本文主要是介绍基于纠错码的哈希函数构造方案,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、前言
随着大数据时代的到来,交通数据量急剧增加,由此带来的交通安全问题日益凸显。传统的驾驶人信用管理系统在数据存储和管理上存在着诸多不足之处,例如中心化存储方案无法有效地进行信用存证及数据溯源。区块链技术以其去中心化和不可篡改的特性,在数据存储和管理方面展现出了巨大的潜力。区块链的固有特性也带来了另一个挑战——一旦数据被写入区块链,几乎不可能对其进行修改,这在某些情况下是不利的。为了解决这一问题,当前文章重点研究了如何构建具有高随机性的哈希算法——高度随机哈希函数(HRHF)。HRHF算法通过结合纠错码与SM3算法的Merkle-Damgård迭代结构,不仅增强了哈希值的随机性,还保证了算法的安全性和执行效率。实验结果显示,与经典的SHA-256算法相比,HRHF算法在多个关键指标上均有显著提升。
HRHF算法结合了纠错码与SM3算法的Merkle-Damgård迭代结构,通过这种方式增强了哈希值的随机性。选用了纠错能力更强的线性分组码与SM3算法相结合,并构造生成哈希值具有更强随机性的哈希函数。实验结果显示该算法不仅具有理想的雪崩效应特性,而且攻击者更难以逆推出原始消息,从而具备了更高的算法安全性。
二、算法设计原理
2.1 算法的创新点
(1)通过调整循环左移位数来进一步提升哈希值的随机性;
(2)通过优化迭代结构来提高算法的执行效率。
算法的具体使用流程:
- 初始化状态向量,为生成256位哈希值准备。
- 计算纠错码的生成矩阵。
- 对生成矩阵进行循环左移操作以增加随机性。
- 对输入数据进行迭代压缩操作。
- 输出最终的256位哈希值。
2.2 实现代码(C++)
#include <iostream>
#include <vector>
#include <cstdint>
#include <cassert>// 哈希值长度
constexpr size_t HASH_LENGTH = 32; // 256 bits// 线性分组码参数
constexpr size_t CODE_LENGTH = 32; // 码长
constexpr size_t CODE_DIMENSION = 6; // 维度// 生成矩阵初始化
std::vector<std::vector<uint32_t>> generateMatrix() {// 实际应用中需要通过算法计算得到std::vector<std::vector<uint32_t>> matrix(CODE_DIMENSION, std::vector<uint32_t>(CODE_LENGTH));// 示例矩阵for (size_t i = 0; i < CODE_DIMENSION; ++i) {matrix[i][i] = 1;}return matrix;
}// 生成码字
std::vector<uint32_t> generateCodeWord(const std::vector<std::vector<uint32_t>>& matrix) {std::vector<uint32_t> codeWord(CODE_LENGTH);// 假设这里使用生成矩阵生成码字for (size_t i = 0; i < CODE_LENGTH; ++i) {codeWord[i] = 0; // 初始化码字for (size_t j = 0; j < CODE_DIMENSION; ++j) {// 模2加法codeWord[i] ^= matrix[j][i];}}return codeWord;
}// 循环左移
uint32_t rotateLeft(uint32_t value, int shift) {return (value << shift) | (value >> (32 - shift));
}// 消息预处理
std::vector<uint32_t> preprocessMessage(const std::vector<uint8_t>& message) {// 添加消息长度,这里简化处理std::vector<uint8_t> extendedMessage = message;extendedMessage.push_back(0x80); // 添加结束标志extendedMessage.insert(extendedMessage.end(), 8, 0x00); // 添加长度占位符// 将消息转换为32位整数数组std::vector<uint32_t> words;for (size_t i = 0; i < extendedMessage.size(); i += 4) {uint32_t word = 0;for (size_t j = 0; j < 4 && i + j < extendedMessage.size(); ++j) {word |= static_cast<uint32_t>(extendedMessage[i + j]) << (24 - 8 * j);}words.push_back(word);}return words;
