本文主要是介绍Amazon Bedrock 实践:零基础创建贪吃蛇游戏,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文探讨了如何利用 Amazon Bedrock 和大型语言模型,快速创建经典的贪吃蛇游戏原型代码。重点展示了利用提示工程,将创新想法高效转化为可运行代码方面的过程。文章还介绍了评估和优化提示词质量的最佳实践。
亚马逊云科技开发者社区为开发者们提供全球的开发技术资源。这里有技术文档、开发案例、技术专栏、培训视频、活动与竞赛等。帮助中国开发者对接世界最前沿技术,观点,和项目,并将中国优秀开发者或技术推荐给全球云社区。如果你还没有关注/收藏,看到这里请一定不要匆匆划过,点这里让它成为你的技术宝库!
原文出处来自作者于 2024 年 8 月在 community.aws 发表的博客:
“From Concept to Playable in seconds:Creating the Greedy Snake Game with Amazon Bedrock”:https://huggingface.co/meta-llama/Meta-Llama-3.1-70B-Instruct?trk=cndc-detail
概述
在软件开发领域演进的历史长河中,开发者投入的时间一直是一种非常宝贵的资源。作为开发者,我们一直在不断地寻求创新的方法来简化工作流程、减少技术债务,并希望以提升开发的速度和效率将想法快速付诸实践。而生成式 AI(Generative AI)正是这一游戏规则的改变者,它有望彻底革新我们进行编码和解决问题的方式。
想象一下,你能够快速进行原型开发和概念验证,这已经是 Amazon Bedrock 这种生成式 AI 平台所能提供的现实了。通过利用在海量数据上训练的大型语言模型的强大能力,我们可以加速开发周期,并评估提示词的质量以获得最佳结果。
在这篇博客文章中,我将探讨如何利用 Amazon Bedrock,使用自然语言从零开始创建经典的贪吃蛇游戏。此外,我还将探讨如何进一步利用 Amazon Bedrock 上的大模型来评估和改进我的提示词,确保更高质量的代码输出。通过结合正确的提示词和合适的大模型,我们将目睹一个从创新想法到可玩游戏的完整生成之旅,而这一切只需几秒钟,这都归功于 Amazon Bedrock 能够简化原型设计,并实现快速概念验证。
让我们开始这段愉快的自然语言直接编写贪吃蛇游戏之旅吧!
使用的大型语言模型
我用于生成游戏代码的大型语言模型,采用了在 Amazon Bedrock 上的 Meta Llama 3.1 70B Instruct。
Amazon Bedrock 是一个强大的生成式 AI 平台,允许开发者为各种用例(包括代码生成等)创建和微调大型模型。而 Meta Llama 3.1 70B Instruct 模型专门用于遵循指令和生成高质量代码。你可以在 Hugging Face 上参考模型卡片以了解更多详情:https://huggingface.co/meta-llama/Meta-Llama-3.1-70B-Instruct?trk=cndc-detail
提示工程方法
成功使用生成式 AI 的关键之一在于提示工程(Prompt Engineering):即创建清晰、具体的提示词,以指导模型精确生成所需的输出。
以下是我用来生成贪吃蛇游戏代码的提示词:
“Write a short and high-quality python script for the following task, something a very skilled python expert would write. You are writing code for an experienced developer so only add comments for things that are non-obvious. Make sure to include any imports required.
NEVER write anything before the python block. After you are done generating the code and after the python block, check your work carefully to make sure there are no mistakes, errors, or inconsistencies.
If there are errors, list those errors in tags, then generate a new version with those errors fixed. If there are no errors, write "CHECKED:NO ERRORS" in tags.
Here is the task:write a greedy snake game.
Double check your work to ensure no errors or inconsistencies.”
