本文主要是介绍高并发业务下的库存扣减技术方案设计,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
扣减库存需要查询库存是否足够:
- 足够就占用库存
- 不够则返回库存不足(这里不区分库存可用、占用、已消耗等状态,统一成扣减库存数量,简化场景)
并发场景,若 查询库存和扣减库存不具备原子性,就可能超卖,而高并发场景超卖概率会增高,超卖数额也会增高。处理超卖的确麻烦:
- 系统全链路刷数会很麻烦(多团队协作),客服外呼也有额外成本
- 最主要原因,客户抢到订单又被取消,严重影响客户体验,甚至引发客诉产生公关危机
1.4.1 实现逻辑
常用方案redis+lua,借助redis单线程执行+lua脚本中的逻辑,可在一次执行中顺序完成的特性达到原子性(叫排它性更准确,因为不具备回滚动作,异常情况需自己手动编码回滚)。
lua脚本基本实现

-- 1. 获取库存缓存key KYES[1] = hot_{itemCode-skuCode}_stock
local hot_item_stock = KYES[1]-- 2. 获取剩余库存数量
local stock = tonumber(redis.call('get', hot_item_stock))-- 3. 购买数量
local buy_qty = tonumber(ARGV[1])-- 4. 如果库存小于购买数量,则返回1,表达库存不足
if stock < buy_qty thenreturn 1
end-- 5. 库存足够,更新库存数量
stock = stock - buy_qty
redis.call('set', hot_item_stock, tostring(stock))-- 6. 扣减成功则返回2,表达库存扣减成功
return 2但脚本还有一些问题:
不具备幂等性,同个订单多次执行会导致重复扣减,手动回滚也无法判断是否会回滚过,会出现重复增加的问题
不具备可追溯性,不知道库存被谁被哪个订单扣减了
增强后的lua脚本:
-- 1. 获取库存扣减记录缓存 key KYES[2] = hot_{itemCode-skuCode}_deduction_history
local hot_deduction_history = KYES[2]-- 2. 使用 Redis Cluster hash tag 保证 stock 和 history 在同一个槽
local exist = redis.call('hexists', hot_deduction_history, ARGV[2])
-- 3. 请求幂等判断,存在返回0,表达已扣减过库存
if exist == 1 then return 0 end-- 4. 获取库存缓存key KYES[1] = hot_{itemCode-skuCode}_stock
local hot_item_stock = KYES[1]-- 5. 获取剩余库存数量
local stock = tonumber(redis.call('get', hot_item_stock))-- 6. 购买数量
local buy_qty = tonumber(ARGV[1])-- 7. 如果库存小于购买数量 则返回1,表达库存不足
if stock < buy_qty then return 1 end-- 8. 库存足够
-- 9. 1.更新库存数量
-- 10. 2.插入扣减记录 ARGV[2] = ${扣减请求唯一key} - ${扣减类型} 值为 buy_qty
stock = stock - buy_qty
redis.call('set', hot_item_stock, tostring(stock))
redis.call('hset', hot_deduction_history, ARGV[2], buy_qty)-- 11. 如果剩余库存等于0则返回2,表达库存已为0
if stock == 0 then return 2 end-- 12. 剩余库存不为0返回 3 表达还有剩余库存
return 3 end利用Redis Cluster hash tag保证stock和history在同个槽,这样lua脚本才能正常执行。
因为正常要求 Lua 脚本操作的键必须在同一个 slot 中。
