本文主要是介绍深度学习论文被评“创新性不足、工作量不够”怎么办?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
投稿时遇到审稿人提出文章创新性不足、工作量不够,该怎么办?
今天我就来分享三种应对方法:下采样策略、归一化策略、改进网络模型。
改进网络模型
增加创新性:
从模型架构和训练策略这两方面入手:
模型架构创新:常见的方法有缝合其他网络、引入注意力、轻量化等,缝合网络加注意力在我之前的文章里详细说过,这边就不多说了。
轻量化策略就是对网络架构的重新设计或优化,比如深度可分离替换一般的3*3卷积,前提是精度不能损失太多,而且模型大小或者推理速度能显著提高。
训练策略创新:通过优化训练策略来提升模型性能也能增加创新性,我们可以选择多任务学习、添加辅助损失。
多任务学习能同时学习多个相关任务,在训练过程中直接应用。比如CV方向如果做的是检测,就可以加个分割任务,用分割促检测,具体点就是将分割网络与检测网络共享主干网络,让网络前面部分的参数提前得到有效训练。
这部分如果细说可以有15种方法,不过我建议大家直接看论文,如果不想花时间找可以直接拿我已经整理好了,15种多任务学习方法共84篇参考论文。
论文原文+开源代码需要的同学看文末
辅助损失可以作为正则化项,帮助模型在训练过程中保持稳定的梯度流,同时迫使中间层学习有用的特征表示,比如深度监督,参考yolov9相对yolov7的改进。
增加工作量:
既然要设计新的模型,那现有方法的优缺点得了解吧,还有新模型的实现细节,比如选择合适的模块、确定模块之间的连接方式、设计损失函数等。
再加上在不同数据集上的测试、与现有方法的对比以及消融实验等。另外还需要根据实验结果对模型参数进行调优,找到最优,这个过程基本都要反复多次。
下采样
增加创新性:
可以考虑新的下采样策略,比如自适应下采样、金字塔池化,这类方法能减少特征图的尺寸和计算量,保留更多的有用信息,比平均池化等老方法更有创新性。
另外还可以考虑拓展新的下采样方法的应用场景,比如图像分类、目标检测之类,通过跨领域的应用来增加创新点。
只看文字可能有些难get,大家可以搭配我准备好的下采样高质量paper合集来理解,这些论文都可以直接参考,而且全都有代码,复现搞起。
论文原文+开源代码需要的同学看文末
举其中一篇论文案例:
