本文主要是介绍2700+存储过程的超复杂Oracle,国产化怎么办?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前不久部门同事参与了一个关键客户的国产数据库Poc工作。从群里反馈的一些信息来看,难度还是比较大。
我们知道,对于数据库国产改造,其实有几个比较大的难点,其中最让人头疼的无非就是存储过程之类的对象了。
从同时提供的迁移报告来看,我认为可能是今年我们接触较为复杂的一个Oracle国产化改造项目之一了,这里跟大家分享分享。
2700+ 存储过程
首先我们来看看同时分享的MogDB MTK报告,这里我们截图并打码,分享一下部分数据截图:
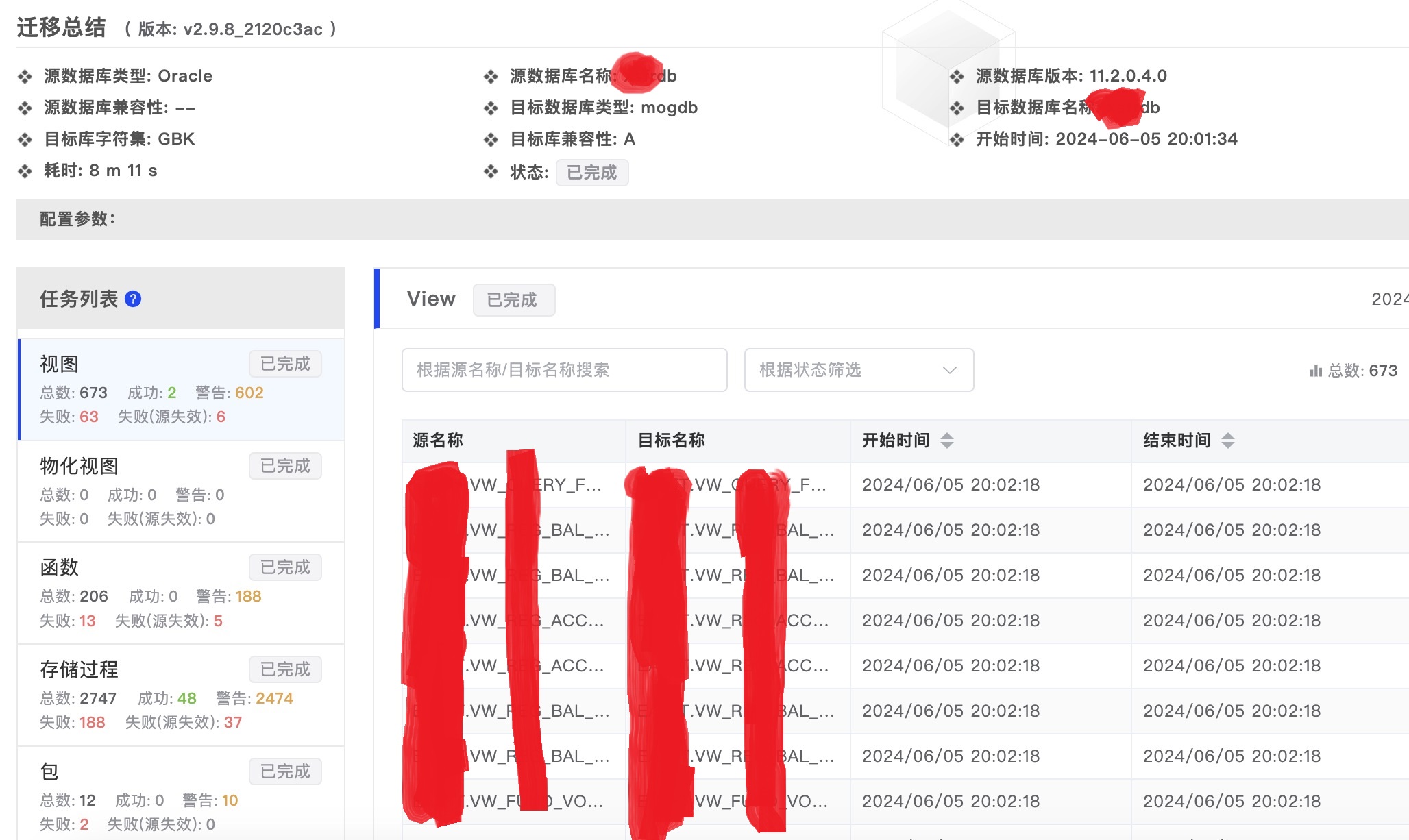
大家可以看到这个Oracle 数据库还是非常复杂的,有2747个存储过程。通过MogDB mtk工具进行迁移之后,我们可以看到只有188个存储过程迁移失败,也就是说这188个存储目前暂时无法通过MogDB mtk工具来实现代码的自动转换。
实际上我们可以看到,这188个过程中,有37个存储过程在源库就是异常状态,那么去掉这37个,那么实际上迁移失败的可理解为只有188-37=151个存储过程。
那么151/(2747-37)=5.5%; 也就是说我们通过MogDB mtk工具基本上实现了该数据库存储过程的94.5%的自动化迁移改造。
换句话讲,大家也可以理解为这个版本的MogDB对于该用户数据库来讲,存储过程的兼容度在94.5%。
同时我们可以发现这个库除了存储过程之外,还有206个函数,其中源库失效的有5个函数,一共还有13个函数迁移失败了。这样大致算一下,函数的迁移成功比例大约是93.6%。
此外大家也可以看到对于视图的迁移改造,MogDB mtk也能很好的完成代码自动化改写,成功比例也在90%以上。
比如对于引用到的一些自定义函数,MogDB暂不支持的方式,那么我们后续代码改写,基本上都可以实现100%的国产化改造,这里分享一下这个案例中的改写部分内容。
MogDB 自定义函数改写
++原Oracle函数
CREATE OR REPLACE TYPE UI_FI.TYPE_LIST_AGG AS OBJECT
(
TOTAL VARCHAR2(4000),
STATIC FUNCTION ODCIAGGREGATEINITIALIZE(SCTX IN OUT TYPE_LIST_AGG) RETURN NUMBER,
MEMBER FUNCTION ODCIAGGREGATEITERATE(SELF IN OUT TYPE_LIST_AGG, VALUE IN VARCHAR2)
RETURN NUMBER,
MEMBER FUNCTION ODCIAGGREGATETERMINATE(SELF IN TYPE_LIST_AGG,
RETURNVALUE OUT VARCHAR2,
FLAGS IN NUMBER) RETURN NUMBER,
MEMBER FUNCTION ODCIAGGREGATEMERGE(SELF IN OUT TYPE_LIST_AGG, CTX2 IN TYPE_LIST_AGG)
RETURN NUMBER
);
/
CREATE OR REPLACE TYPE BODY UI_FI.TYPE_LIST_AGG IS
STATIC FUNCTION ODCIAGGREGATEINITIALIZE(SCTX IN OUT TYPE_LIST_AGG) RETURN NUMBER IS
BEGIN
SCTX := TYPE_LIST_AGG(NULL);
RETURN ODCICONST.SUCCESS;
END;
MEMBER FUNCTION ODCIAGGREGATEITERATE(SELF IN OUT TYPE_LIST_AGG, VALUE IN VARCHAR2)
RETURN NUMBER IS
BEGIN
SELF.TOTAL := SELF.TOTAL || VALUE;
RETURN ODCICONST.SUCCESS;
END;
MEMBER FUNCTION ODCIAGGREGATETERMINATE(SELF IN TYPE_LIST_AGG,
RETURNVALUE OUT VARCHAR2,
FLAGS IN NUMBER) RETURN NUMBER IS
BEGIN
RETURNVALUE := SUBSTR(SELF.TOTAL, 2);
RETURN ODCICONST.SUCCESS;
END;
MEMBER FUNCTION ODCIAGGREGATEMERGE(SELF IN OUT TYPE_LIST_AGG, CTX2 IN TYPE_LIST_AGG)
RETURN NUMBER IS
BEGIN
SELF.TOTAL := SELF.TOTAL || CTX2.TOTAL;
