本文主要是介绍Sankey流图在老年癌症患者症状分析中的应用|科研绘图·24-09-03,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
小罗碎碎念
本期推文主题|桑基图
桑基图我们很多人都不陌生,但是大部分应该都是仅限于在文献中读到过,动手去实践的较少,在文献中的具体作用,可能也不太清楚,所以我这一期推文就来盘一盘桑基图。
本期推文共有两部分,第一部分是介绍一下桑基图的定义,并提供了一个R语言的完整代码,方便大家理解绘制桑基图的基本流程。
第二部分则是准备了一篇与老年癌症患者症状分析相关的文章,分析了桑基图在文献中的作用,大家按需自取!!
一、定义
桑基图是一种可视化技术,用于展示流动情况。多个实体(节点)通过矩形或文字表示。它们之间的联系通过箭头或弧线表示,其宽度与流动的重要性成比例。
以下是一个示例,展示了从一国(左侧)向另一国(右侧)迁移的人数。
代码演示
这段代码的主要目的是创建一个桑基图(Sankey diagram),用于展示数据集中的流动情况。
首先,它导入了所需的库,并从GitHub加载了数据集。然后,将数据转换为长格式,并创建了一个节点数据框,用于存储参与流动的所有实体。
接下来,重新格式化数据以适应networkD3包的要求。最后,使用sankeyNetwork函数创建桑基图,并设置了相关的参数。
# 导入所需的库
library(tidyverse) # 数据处理和可视化
library(viridis) # 提供颜色渐变方案
library(patchwork) # 图形组合
library(hrbrthemes) # 提供美观的图形主题
library(circlize) # 环形图表# 从GitHub加载数据集
data <- read.table("https://raw.githubusercontent.com/holtzy/data_to_viz/master/Example_dataset/13_AdjacencyDirectedWeighted.csv", header=TRUE)# 导入networkD3包