AutoFocusFormer: Image Segmentation off the Grid
采用自适应下采样和局部注意力机制,专注于图像中更重要的区域,以提高分割任务的性能。
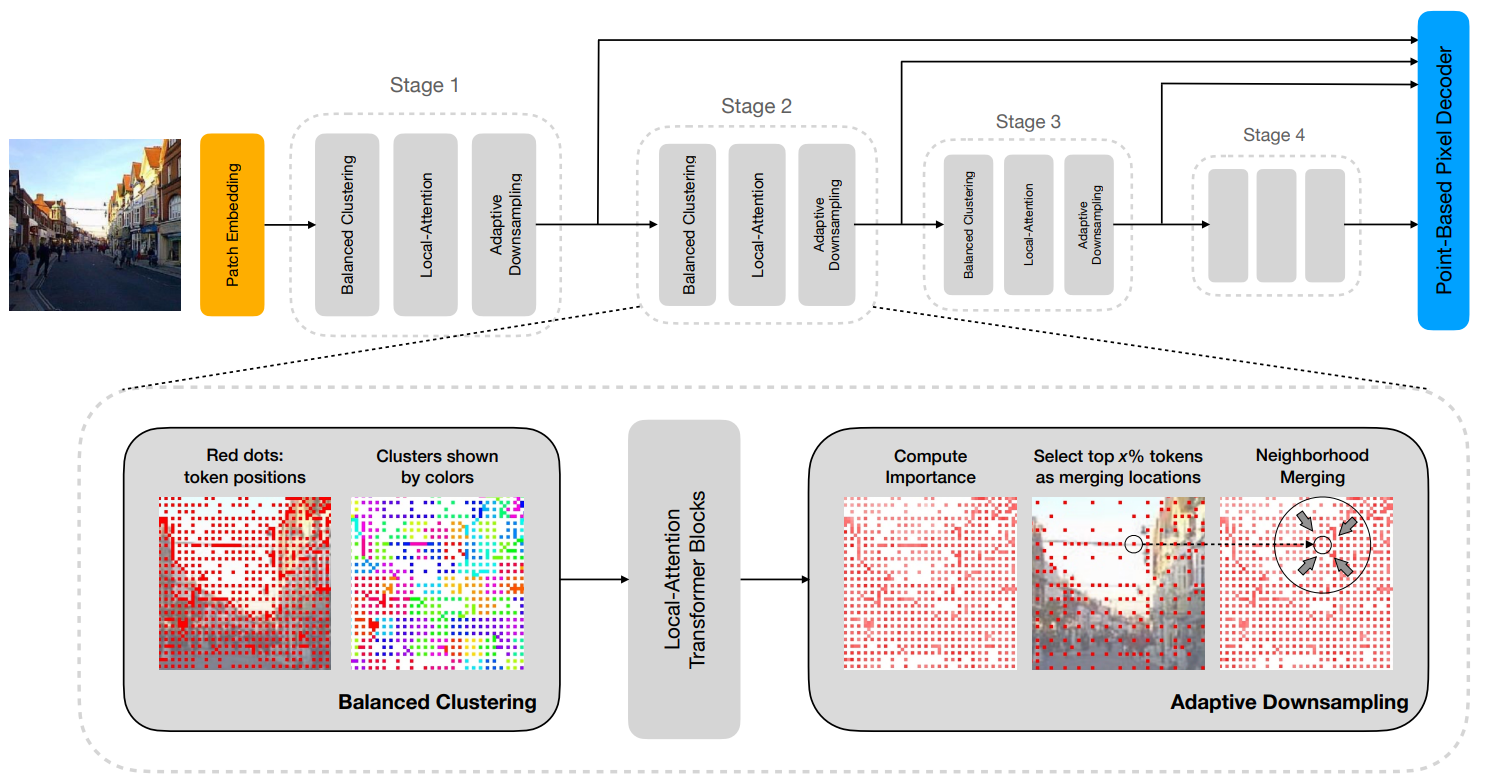
增加工作量:
现有下采样模块的优缺点,还有新方法的实现细节,比如合适的卷积核大小、步长、池化方式等参数,另外还要有大量的实验来验证效果,工作量这不就来了。
还有评估,引入新的下采样后,需要全面评估它的性能,比如在不同数据集上的测试、与现有方法的比较还有消融实验。
归一化
增加创新性:
从技术出发,着眼于归一化技术细节上的优化,就是怎么使用更复杂的归一化函数、结合领域知识的归一化策略,给模型带来性能提升。
从理论出发,探讨它对模型性能的影响机制,再通过实验验证提的这些理论分析的正确性,就可以有理论上的创新了。
另外还有引入新的归一化方法或策略,比如批归一化、组归一化、实例归一化等,这些新的归一化方法本身就是创新点。
这边我也整理好了归一化相关的参考paper合集帮助大家更直观的理解,开源代码也都有。
论文原文+开源代码需要的同学看文末
也举其中一篇论文案例:
BCN: Batch Channel Normalization for Image Classification
批量通道归一化,通过分别沿着(N, H, W)和(C, H, W)轴进行归一化处理,基于自适应参数组合归一化输出,同时利用通道和批量维度的优势,提高神经网络的泛化性能。
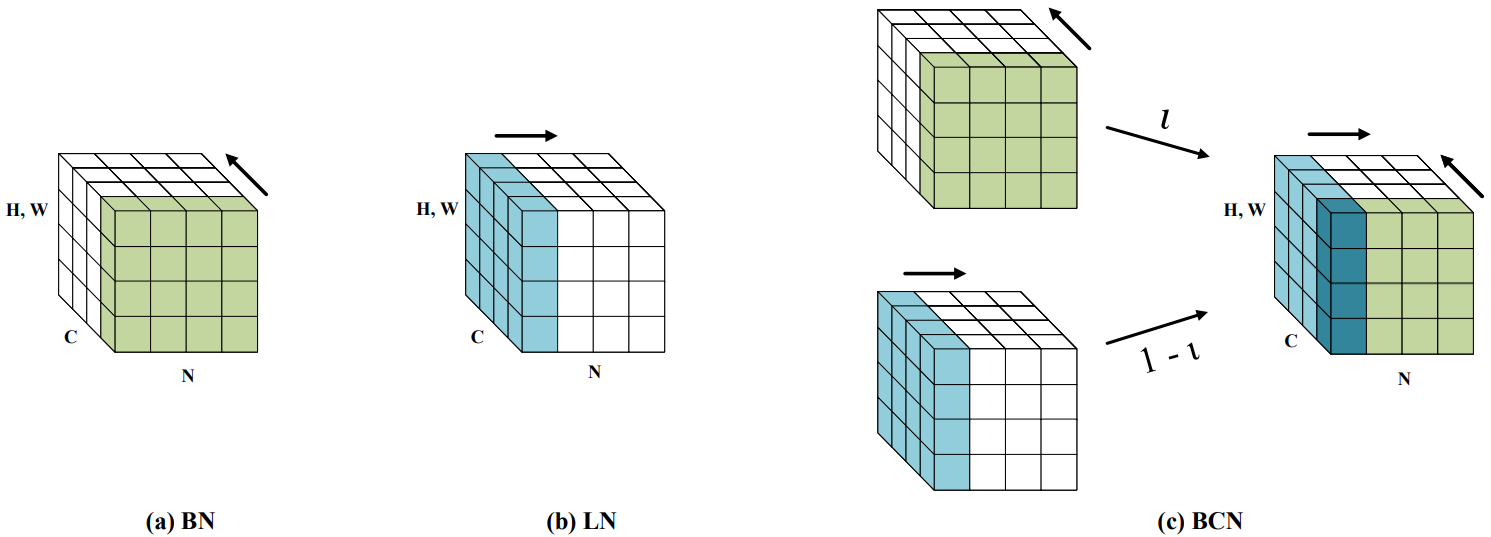
增加工作量:
归一化方法中的参数,比如批归一化中的衰减率和动量,对模型性能影响很大,所以需要对这些参数进行细致的调优,分析不同参数设置对模型稳定性和性能的影响。
再加上验证方法有效性的实验设计,包括选择合适的基准数据集、设计对比实验、评估不同归一化方法的性能指标等,工作量不用愁。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“创新工作”获取全部论文+开源代码
码字不易,欢迎大家点赞评论收藏
这篇关于深度学习论文被评“创新性不足、工作量不够”怎么办?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




