本文主要是介绍iLogtail 开源两周年:社区使用调查报告,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者:玄飏
iLogtail 作为阿里云开源的可观测数据采集器,以其高效、灵活和可扩展的特性,在可观测采集、处理与分析领域受到了广泛的关注与应用。在 iLogtail 两周年之际,我们对 iLogtail 开源社区进行了一次使用调研,旨在深化理解用户初次接触与采纳 iLogtail 的最佳路径,同时为促进社区生态繁荣,确保输出内容的高质量与高度相关性提供数据支撑。
尽管收集到的有效问卷数量可能未达到传统统计显著性的门槛,但这批反馈却异常宝贵,为我们的策略制定与优化提供了第一手的洞察力。这些见解不仅直接源自实际应用场景,还蕴含了用户对于提升 iLogtail 功能体验、文档丰富度及社区互动多样性的真切期待,为后续的社区建设与发展指明了方向。
关键要点
- 51.85% 的使用者已经将开源版 iLogtail 用于灰度或大规模生产环境,22.22% 的使用者的部署规模超过 1000 台。
- 绝大部分开源版 iLogtail 使用者,在容器化场景中部署 iLogtail(85.19%),其中 81.48% 使用 Kubernetes, 18.52% 使用 Docker。
- 66.67% 的受访者有参与社区开发的意愿。 在有开发意愿的受访者中,实际参与过开发的占 40%,85% 的受访者表示完善文档有助于他们进行开发,55% 的受访者认为社区需要及时更新开发需求。
- 40% 的受访者留下了联系方式,并愿意通过文章、开发者会议等方式分享使用 iLogtail 的案例、场景,在此向他们致谢。
详细分析
社区眼中的开源版 iLogtail
本次调查,有 90% 的受访者正在使用 iLogtail。
调研结果显示,大多数用户是通过官方渠道,如宣传文章和公众号,首次接触到 iLogtail,这不仅体现了官方宣传的有效性,也反映了高质量技术内容对于开源项目推广的重要性。

高性能、容器化友好以及丰富的插件生态成为用户采纳 iLogtail 的关键驱动力,凸显了项目设计之初便紧密贴合现代 IT 架构需求的前瞻性。

尽管用户对 iLogtail 的性能与稳定性给予高度评价,但对文档质量的反馈也明确指出,加强文档的详实性和易用性是当前社区发展的关键一环。

开源版 iLogtail 的使用情况
使用 iLogtail 的受访者们,分享了他们的使用场景。
容器化技术,尤其是 Kubernetes 的广泛应用,成为 iLogtail 部署的主流场景,占比高达 81.48%,反映了 iLogtail 在云原生环境下的高度适配能力。

所有主机/服务器/虚拟机环境的开源 iLogtail 使用者,均在 Linux 环境部署了 iLogtail,同时也有部分用户在 Windows 环境下部署 iLogtail。
而 Kubernetes 场景的使用者,绝大部分都选择使用 Daemonset 方式部署 iLogtail:

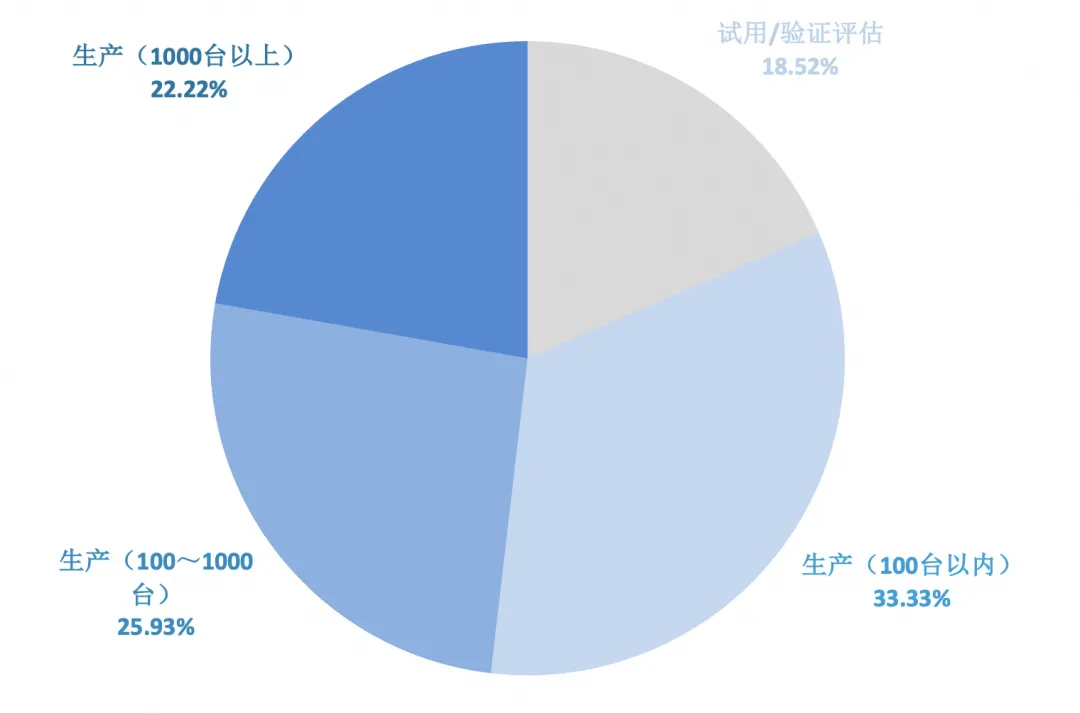
大半使用者所在的组织将 iLogtail 应用到生产环境,更是有 22.22% 的使用者的 iLogtail 部署规模达到了 1000+ 台。
我们也统计了开发者对 iLogtail 插件的使用情况。受访者最常使用的处理流水线插件排名前三的是:
- input 插件:
-
- 采集文本日志(file_log/input_file),70.37%
- 采集容器标准输出(service_docker_stdout/input_container_stdio),48.15%
- 消费 kafka 数据(service_kafka),48.15%
- processor 插件:
-
- json 解析(processor_json),59.26%
- 正则解析(processor_regex),59.26%
- 添加字段(processor_add_fields),44.44%
- flusher 插件:
-
- kafka 输出(flusher_kafka/flusher_kafka_v2),74.07%
- 标准输出(flusher_stdout),25.93%
- ES 输出(flusher_elasticsearch),25.93%
我们发现,在数据输入场景,文件与容器的标准输出扮演着不可或缺的基础角色,作为历经时间验证的数据源,其核心价值不容忽视。Kafka 作为数据流处理领域的中坚力量,日益凸显其重要性,成为数据摄入的首选工具,这一趋势不仅彰显了实时数据消费模式的飞速发展,亦反映了市场对此类解决方案的广泛接纳与信赖。
在数据解析的维度上,正则表达式与 JSON 解析是经久不衰的常青树,是数据解析最坚实的底座。在此基础上,自定义字段功能,包括但不限于字段的动态增删等精细化操作,它们的价值逐渐凸显,越来越多的开发者在使用、开发相关的功能。
谈及数据的最终归宿与应用输出,大家愈发倾向于将数据流导向那些历经市场验证、稳定性与效率并重的日志管理平台及顶级消息队列服务,诸如阿里云 SLS、Elasticsearch 与业界领先的消息中间件 Kafka 等,这些平台以其强大的数据处理与集成能力,确保了数据价值的最大化利用与洞察的即时性。相对地,使用 http、grpc、otlp 协议消费数据的配置就少很多,可能是因为这些方式需要自建消费端,没有直接使用成熟的方案来得快捷稳定。
另外,我们惊喜地发现有部分开发者已经在尝试使用新推出的 SPL 处理功能,期待更多来自社区的反馈。
ConfigServer 欢迎大家使用
ConfigServer 是 iLogtail 社区为开源开发者提供的简单 iLogtail 采集配置管控工具。
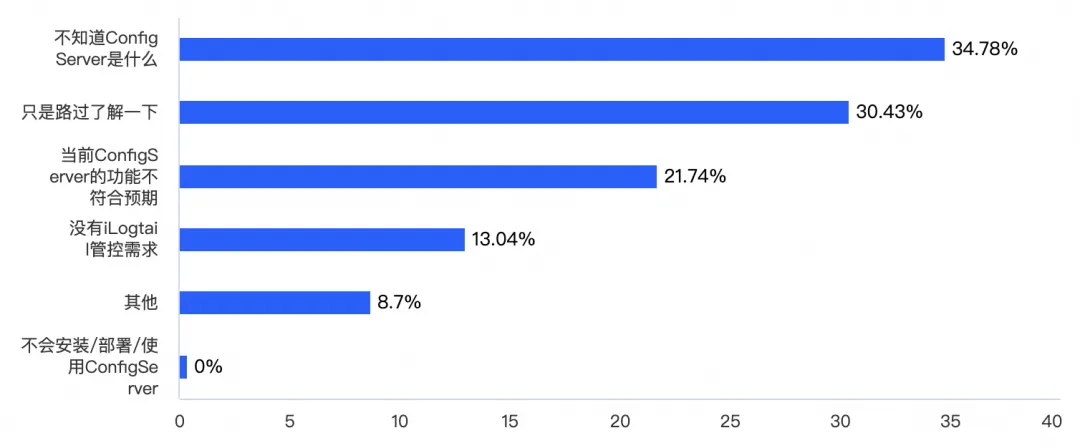
在本次调查中,我们发现大半受访者(76.67%)没有使用过管控工具 ConfigServer。没有使用过 ConfigServer 的受访者中,65.21% 不了解或不知道 ConfigServer 是什么,其余 21.74% 认为 ConfigServer 的功能不符合预期,13.04% 没有管控需求,8.7% 是自建平台管控 iLogtail 的采集配置。
在使用过 ConfigServer 的受访者中,57.14% 对 ConfigServer 做了自定义改造。使用者们对 ConfigServer 的功能需求最大,其次是 UI 界面和配置管控。ConfigServer 会在这个夏天进行一次升级,届时欢迎大家使用全新版本。