library(networkD3)# 将数据转换为长格式
data_long <- data %>%rownames_to_column %>% # 将行名转换为列gather(key = 'key', value = 'value', -rowname) %>% # 将数据转换为长格式filter(value > 0) # 只保留值大于0的数据
colnames(data_long) <- c("source", "target", "value") # 重命名列名
data_long$target <- paste(data_long$target, " ", sep="") # 在目标列的值后添加空格# 创建节点数据框:列出参与流动的所有实体
nodes <- data.frame(name=c(as.character(data_long$source), as.character(data_long$target)) %>% unique())# 使用networkD3时,连接必须使用id而不是实际名称,因此需要重新格式化数据
data_long$IDsource=match(data_long$source, nodes$name)-1 # 匹配源节点并减去1(因为networkD3的id从0开始)
data_long$IDtarget=match(data_long$target, nodes$name)-1 # 匹配目标节点并减去1# 准备颜色渐变方案
ColourScal ='d3.scaleOrdinal() .range(["#FDE725FF","#B4DE2CFF","#6DCD59FF","#35B779FF","#1F9E89FF","#26828EFF","#31688EFF","#3E4A89FF","#482878FF","#440154FF"])'# 安装并导入networkD3包
install.packages("networkD3")
library(networkD3)# 创建桑基图