}// 消息扩展
void extendMessage(std::vector<uint32_t>& words) {const size_t WORD_COUNT = 64; // 扩展后的字数量while (words.size() < WORD_COUNT) {uint32_t w = words.back();uint32_t w16 = words[words.size() - 16];words.push_back(w16 ^ rotateLeft(w16, 9) ^ rotateLeft(w16, 17) ^rotateLeft(w, 15) ^ rotateLeft(w, 23));}
}// 布尔函数
uint32_t ff(uint32_t x, uint32_t y, uint32_t z, size_t j) {if (j >= 16 && j <= 63) {return x ^ y ^ z;}else {return (x & y) | ((~x) & z);}
}// 布尔函数
uint32_t gg(uint32_t x, uint32_t y, uint32_t z, size_t j) {if (j >= 16 && j <= 63) {return x ^ y ^ z;}else {return (x & y) | (x & z) | (y & z);}
}// 压缩函数
void compress(std::vector<uint32_t>& state, const std::vector<uint32_t>& words) {const size_t ROUND_COUNT = 64; // 迭代次数const size_t STATE_SIZE = 8; // 状态寄存器大小const uint32_t T[ROUND_COUNT] = { /* 常量表 */ };std::vector<uint32_t> ss1(STATE_SIZE), ss2(STATE_SIZE), tt1(STATE_SIZE), tt2(STATE_SIZE);for (size_t i = 0; i < ROUND_COUNT; ++i) {// 中间变量更新ss1[i] = rotateLeft(state[0], 7) + rotateLeft(state[4], 12);ss2[i] = ss1[i] ^ rotateLeft(state[0], 12);tt1[i] = ff(state[0], state[1], state[2], i) + state[3] + ss2[i] + words[i];tt2[i] = gg(state[4], state[5], state[6], i) + state[7] + ss1[i] + words[i + 64];// 状态寄存器更新state[0] = state[1];state[1] = state[2];state[2] = state[3];state[3] = tt1[i];state[4] = state[5];state[5] = state[6];state[6] = state[7];state[7] = tt2[i];}
}// 主算法
std::vector<uint8_t> hrhf(const std::vector<uint8_t>& message) {std::vector<uint32_t> state(HASH_LENGTH / 4, 0); // 初始化寄存器std::vector<std::vector<uint32_t>> matrix = generateMatrix();std::vector<uint32_t> codeWord = generateCodeWord(matrix);// 循环左移操作以增加随机性for (size_t i = 0; i < CODE_DIMENSION; ++i) {codeWord[i] = rotateLeft(codeWord[i], 