RETURN ODCICONST.SUCCESS;
END;
END;
/
CREATE OR REPLACE FUNCTION UI_FI.F_CHANGE_COL_TO_ROW(INPUT VARCHAR2) RETURN VARCHAR2
PARALLEL_ENABLE
AGGREGATE USING UI_FI.TYPE_LIST_AGG;
/
++ MogDB 改写的函数
CREATE OR REPLACE FUNCTION ui_fi.F_CHANGE_COL_TO_ROW_state_func (results VARCHAR2, val VARCHAR2)
RETURNS VARCHAR2
LANGUAGE sql COST 50 IMMUTABLE
AS $$ select results || val; $$;
CREATE OR REPLACE FUNCTION ui_fi.F_CHANGE_COL_TO_ROW_final_func (results VARCHAR2)
RETURNS VARCHAR2
LANGUAGE sql COST 111 IMMUTABLE
AS $$ select substr(results, 2)::VARCHAR2; $$;
CREATE AGGREGATE ui_fi.F_CHANGE_COL_TO_ROW(VARCHAR2)
(
sfunc = ui_fi.F_CHANGE_COL_TO_ROW_state_func,
stype = VARCHAR2,
initcond = '',
FINALFUNC = ui_fi.F_CHANGE_COL_TO_ROW_final_func
);
MogDB pipeline函数改写
这里我们完全仿照了客户生产环境代码的相关功能,给一个测试用例,具体生产代码就补贴了。
++ Oracle端
create TABLE t_test_pipeline(c1 varchar2(20),c2 number);
create type ty_test_pipeline as object(c1 varchar2(20),c2 number);
/
create type tyt_test_pipeline as table of ty_test_pipeline;
/
create or replace function f_test_pipeline(i number)
return tyt_test_pipeline --table of 类型
PIPELINED is
PRAGMA AUTONOMOUS_TRANSACTION; --自治事务
TYPE CUR1 IS REF CURSOR;
MYCURSOR CUR1;
SQL_1 VARCHAR2(4000);
SQL_2 VARCHAR2(4000);
OUT_REC ty_test_pipeline := ty_test_pipeline(NULL,NULL);--构造空对象
begin
EXECUTE IMMEDIATE 'TRUNCATE TABLE t_test_pipeline'; --有truncate table 注意ddl 自动commit的行为
insert into t_test_pipeline values ('a',1);
insert into t_test_pipeline values ('b',2);
insert into t_test_pipeline values ('c',2);--模拟两行以上数据
insert into t_test_pipeline values ('d',2);
commit; --有commit
SQL_1:='SELECT * FROM t_test_pipeline WHERE C2=1';
SQL_2:='SELECT * FROM t_test_pipeline WHERE C2=2';
if i =1 then --判断逻辑,打开不同的游标
OPEN MYCURSOR FOR SQL_1;
ELSE
OPEN MYCURSOR FOR SQL_2;
end if;
LOOP
FETCH MYCURSOR
INTO OUT_REC.C1,
OUT_REC.C2;
EXIT WHEN MYCURSOR%NOTFOUND;
PIPE ROW(OUT_REC);
END LOOP;
CLOSE MYCURSOR;
RETURN;
end;
/
--调用
SELECT * FROM TABLE(f_test_pipeline(1));
SELECT * FROM TABLE(f_test_pipeline(2));
++ MogDB 改写后
create TABLE t_test_pipeline(c1 varchar2(20),c2 number);