正如你所看到的,这个提示词为游戏的功能、要使用的库以及其他实现细节提供了详细的要求。提供这种程度的明确性对于从生成式 AI 模型获得高质量的代码输出至关重要。
在 Amazon Bedrock Chat Playground 中,单击“Run”以将上述提示词提交给 Meta Llama 3.1 70B Instruct 模型,然后等待几秒钟模型的响应。如下截图所示:

输出:贪吃蛇游戏代码
输入提示词后,Amazon Bedrock 上的 Llama 3.1 70B Instruct 模型,在几秒内迅速生成了以下的 Python 代码,该代码基本实现了一个功能齐全的贪吃蛇游戏。生成的完整代码如下:
import pygame
import sys
import random# Initialize Pygame
pygame.init()# Set up some constants
WIDTH, HEIGHT = 800, 600
BLOCK_SIZE = 20
SPEED = 10# Set up some colors
WHITE = (255, 255, 255)
RED = (255, 0, 0)
GREEN = (0, 255, 0)# Set up the display
screen = pygame.display.set_mode((WIDTH, HEIGHT))# Set up the font
font = pygame.font.Font(None, 36)# Set up the snake and food
snake = [(200, 200), (220, 200), (240, 200)]
food = (400, 300)# Set up the direction
direction = 'RIGHT'# Game loop
while True:for event in pygame.event.get():if event.type == pygame.QUIT:pygame.quit()sys.exit()elif event.type == pygame.KEYDOWN:if event.key == pygame.K_UP and direction != 'DOWN':direction = 'UP'elif event.key == pygame.K_DOWN and direction != 'UP':direction = 'DOWN'elif event.key == pygame.K_LEFT and direction != 'RIGHT':direction = 'LEFT'elif event.key == pygame.K_RIGHT and direction != 'LEFT':direction = 'RIGHT'# Move the snakehead = snake[-1]if direction == 'UP':new_head = (head[0], head[1] - BLOCK_SIZE)elif direction == 'DOWN':new_head = (head[0], head[1] + BLOCK_SIZE)elif direction == 'LEFT':new_head = (head[0] - BLOCK_SIZE, head[1])elif direction == 'RIGHT':new_head = (head[0] + BLOCK_SIZE, head[1])snake.append(new_head)# Check if the snake has eaten the foodif snake[-1] == food:food = (random.randint(0, WIDTH - BLOCK_SIZE) // BLOCK_SIZE * BLOCK_SIZE,random.randint(0, HEIGHT - BLOCK_SIZE) // BLOCK_SIZE * BLOCK_SIZE)else:snake.pop(0)# Check if the snake has hit the edge or itselfif (snake[-1][0] < 0 or snake[-1][0] >= WIDTH orsnake[-1][1] < 0 or snake[-1][1] >= HEIGHT orsnake[-1] in snake[:-1]):pygame.quit()sys.exit()# Draw everythingscreen.fill(WHITE)for pos in snake:pygame.draw.rect(screen, GREEN, pygame.Rect(pos[0], pos[1], BLOCK_SIZE, BLOCK_SIZE))pygame.draw.rect(screen, RED, pygame.Rect(food[0], food[1], BLOCK_SIZE, BLOCK_SIZE))text = font.render(f'Score:{len(snake)}', True, (0, 0, 0))screen.blit(text, (10, 10))# Update the displaypygame.display.flip()# Cap the frame ratepygame.time.delay(1000 // SPEED)
该代码的主要功能实现包括:初始化 Pygame,设置游戏的尺寸、块大小和速度等常量、定义显示元素的颜色、初始化显示屏幕等等。代码还设置了用于显示得分(贪吃蛇每吃到一个食物将获得一分)的字体,初始化了蛇和食物的位置,以及设置了蛇移动的初始方向等游戏要素。
游戏会循环持续检查用户输入事件,如用户退出了游戏,或者使用了方向键改变蛇的运动方向等。游戏主要逻辑将根据用户输入以及蛇的当前方向,来更新蛇的位置,并同时检查与食物或边界的是否碰撞,从而决定是否更新相应分数等。此外,游戏的循环代码还处理了在屏幕上渲染游戏元素,并限制帧率。
以下图像显示了我实际调试代码的场景。以代码片段作为背景,前景是正在运行的游戏截图:
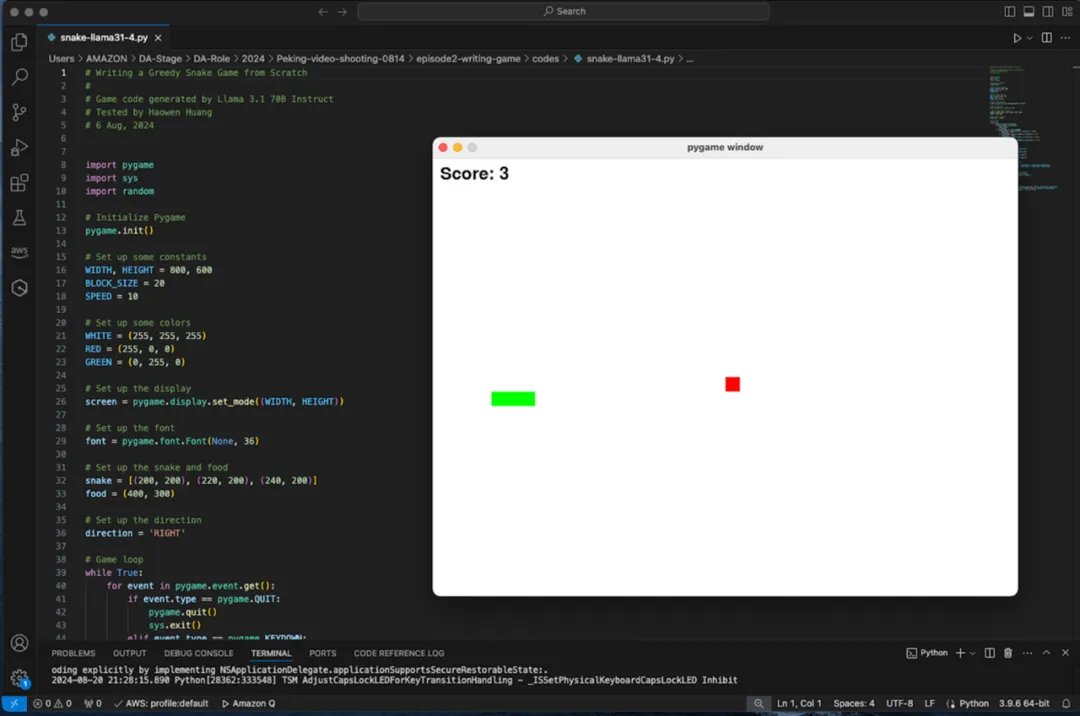
值得一提的是,这个全面且可执行的代码是根据一段文本提示词生成的,没有提供任何补充示例或训练数据。这展示了 Amazon Bedrock 上的该大语言模型(Llama 3.1 70B Instruct)具有将自然语言描述直接转化为完整代码的出色能力,从而节省了游戏开发者相比于从头开始编写游戏代码所需的大量时间。
当然生成的代码并非完美无缺,可能需要增强或扩展一些额外功能。但它确实为开发者提供了一个坚实的基础。
评估提示词的质量
虽然我们已经成功生成了贪吃蛇游戏的一份完整代码,但我还是想客观地评估使用的提示词质量,因为我考虑未来是否可以更好地使用 AI 来生成代码。
我所参考的标准来自《Generative AI on AWS》一书中总结的 16 项提示工程最佳实践。我已将这 16 项最佳实践纳入我的评估提示词中,以评估之前用于生成贪吃蛇游戏的提示词质量。
完整的评估提示词如下:
Here are the key prompt-engineering best practices discussed in Chapter 2 of the book “Generative AI on AWS”:
-
Be clear and concise in your prompts. Avoid ambiguity.
-
Move the instruction to the end of the prompt for large amounts of input text.
-
Clearly convey the subject using who, what, where, when, why, how etc.
-
Use explicit directives if you want output in a particular format.
-
Avoid negative formulations if a more straightforward phrasing exists.
-
Include context and few-shot example prompts to guide the model.