6); // 循环左移6位}// 将码字分配给初始寄存器for (size_t i = 0; i < HASH_LENGTH / 4; ++i) {state[i] = codeWord[i % CODE_DIMENSION];}// 消息预处理std::vector<uint32_t> words = preprocessMessage(message);// 打印预处理后的消息std::cout << "Preprocessed Message: ";for (const auto& word : words) {std::cout << word << " ";}std::cout << std::endl;// 消息扩展extendMessage(words);// 打印扩展后的消息std::cout << "Extended Message: ";for (const auto& word : words) {std::cout << word << " ";}std::cout << std::endl;// 迭代压缩compress(state, words);// 将32位整数转换为256位哈希值std::vector<uint8_t> hash(HASH_LENGTH);for (size_t i = 0; i < HASH_LENGTH / 4; ++i) {uint32_t word = state[i];for (size_t j = 0; j < 4; ++j) {hash[i * 4 + j] = word >> (24 - 8 * j);}}return hash;
}int main() {std::vector<uint8_t> message = { 'q', 'y', 'x' };std::vector<uint8_t> hash = hrhf(message);std::cout << "Hash Value: ";for (auto b : hash) {printf("%02x", b);}std::cout << std::endl;return 0;
}
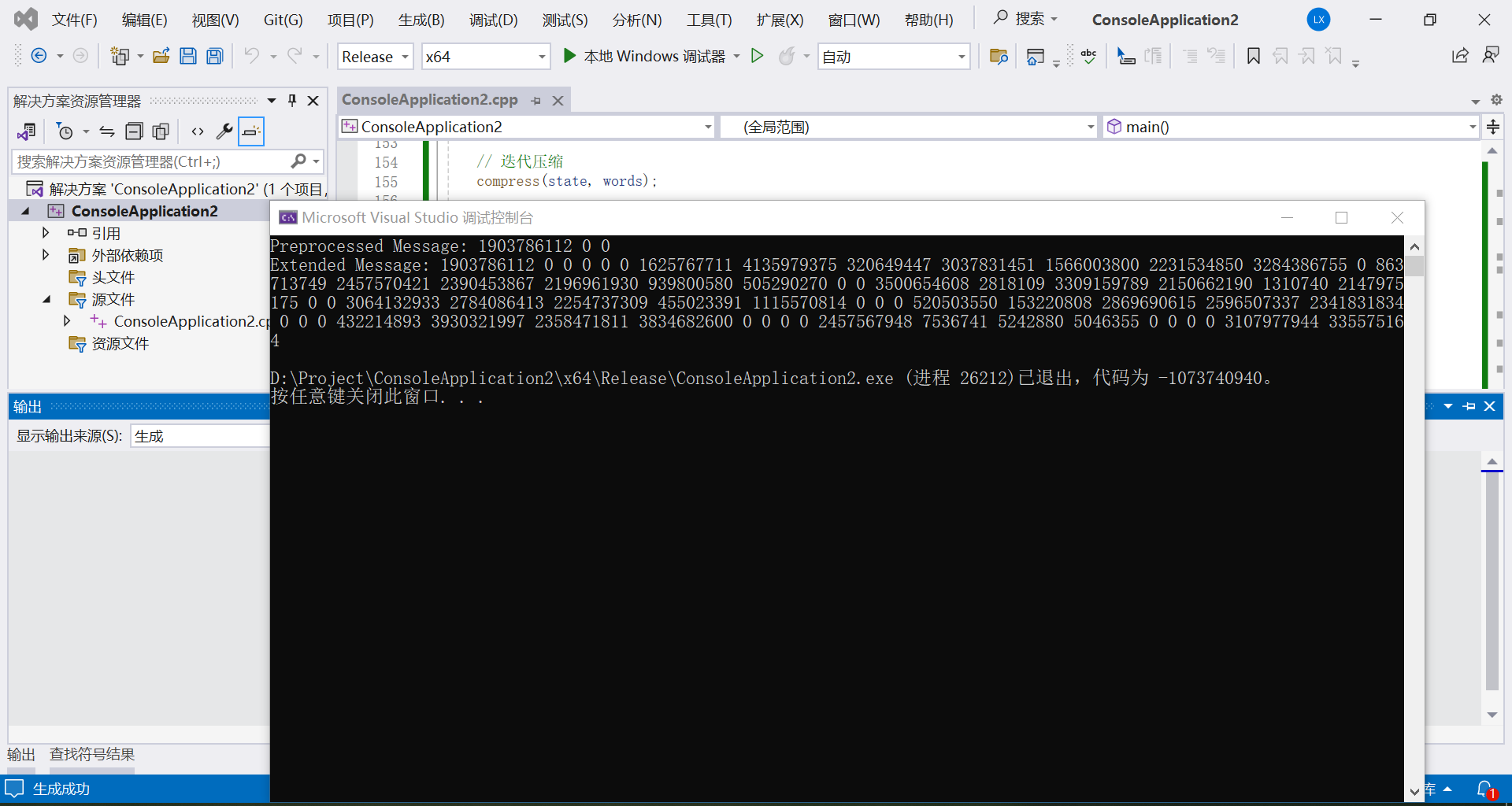
运行结果:
2.3 创新部分
(1)循环左移位数的优化: 通过调整循环左移位数可以进一步提升哈希值的随机性。实验结果显示,在循环左移6位时,信息熵数值最高,这表明构造的初始常量值随机性最高,符合HRHF算法的设计目标。
(2)迭代结构的优化: 通过优化迭代结构,提升了算法的执行效率。实验结果表明,在输入消息长度为401080字节的条件下,HRHF算法可以在1秒内完成4502000次运算,与SM3算法的运算效率基本一致,这表明HRHF算法可以支持快速运算。
2.4 对比实验结果
在相同的迭代结构下,HRHF算法的输出哈希值熵值相对于SM3算法有所增加,同时在哈希值长度都为256位的情况下,HRHF算法的轮函数复杂性更高,所产生的哈希值信息熵也高于SHA-256算法,这表明HRHF算法基于线性分组码在哈希值长度和迭代结构之间达到了有效的平衡,使得哈希值具有更高的随机性,同时也更好地隐藏了输入输出之间的关联性。 HRHF算法在运算效率和内存损耗方面也表现出了优势。
2.5 Python代码实现
import struct# 哈希值长度
HASH_LENGTH = 32 # 256 bits# 线性分组码参数
CODE_LENGTH = 32 # 码长
CODE_DIMENSION = 6 # 维度# 生成矩阵初始化
def generate_matrix():matrix = [[0] * CODE_LENGTH for _ in range(CODE_DIMENSION)]# 示例矩阵for i in range(CODE_DIMENSION):matrix[i][i] = 1return matrix# 生成码字
def generate_code_word(matrix):code_word = [0] * CODE_LENGTH# 使用生成矩阵生成码字for i in range(CODE_LENGTH):for j in range(CODE_DIMENSION):# 模2加法code_word[i] ^= matrix[j][i]return code_word# 循环左移
def rotate_left(value, shift):return ((value << shift) & 0xFFFFFFFF) | (value >> (32 - shift))# 消息预处理
