本文主要是介绍windows平台调用函数堆栈的追踪方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
转自:http://blog.csdn.net/lanuage/article/details/52203447
在windows平台,有一个简单的方法来追踪调用函数的堆栈,就是利用函数CaptureStackBackTrace,但是这个函数不能得到具体调用函数的名称,只能得到地址,当然我们可以通过反汇编的方式通过地址得到函数的名称,以及具体调用的反汇编代码,但是对于有的时候我们需要直接得到函数的名称,这个时候据不能使用这个方法,对于这种需求我们可以使用函数:SymInitialize、StackWalk、SymGetSymFromAddr、SymGetLineFromAddr、SymCleanup。
原理
基本上所有高级语言都有专门为函数准备的堆栈,用来存储函数中定义的变量,在C/C++中在调用函数之前会保存当前函数的相关环境,在调用函数时首先进行参数压栈,然后call指令将当前eip的值压入堆栈中,然后调用函数,函数首先会将自身堆栈的栈底地址保存在ebp中,然后抬高esp并初始化本身的堆栈,通过多次调用最终在堆栈段形成这样的布局
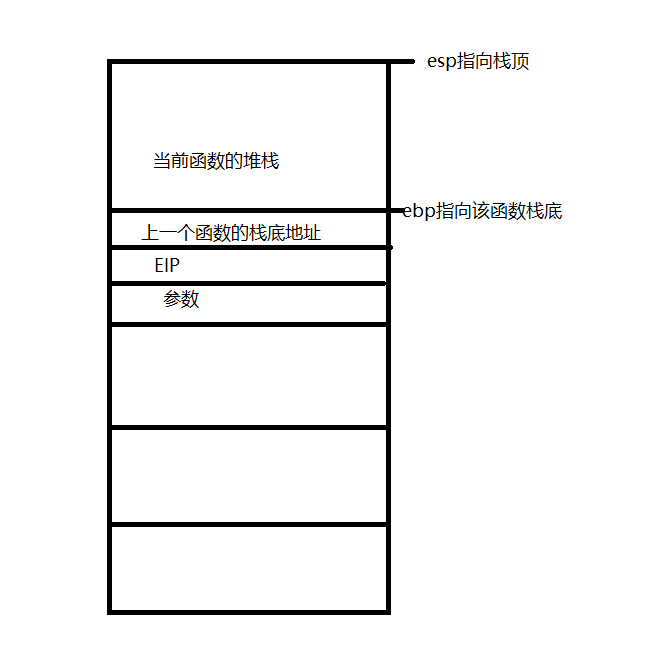
这里对函数的原理做简单的介绍,有兴趣的可以看我的另一篇关于C函数原理讲解的博客,点击这里跳转
VC++编译器在编译时对函数名称与地址都有详细的记录,编译出来的程序都有一个符号常量表,将符号常量与它对应的地址形成映射,在搜索时首先根据这些堆栈环境找到对应地址,然后根据地址在符号常量表中,找到具体调用的信息,这是一个很复杂的工程,需要对编译原理和汇编有很强的基础,幸运的是,如今这些工作不需要程序员自己去做,windows帮助我们分配了一组API,在编写程序时只需要调用API即可
函数说明
SymInitialize:这个函数主要用作初始化相关环境。
SymCleanup:清楚这个初始化的相关环境,在调用SymInitialize之后需要调用SymCleanup,进行释放资源的操作
StackWalk:程序的功能主要由这个函数实现,函数会从初始化时的堆栈顶开始向下查找下一个堆栈的信息,原型如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
需要注意的一点是,在首次调用该函数时需要对StackFrame中的AddrPC、AddrFrame、AddrStack这三个成员进行初始化,填入相关值,以便函数从此处线程堆栈的栈顶进行搜索,否则调用函数将失败,具体如何填写请看MSDN。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 1
- 2
- 3
- 4
- 5
- 6
- 7
SymGetLineFromAddr:根据得到的地址值,获取调用函数的相关信息。主要记录是在哪个文件,哪行调用了该函数,下面是函数原型:
- 1
- 2
- 3
- 4
- 5
- 6
- 1
- 2
- 3
- 4
- 5
- 6
它参数的含义与SymGetSymFromAddr,相同。
通过上面对函数的说明,我们可以知道,为了追踪函数调用的详细信息,大致步骤如下:
1. 首先调用函数SymInitialize进行相关的初始化工作。
2. 填充结构体StackFrame的相关信息,确定从何处开始追踪。
3. 循环调用StackWalk函数,从指定位置,向下一直追踪到最后。
4. 每次将获取的地址分别传入SymGetSymFromAddr、SymGetLineFromAddr,得到函数的详细信息
5. 调用SymCleanup,结束追踪
但是需要注意的一点是,函数StackWalk会顺着线程堆栈进行查找,如果在调用之前,某个函数已经返回了,它的堆栈被回收,那么函数StackWalk自然不会追踪到该函数的调用。
具体实现
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
测试程序如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
OPEN_STACK_TRACK是一个宏,它的定义如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
这个程序需要注意以下几点:
1. 如果想要追踪所有调用的函数,需要将这个宏放置到最后调用的位置,当然前提是此时之前被调函数的堆栈仍然存在。当然可以在调用前简单的计算,找出在哪个位置是所有函数都没有调用完成的,不过这样可能就与程序的初衷相悖,毕竟程序本身就是为了获取堆栈的调用信息。。。。
2. IMAGEHLP_SYMBOL的结构体中关于Name的成员,只有一个字节,而函数SymGetSymFromAddr在填入值时是没有关心这个实际大小,它只是简单的填充,这就造成了缓冲区溢出的情况,为了避免我们需要在Name后面额外给一定大小的缓冲区,用来接收数据,这也就是我们定义这个结构体SYMBOL_INFO的原因。另外IMAGEHLP_SYMBOL中的MaxNameLength成员是指Name的最大长度,需要根据给定的缓冲区,进行计算。
3. 从测试程序来看,在进行追踪时func4已经调用完成,而我们在获取线程的运行时环境g_context时函数GetThreadContext,也在堆栈中,最终得到的结果中必然包含GetThreadContext的调用信息,如果想去掉这个信息,只需要修改获得信息的值,既然函数StackWalk是根据堆栈进行追踪,那么只需要修改对应堆栈的信息即可,需要修改eip 、ebp、esp的值,关于esp ebp的值很好修改,可以在对应函数中esp ebp这些寄存器的值,而eip的值就不那么好获取,本生利用mov指令得到eip的值它也是指令,会改变eip的值,从而造成获取到的eip的值不准确,所以我们利用call指令,先保存当前eip的值到堆栈,然后再从堆栈中取出。call指令的实质是 push eip和jmp addr指令的组合,并不一定非要调用函数。call指令的大小为5个字节,所以call $ + 5表示先保存eip在跳转到它的下一跳指令处。这样就可以有效的避免检测到GetThreadContext中的相关函数调用。
这篇关于windows平台调用函数堆栈的追踪方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