-
Specify the desired size of the response.
-
Provide a specific response format using an example.
-
Define what the model should do if it cannot answer confidently (e.g. respond "I don't know").
-
Ask the model to "think step-by-step" for complex prompts requiring reasoning.
-
Add constraints like maximum length or excluded information for more control.
-
Evaluate the model's responses and refine prompts as needed.
-
Use disclaimers or avoid prompts the model should not answer for sensitive domains.
-
Use XML/HTML tags to create structure within the prompt.
-
Focus the model on specific parts of the input text.
-
Mask personally identifiable information from the model's output.
Based on the above 16 prompt-engineering best practices, please evaluate the following prompts I used to generate a Greedy Snake Game:
“Write a short and high-quality python script for the following task, something a very skilled python expert would write. You are writing code for an experienced developer so only add comments for things that are non-obvious. Make sure to include any imports required.
NEVER write anything before the python block. After you are done generating the code and after the python block, check your work carefully to make sure there are no mistakes, errors, or inconsistencies.
If there are errors, list those errors in tags, then generate a new version with those errors fixed. If there are no errors, write "CHECKED:NO ERRORS" in tags.
Here is the task:write a greedy snake game.
Double check your work to ensure no errors or inconsistencies.”
我在 Amazon Bedrock Chat Playground 中提交了上述提示词,如下图所示:
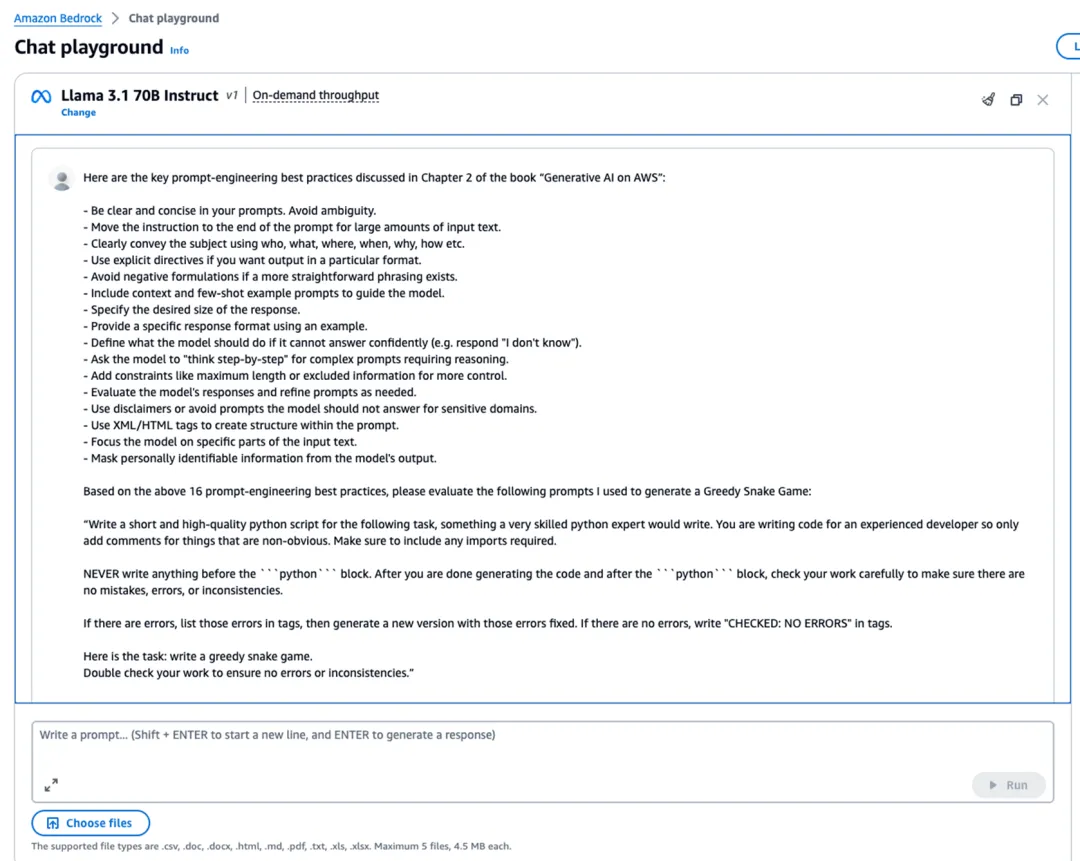
几秒钟后,收到了以下模型的完整评估输出:

模型输出提供了对我的提示词优点,以及潜在改进空间等非常有价值的见解。
首先,它在“优点”部分承认了我的提示语的优势:
-
明确简洁:你的提示语结构清晰,易于理解。
-