create type ty_test_pipeline as object(c1 varchar2(20),c2 number);
/
create type tyt_test_pipeline as table of ty_test_pipeline;
/
create or replace function f_test_pipeline(i number)
return tyt_test_pipeline --table of 类型
is
PRAGMA AUTONOMOUS_TRANSACTION; --自治事务
TYPE CUR1 IS REF CURSOR;
MYCURSOR CUR1;
SQL_1 VARCHAR2(4000);
SQL_2 VARCHAR2(4000);
OUT_TABLE tyt_test_pipeline;
begin
EXECUTE IMMEDIATE 'TRUNCATE TABLE t_test_pipeline'; --有truncate table 注意ddl 自动commit的行为
insert into t_test_pipeline values ('a',1);
insert into t_test_pipeline values ('b',1);
insert into t_test_pipeline values ('c',2);--模拟两行以上数据
insert into t_test_pipeline values ('d',2);
commit; --有commit
SQL_1:='SELECT * FROM t_test_pipeline WHERE C2=1';
SQL_2:='SELECT * FROM t_test_pipeline WHERE C2=2';
if i =1 then --判断逻辑,打开不同的游标
OPEN MYCURSOR FOR SQL_1;
ELSE
OPEN MYCURSOR FOR SQL_2;
end if;
fetch MYCURSOR bulk collect into OUT_TABLE;--将循环fetch改成了一次性fetch
CLOSE MYCURSOR;
return OUT_TABLE;
end;
/
--调用
SELECT * FROM TABLE(f_test_pipeline(1));
SELECT * FROM TABLE(f_test_pipeline(2));
关于MogDB MTK迁移工具
MTK全称为 Database Migration Toolkit,是一个可以将Oracle/DB2/MySQL/openGauss/SqlServer/Informix数据库的数据结构,全量数据高速导入到MogDB的工具。 最新版本同时支持对于Oracle/MySQL/DB2数据库中存储过程,函数,触发器等程序段的MogDB兼容性改写和导入。
多数据库类型支持
-
支持 Oracle,DB2,SqlServer,MySQL,Informix,PostgreSQL 到MogDB数据库的迁移。 -
支持将数据库内容导出成可执行的 SQL 脚本 (源数据库内容迁移到文本)。
迁移性能调整
-
支持调整数据迁移过程中的批量查询、批量插入大小等细粒度参数,来调整数据迁移的性能。 -
支持数据迁移时的多并发,并行和数据分片。
结构和数据分离
-
支持迁移对象结构和数据;也支持仅迁移结构或者仅迁移数据(在结构已经迁移完之后)。 -
支持表级和 Schema 级的迁移范围限定,允许指定schema下全部对象或者某些对象进行迁移 。 -
支持迁移过程中的 Schema 重映射,也就是支持将对象从源Schema迁移到目标端的不同名Schema下 。
程序迁移
-
支持Oracle/MySQL/DB2到MogDB/openGauss的存储过程,函数,触发器,包迁移并对语法进行改写。
迁移场景
源数据库 目标数据库
Oracle MogDB
Oracle openGauss
Oracle MySQL
Oracle PostgreSQL
MySQL MogDB
MySQL openGauss
MySQL PostgreSQL
DB2 MogDB
DB2 openGauss
DB2 MySQL
DB2 PostgreSQL
SqlServer MogDB
SqlServer openGauss
SqlServer MySQL
SqlServer PostgreSQL
PostgreSQL MogDB
PostgreSQL openGauss
Informix MogDB
Informix openGauss
参考:https://docs.mogdb.io/zh/mtk/v2.0/overview
本文由 mdnice 多平台发布
这篇关于2700+存储过程的超复杂Oracle,国产化怎么办?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