sankeyNetwork(Links = data_long, Nodes = nodes,Source = "IDsource", Target = "IDtarget",Value = "value", NodeID = "name",sinksRight=FALSE, colourScale=ColourScal, nodeWidth=40, fontSize=13, nodePadding=20)

二、文献举例|Sankey流图在老年癌症患者症状分析中的应用

在这篇文章中,Sankey流图被应用于分析和展示老年晚期癌症患者的症状轨迹。
-
症状轨迹可视化:文章通过Sankey流图展示了老年癌症患者在治疗期间症状的变化,如腹泻频率、疲劳对日常活动的干扰以及疼痛程度的变化。这些图表帮助研究人员和临床医生理解患者在治疗过程中可能经历的不同症状状态及其变化。
-
数据解读:Sankey流图使得研究人员能够直观地看到患者从一个症状状态转移到另一个状态的可能性和变化性。例如,通过观察Sankey流图,研究人员可以识别出哪些患者的症状有所改善,哪些患者的病情恶化,以及哪些患者的症状保持不变。
-
临床决策支持:通过展示症状的严重程度和变化,Sankey流图为临床医生提供了重要的信息,帮助他们更好地理解患者的治疗反应和耐受性,从而做出更加个性化的治疗决策。
-
研究结果展示:文章中提到,Sankey流图作为一种数据可视化工具,可以用于展示研究结果,使得复杂的数据信息更加易于理解和交流。
-
患者教育:Sankey流图也可以作为教育工具,帮助患者和家属理解治疗过程中可能遇到的症状变化,从而更好地准备和管理治疗过程中的挑战。
-
数据驱动的洞见:通过分析Sankey流图中的数据,研究人员可以获得关于患者群体的深入见解,比如哪些症状最常见,哪些症状对患者的日常活动影响最大,以及不同症状之间的关联性。
Fig. 2 通过Sankey流图详细展示了老年晚期癌症患者在接受治疗期间,其症状(如腹泻、日常活动干扰和疼痛)的变化情况。
