
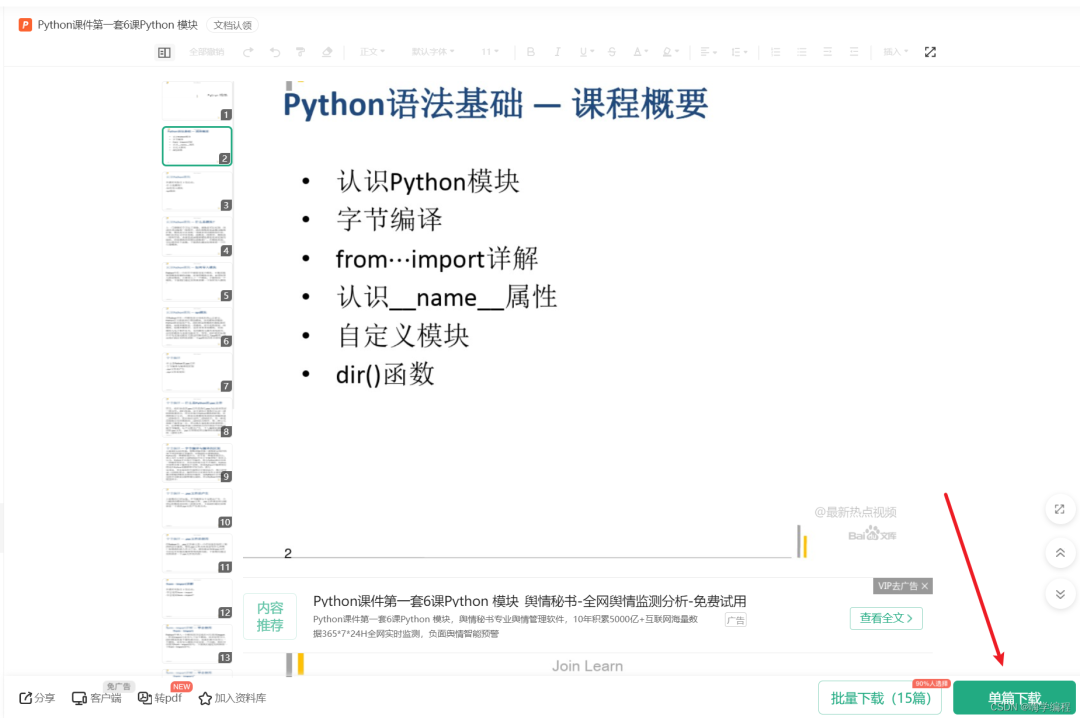
💥需求如下
对于这类的文档, 我们想要点击下载, 都是需要 “氪金” 才行, 但是作为咱们这类人来说, 能白嫖就白嫖!
💥找数据源
通过开发者工具抓包, 可以看到数据都是图片的形式存在, 那我们可以获取它所有的数据内容, 然后保存下载下来, 以PPT的形式保存
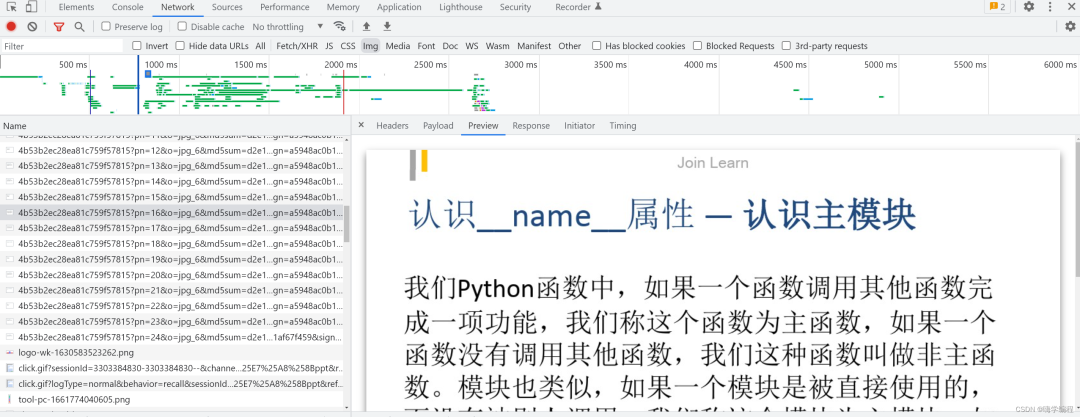
💥代码如下
import os
import requests
from lxml import etree
from selenium import webdriver
from selenium.webdriver.chrome.options import Options# 创建谷歌浏览器对象
options = Options()
options.add_argument('--headless')
driver = webdriver.Chrome(options=options)# 打开对应的网页
driver.get('https://wenku.baidu.com/view/d830930fa32d7375a417804f?aggId=d36bdfc0d5bbfd0a795673b5&fr=catalogMain_text_ernie_recall_backup_new%3Awk_recommend_main2&_wkts_=1718454979967&wkQuery=%E5%BA%94%E5%B1%8A%E6%AF%95%E4%B8%9A%E7%94%9F%E9%9D%A2%E8%AF%95%E9%97%AE%E9%A2%98&needWelcomeRecommand=1')# 获取html数据
html_text = driver.page_source
html = etree.HTML(html_text)# 筛选PPT图片链接
