本文主要是介绍机器学习项目——基于机器学习(RNN LSTM 高斯拟合 MLP)的锂离子电池剩余寿命预测方法研究(代码/论文),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
完整的论文代码见文章末尾 以下为核心内容和部分结果
摘要
机器学习方法在电池寿命预测中的应用主要包括监督学习、无监督学习和强化学习等。监督学习方法通过构建回归模型或分类模型,直接预测电池的剩余寿命或健康状态。无监督学习方法则通过聚类分析和降维技术,识别电池数据中的潜在模式和特征。强化学习方法通过构建动态决策模型,在电池运行过程中不断优化预测策略和调整参数。上述方法不仅可以提高预测精度,还可以在一定程度上降低对电池内部复杂机制的依赖。
近年来,研究人员在基于机器学习的锂离子电池剩余寿命预测方面取得了许多重要进展。例如,利用长短期记忆网络(LSTM)、支持向量机(SVM)和随机森林(RF)等模型对电池寿命进行预测,取得了较好的效果。这些方法不仅能够捕捉电池运行过程中的复杂动态特性,还能够处理大规模、高维度的数据。然而,如何进一步提高预测精度、降低计算复杂度以及实现模型的实时更新仍然是当前研究中的重要课题。
基于以上背景,本研究旨在综合利用机器学习技术,构建高效的锂离子电池剩余寿命预测模型。通过深入分析不同机器学习算法的特点和适用性,探索数据预处理、特征选择和模型优化等关键技术,最终实现锂离子电池剩余寿命的精确预测和有效管理。
训练过程
数据集
CALCE(Center for Advanced Life Cycle Engineering)电池团队的数据集提供了关于锂离子电池的广泛实验数据,包括连续完全和部分循环、存储、动态驾驶剖面、开路电压(OCV)测量以及阻抗测量。测试的电池具有不同的形态因子(圆柱形、袋式和棱柱形)和化学组成(LCO、LFP和NMC)。
数据集地址如下:
https://calce.umd.edu/battery-data
RNN模型(循环神经网络)
RNN模型在时间序列数据中表现出色,适合处理锂离子电池的周期性充放电数据。
它能够捕捉到数据中的时间依赖关系,比如电池充电、放电过程中特定模式的变化,这对于准确预测电池剩余寿命至关重要。
RNN通过记忆先前时间步的信息,可以在预测过程中考虑到长期依赖,这是传统的前馈神经网络(如MLP)所不具备的优势。
MLP模型(多层感知器)
MLP模型在非时间序列数据上表现良好,可以用于处理电池的静态特征数据,如电池的物理结构、化学成分等。
它通过多层次的非线性变换,能够学习到复杂的特征关系,从而提高对电池寿命的预测精度。
当结合静态特征与动态时间序列数据时,MLP能够在一定程度上弥补RNN在静态特征上的不足。
高斯拟合
高斯过程在机器学习中常用于建模输入和输出之间的复杂关系,特别是当输入数据的分布未知或复杂时。
在锂离子电池剩余寿命预测中,高斯过程可以用来建立输入特征与电池寿命之间的概率模型。
它能够提供对预测结果的不确定性估计,这对于决策制定者来说是一种有价值的信息,尤其是在实时环境监测和预警系统中。
部分代码展示
class Net(nn.Module):def __init__(self, feature_size=8, hidden_size=[16, 8]):super(Net, self).__init__()self.feature_size, self.hidden_size = feature_size, hidden_sizeself.layer0 = nn.Linear(self.feature_size, self.hidden_size[0])self.layers = [nn.Sequential(nn.Linear(self.hidden_size[i], self.hidden_size[i+1]), nn.ReLU()) for i in range(len(self.hidden_size) - 1)]self.linear = nn.Linear(self.hidden_size[-1], 1)def forward(self, x):out = self.layer0(x)for layer in self.layers:out = layer(out)out = self.linear(out) return out
def tain(LR=0.01, feature_size=8, hidden_size=[16,8], weight_decay=0.0, window_size=8, EPOCH=1000, seed=0):mae_list, rmse_list, re_list = [], [], []result_list = []for i in range(4):name = Battery_list[i]train_x, train_y, train_data, test_data = get_train_test(Battery, name, window_size)train_size = len(train_x)print('sample size: {}'.format(train_size))setup_seed(seed)model = Net(feature_size=feature_size, hidden_size=hidden_size)model = model.to(device)optimizer = torch.optim.Adam(model.parameters(), lr=LR, weight_decay=weight_decay)criterion = nn.MSELoss()test_x = train_data.copy()loss_list, y_ = [0], []for epoch in range(EPOCH):X = np.reshape(train_x/Rated_Capacity, (-1, feature_size)).astype(np.float32)y = np.reshape(train_y[:,-1]/Rated_Capacity,(-1,1)).astype(np.float32)X, y = torch.from_numpy(X).to(device), torch.from_numpy(y).to(device)output= model(X)loss = criterion(output, y)optimizer.zero_grad() # clear gradients for this training steploss.backward() # backpropagation, compute gradientsoptimizer.step() # apply gradientsif (epoch + 1)%100 == 0:test_x = train_data.copy() #每100次重新预测一次point_list = []while (len(test_x) - len(train_data)) < len(test_data):x = np.reshape(np.array(test_x[-feature_size:])/Rated_Capacity, (-1, feature_size)).astype(np.float32)x = torch.from_numpy(x).to(device)pred = model(x) # 测试集 模型预测#pred shape为(batch_size=1, feature_size=1)next_point = pred.data.numpy()[0,0] * Rated_Capacitytest_x.append(next_point)#测试值加入原来序列用来继续预测下一个点point_list.append(next_point)#保存输出序列最后一个点的预测值y_.append(point_list)#保存本次预测所有的预测值loss_list.append(loss)mae, rmse = evaluation(y_test=test_data, y_predict=y_[-1])re = relative_error(y_test=test_data, y_predict=y_[-1], threshold=Rated_Capacity*0.7)print('epoch:{:<2d} | loss:{:<6.4f} | MAE:{:<6.4f} | RMSE:{:<6.4f} | RE:{:<6.4f}'.format(epoch, loss, mae, rmse, re))if (len(loss_list) > 1) and (abs(loss_list[-2] - loss_list[-1]) < 1e-6):breakmae, rmse = evaluation(y_test=test_data, y_predict=y_[-1])re = relative_error(y_test=test_data, y_predict=y_[-1], threshold=Rated_Capacity*0.7)mae_list.append(mae)rmse_list.append(rmse)re_list.append(re)result_list.append(y_[-1])return re_list, mae_list, rmse_list, result_list

部分结果展示
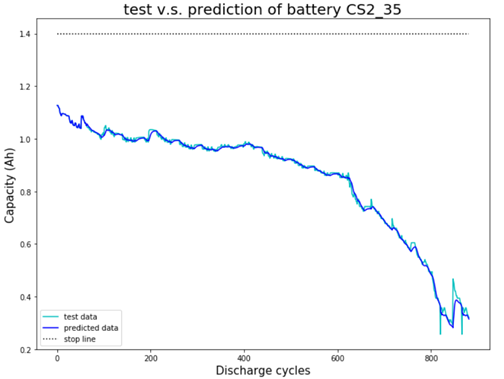
预测数据(青色虚线)与测试数据(蓝色实线)高度吻合,说明模型能够较准确地预测电池容量的衰减。在大多数放电周期范围内,预测值与实际值基本重合,特别是在前600个放电周期内,预测效果较好。在800个放电周期之后,虽然有一些偏差,但总体趋势仍然一致。
论文 代码 获取方式
点这里 只需要一点点辛苦费,不需要你跑模型,都是ipynb文件。
这篇关于机器学习项目——基于机器学习(RNN LSTM 高斯拟合 MLP)的锂离子电池剩余寿命预测方法研究(代码/论文)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