这些图表通过不同的颜色和节点表示不同时间点和症状状态,弧线则表示患者从一个症状状态转移到另一个状态的流动。
Fig. Ai
- 描述:展示了腹泻症状的流行率和频率随时间的稳定性。
- 分析:这意味着在观察期内,腹泻的总体情况没有显著变化。
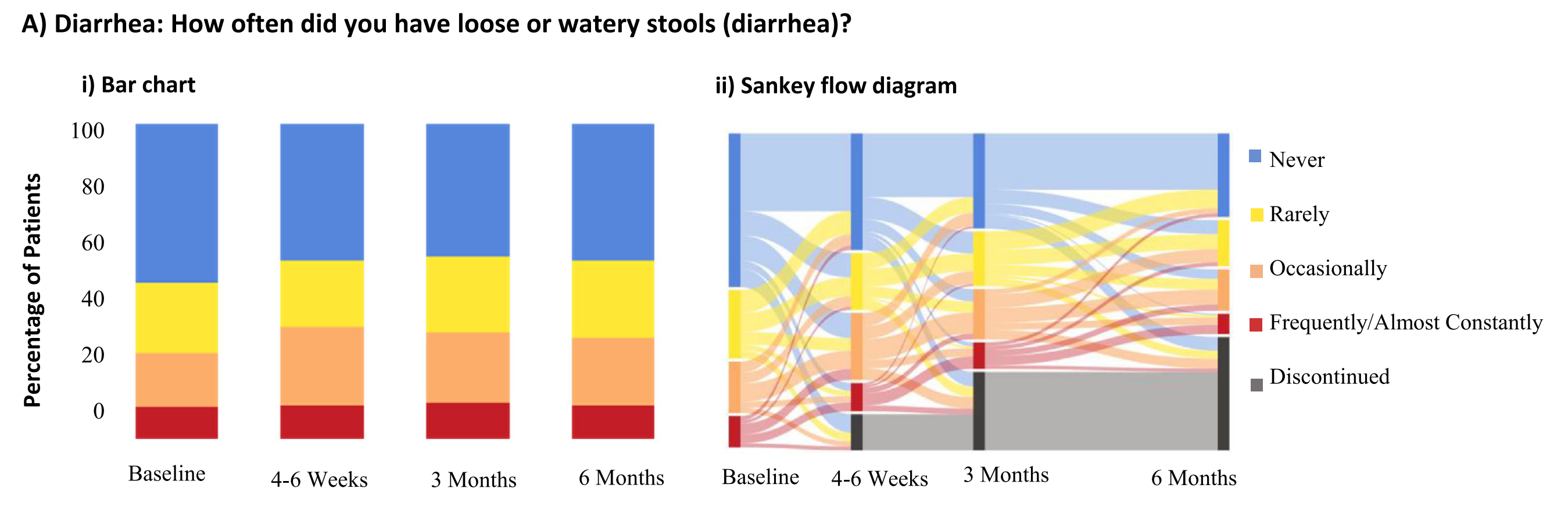
Fig. Aii
- 描述:关注弧线从左到右的流动,特别是黄色弧线。
- 分析:
- 在基线时,约22%的患者报告腹泻很少发生(黄色节点)。
- 4-6周后,这些患者中33%改善,没有腹泻;28%保持不变;27%报告腹泻频率增加;12%退出研究。
- 意义:这表明腹泻症状的改善和恶化在患者群体中是动态变化的,且有一部分患者因症状加重而退出研究。
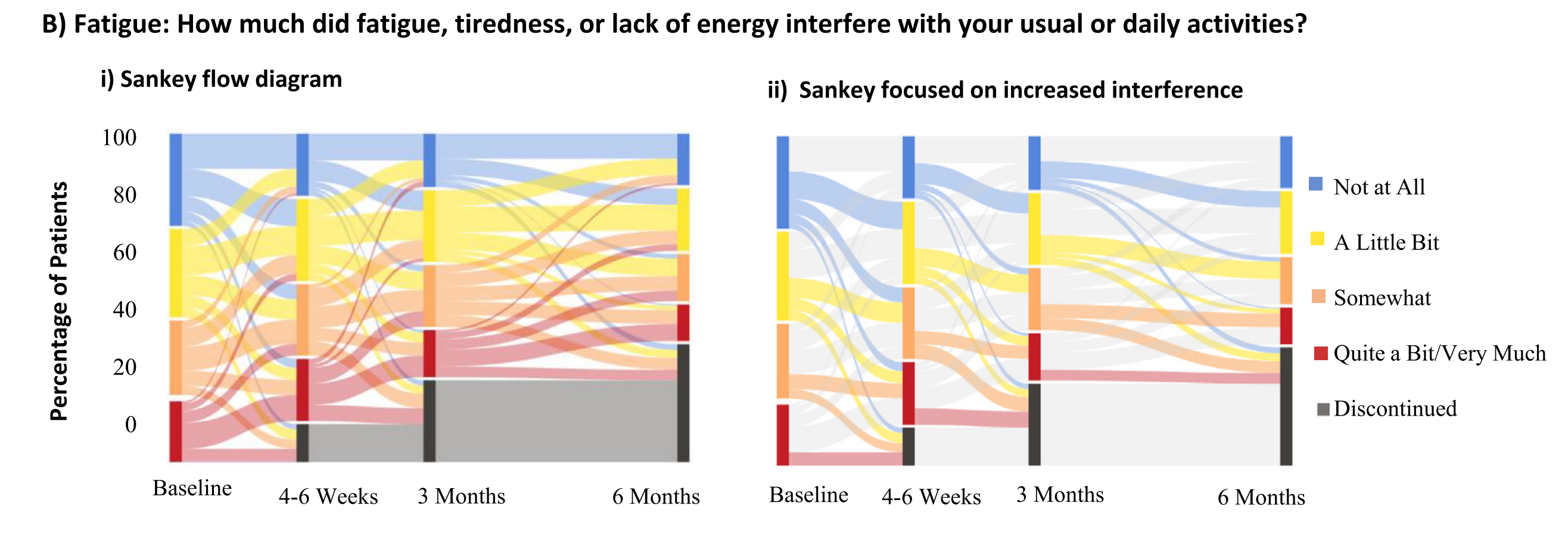
Fig. Bi
- 描述:展示了患者在日常活动干扰方面的频繁变化。
- 分析:
- 弧线显示患者在每个时间点向更高或更低的日常活动干扰级别移动。
Fig. Bii(聚焦Sankey图)
- 描述:突出显示了日常活动干扰加剧的患者比例。
- 分析:
- 治疗开始时无日常活动干扰的患者中,56%在4-6周后报告了一定程度的干扰(6%退出)。
- 意义:这强调了日常活动干扰的增加对患者生活质量的影响,以及退出治疗的患者比例。
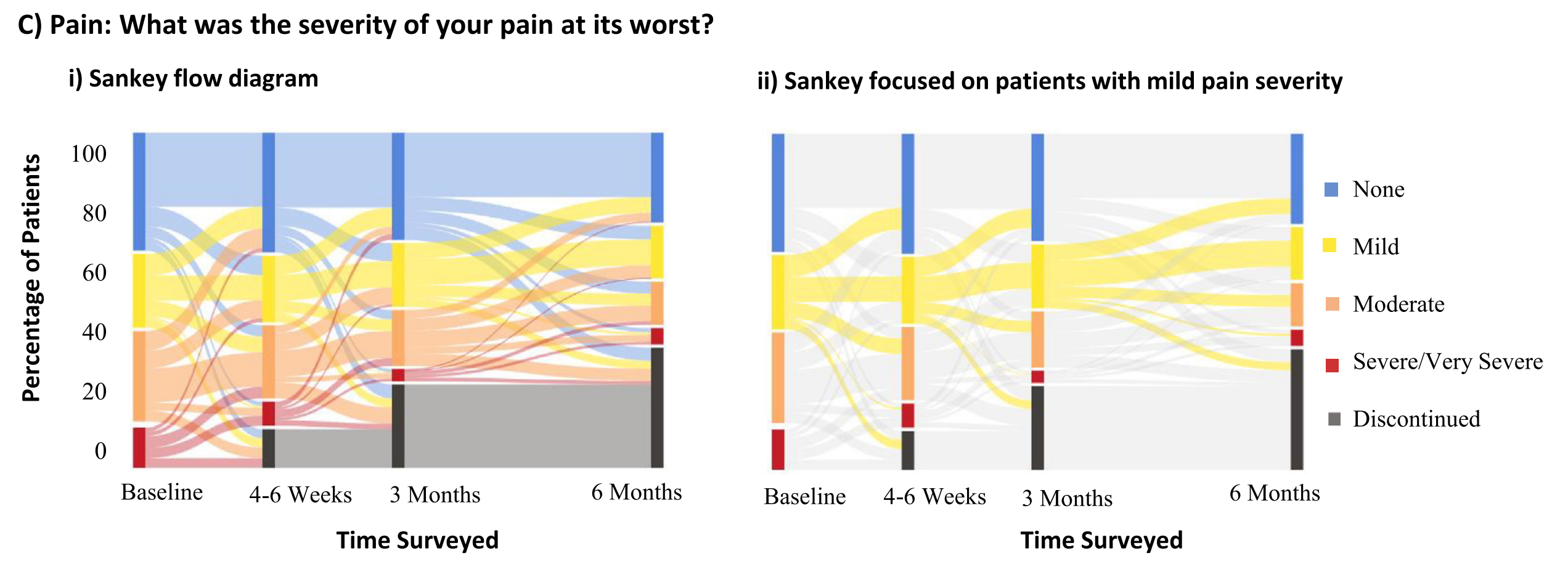
Fig. Ci
- 描述:与Bi类似,展示了患者在日常活动干扰方面的频繁变化。
Fig. Cii(聚焦Sankey图)
- 描述:突出显示了日常活动干扰加剧的患者比例。
- 分析:
- 治疗开始时无日常活动干扰的患者中,56%在4-6周后报告了一定程度的干扰(6%退出)。
- 意义:与Bii类似,这进一步强调了日常活动干扰的增加对患者生活质量的影响。
这篇关于Sankey流图在老年癌症患者症状分析中的应用|科研绘图·24-09-03的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