url_list = html.xpath('//div[@id="reader-thumb"]/div/img/@src')
# print(url_list)# 在同级目录下创建文件夹images, 用来保存拿到的图片
if not os.path.exists('百度文库'):os.makedirs('百度文库')# 定义计数变量,用于给图片命名
count = 1for url in url_list:# 请求每页PPT的图片response = requests.get(url)# 将获取的图片保存到本地with open(f'./百度文库/第{count}页.jpg', 'wb') as f:# 写入本地f.write(response.content)print(f'第{count}页下载成功')count += 1百度文库爬虫源码已经打包好了,朋友们如果需要可以威x信扫描下方二维码免费获得【保证100%免费】

💥采集效果
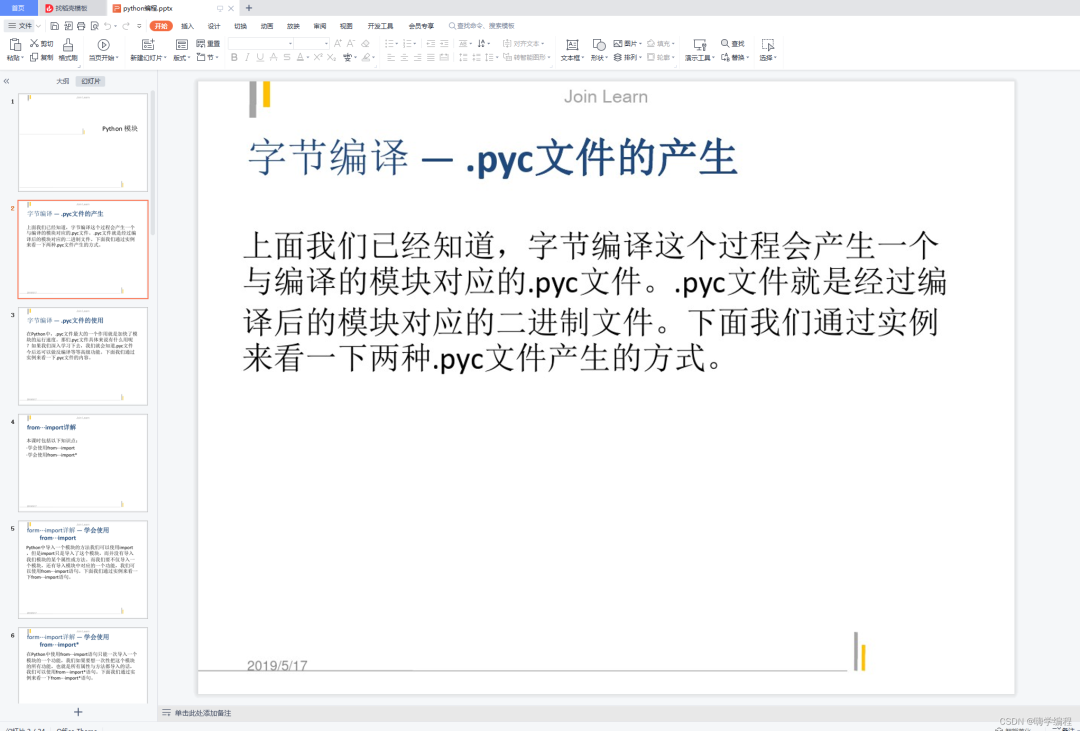
如果你是准备学习Python或者正在学习(想通过Python兼职),下面这些你应该能用得上:
【点击这里】领取!
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、自动化办公等学习教程。带你从零基础系统性的学好Python!
① Python所有方向的学习路线图,清楚各个方向要学什么东西
② 100多节Python课程视频,涵盖必备基础、爬虫和数据分析
③ 100多个Python实战案例,学习不再是只会理论
④华为出品独家Python漫画教程 ,手机也能学习
⑤ 历年互联网企业Python面试真题,复习时非常方便
————————————————

这篇关于Python获取百度文库VIP内容,无需付费轻松下载的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