诚挚邀请各位参与 iLogtail 社区的开发
我们很高兴地发现,有 66.67% 的受访者表示有意愿参与社区的开发,这一高比例体现了 iLogtail 社区的活力及用户的参与热情。
然而,“不知道如何开发”(75%)与“不清楚开发方向”(33.33%)成为了阻碍用户参与的主要障碍,这要求社区不仅要优化文档资源,还需要建立更加透明和动态的开发需求沟通机制。我们将致力于减少这类问题的发生,将文档中的开发指南进一步细化、完善,并增加一些开发样例,让每一个开发者都能快速上手 iLogtail 的开发。
此外,受访者对于完善文档、增加实用教程的呼声,再次强调了高质量文档对降低技术门槛、激发开发兴趣的关键作用。有开发意愿的受访者们一致认为,完善的文档(85%)和社区及时更新开发需求(55%)有助于他们进行开发工作。我们这一方面也在努力,后续我们会推出开源社区的全新官网,重点解决当前 Gitbook 连接不稳定,文档、活动、需求等杂糅在一起,界面不够美观、重点不够突出等问题,也会定期在新官网上同步社区的需求。

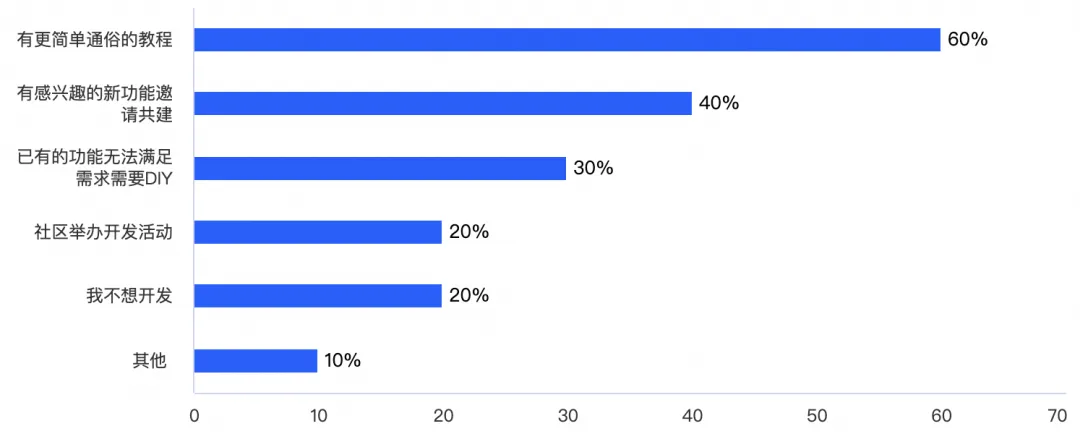
而部分没有开发意愿的受访者们,大部分认为简单通俗的教程有助于激发他们的开发兴趣。
总结
iLogtail 作为一款高效、灵活的可观测数据采集器,不仅在容器化部署中展现出卓越的性能与兼容性,也在不断增长的用户需求中发现了改进空间。在 iLogtail 开源两周年之后,我们的品牌即将升级为 LoongCollector,这是一段全新的旅程。新的旅程中,面对开源社区用户的期待与挑战,我们将会:
- 持续强化对外输出体系:
- 搭建新官网,更新社区动态与需求
- 优化开发文档,持续补充开发样例
- ……
- 提升插件生态的丰富度与灵活性:
- 关注用户更感兴趣的方向,提供更多功能性插件
- 优化高频使用插件的性能,推出部分高频使用插件的 C++ 版本
- ……
- 优化配置管理工具:
- 提供开箱即用的版本
- 优化前端展示
- 增加监控与告警功能
- ……
- ……
我们将以更开放的姿态邀请开发者共同塑造项目的未来。我们有理由相信,升级后的 LoongCollector 将在可观测领域扮演更加重要的角色,引领技术创新与社区共建的新篇章。
这篇关于iLogtail 开源两周年:社区使用调查报告的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