def preprocess_message(message):extended_message = list(message) + [0x80] + [0x00] * 8 # 添加长度占位符words = []for i in range(0, len(extended_message), 4):word = 0for j in range(min(4, len(extended_message) - i)):word |= extended_message[i + j] << (24 - 8 * j)words.append(word)return words# 消息扩展
def extend_message(words):# 确保words至少有16个元素while len(words) < 16:words.append(0) # 添加零填充while len(words) < 128:w = words[-1]w16 = words[-16]words.append((w16 ^ rotate_left(w16, 9) ^ rotate_left(w16, 17)) ^(rotate_left(w, 15) ^ rotate_left(w, 23)))# 布尔函数
def ff(x, y, z, j):if 16 <= j <= 63:return x ^ y ^ zelse:return (x & y) | ((~x) & z)# 布尔函数
def gg(x, y, z, j):if 16 <= j <= 63:return x ^ y ^ zelse:return (x & y) | (x & z) | (y & z)# 压缩函数
def compress(state, words):for i in range(64):# 中间变量更新ss1 = rotate_left(state[0], 7) + rotate_left(state[4], 12)ss1 &= 0xFFFFFFFF # Ensure 32-bitss2 = ss1 ^ rotate_left(state[0], 12)tt1 = ff(state[0], state[1], state[2], i) + state[3] + ss2 + words[i]tt1 &= 0xFFFFFFFF # Ensure 32-bittt2 = gg(state[4], state[5], state[6], i) + state[7] + ss1 + words[i + 64]tt2 &= 0xFFFFFFFF # Ensure 32-bit# 状态寄存器更新state = [state[1],state[2],state[3],tt1,state[5],state[6],state[7],tt2]return state# 主算法
def hrhf(message):state = [0] * (HASH_LENGTH // 4) # 初始化寄存器matrix = generate_matrix()code_word = generate_code_word(matrix)# 循环左移操作以增加随机性for i in range(CODE_DIMENSION):code_word[i] = rotate_left(code_word[i], 6) # 循环左移6位# 将码字分配给初始寄存器for i in range(HASH_LENGTH // 4):state[i] = code_word[i % CODE_DIMENSION]# 消息预处理words = preprocess_message(message)# 消息扩展extend_message(words)# 迭代压缩state = compress(state, words)# 将32位整数转换为256位哈希值hash_value = bytearray(HASH_LENGTH)for i in range(HASH_LENGTH // 4):word = state[i]for j in range(4):hash_value[i * 4 + j] = (word >> (24 - 8 * j)) & 0xFFreturn hash_valueif __name__ == "__main__":message = b'qyx222'hash_value = hrhf(message)print(hash_value.hex())
这篇关于基于纠错码的哈希函数构造方案的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