具体指示:你明确要求输出 Python 脚本格式和对高级别 Python 专家的期望水平。
-
上下文和少量示例提示语:你提供了一个明确的任务描述(贪吃蛇游戏)并指出了预期输出(高质量 Python 脚本)。
-
要求响应的大小:你要求一个“简短”的脚本。
-
具体响应格式:你使用
python块来指示预期格式。 -
错误处理:你指示模型检查其工作并列出错误,或者如果没有错误则写“CHECKED:NO ERRORS”。
此外模型还建议如“缺陷”部分所示,提出一些改进提示语的建议:
-
含糊不清:虽然你的提示语总体很清楚,但“一个非常熟练的 Python 专家会写的东西”这句话可能有些主观和含糊不清。
-
否定表述:你用了“千万不要在
python块之前写任何内容”,可以改为正面说法,例如“只能在python块中写代码”。 -
缺乏约束条件:你没有具体说明脚本的长度、复杂度或特定要求(如游戏功能、难度等级)的限制。
-
缺乏免责声明:你没有提及任何敏感领域或游戏内容可能存在的问题。
模型还提供了以下详细的代码修改具体建议:
-
考虑将“一个非常熟练的 Python 专家会写的东西”改为更客观的要求,如“遵循 Python 编码的最佳实践”。
-
用更积极的指示替换“千万不要在
python块之前写任何内容”,比如“只能在python块中写代码”。 -
添加约束条件,例如“脚本不应超过 200 行代码”或“游戏应至少有 3 个等级”。
-
考虑添加一个免责声明,如“请确保游戏内容适合所有年龄段,不含任何令人反感的材料”。
总结
生成式 AI 彻底改变软件开发的潜力是巨大的。通过利用 Amazon Bedrock 和大型语言模型,开发者目前已经可以继续简化工作流程,快速构建原型并验证伟大的想法,这将加快软件开发迭代速度,以前所未有的效率将想法变为现实。
贪吃蛇游戏的例子展示了生成式 AI 将一个简单的提示词,转化为可运行游戏代码的惊人能力。然而,我们必须认识到:虽然生成的代码可以提供一个良好的基础,但可能需要进一步的完善和优化。
随着生成式 AI 的不断发展,我们可以期待更先进的模型、更好的提示词技术,以及与开发工具的更紧密集成。提前拥抱这一技术将获得重大的竞争优势。
最后,生成式 AI 并不是要取代人类开发者,而是增强他们能力的强大工具。通过将人类创造力与人工智能相结合,我们可以开启创新的软件开发新前景,创造更加非凡的软件产品和解决方案。
注:本文封面图像使用了 Amazon Bedrock 上的 Stable Diffusion XL 1.0 模型生成。提示词如下:
“A stylized digital illustration with a futuristic and technology-inspired design, depicting a large coiled snake made of sleek metallic materials and circuit board patterns. The snake's body forms the shape of the Amazon Bedrock logo in the center. Surrounding the snake are various coding elements, such as code snippets, programming symbols, and binary patterns, arranged in an abstract and visually striking way. The overall image should convey a sense of innovation, artificial intelligence, and the fusion of technology and creativity”

文章来源:Amazon Bedrock 实践:零基础创建贪吃蛇游戏
这篇关于Amazon Bedrock 实践:零基础创建贪吃蛇游戏的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