@Override public <T, R> RFuture<R> evalReadAsync(String key, Codec codec, RedisCommand<T> evalCommandType, String script, List<Object> keys, Object... params) {NodeSource source = getNodeSource(key);return evalAsync(source, true, codec, evalCommandType, script, keys, false, params); }private NodeSource getNodeSource(String key) {int slot = connectionManager.calcSlot(key);return new NodeSource(slot);}
利用hot_deduction_history,判断扣减请求是否执行过,以实现幂等性。
借助hot_deduction_history的V值判断追溯扣减来源,如:用户A的交易订单A的扣减请求,或用户B的借出单B的扣减请求。
回滚逻辑先判断hot_deduction_history里有没有 ${扣减请求唯一key}:
- 有,则执行回补逻辑
- 没有,则认定回补成功
但该逻辑依旧有漏洞,如(消息乱序消费),订单扣减库存超时成功触发了重新扣减库存,但同时订单取消触发了库存扣减回滚,回滚逻辑先成功,超时成功的重新扣减库存就会成为脏数据留在redis里。
1.4.2 处理方案
有两种:
- 追加对账,定期校验hot_deduction_history中数据对应单据的状态,对于已经取消的单据追加一次回滚请求,存在时延(业务不一定接受)以及额外计算资源开销
- 使用顺序消息,让扣减库存、回滚库存都走同一个MQ topic的有序队列,借助MQ消息的有序性保证回滚动作一定在扣减动作后面执行,但有序串行必然带来性能下降
1.4.3 高可用
Redis终究是内存,一旦服务中断,数据就消失。所以需要追加保护数据不丢失的方案。
运用Redis部署的高可用方案:
- 采用Redis Cluster(数据分片+ 多副本 + 同步多写 + 主从自动选举)
- 多写节点分(同城异地)多中心防止意外灾害
定期归档冷数据。定期 + 库存为0触发redis数据往DB同步,流程如下:
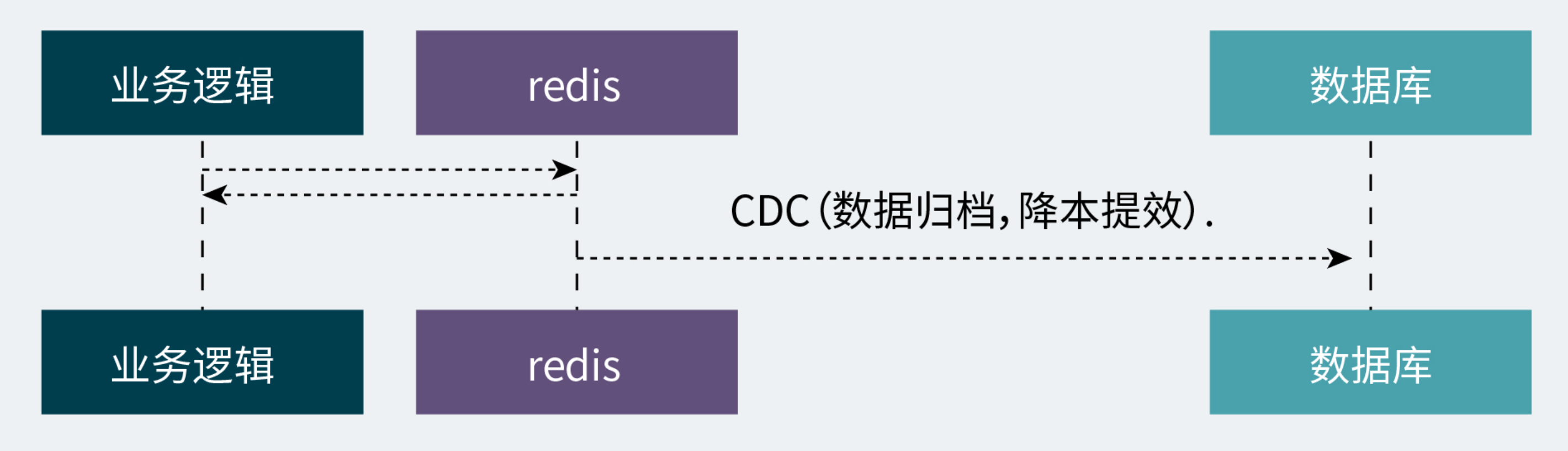
CDC分发数据时,秒杀商品,hot_deduction_history的数据量不高,可以一次全量同步。但如果是普通大促商品,就需要再追加一个map动作分批处理,以保证每次执行CDC的数据量恒定,不至于一次性数据量太大出现OOM。代码如下:
/*** 对任务做分发* @param stockKey 目标库存的key值*/
public void distribute(String stockKey) {final String historyKey = StrUtil.format("hot_{}_deduction_history", stockKey);// 获取指定库存key 所有扣减记录的key(生产请分页获取,防止数据量太多)final List<String> keys = RedisUtil.hkeys(historyKey, stockKey);// 以 100 为大小,分片所有记录keyfinal List<List<String>> splitKeys = CollUtil.split(keys, 100);// 将集合分发给各个节点执行map(historyKey, splitKeys);
}/*** 对单页任务做执行* @param historyKey 目标库存的key值* @param stockKeys 要执行的页面大小*/
public void mapExec(String historyKey, List<String> stockKeys) {// 获取指定库存key 指定扣减记录 的mapfinal Map<String, String> keys = RedisUtil.HmgetToMap(historyKey, stockKeys);keys.entrySet().stream().map(stockRecordFactory::of).forEach(stockRecord -> {// (幂等 + 去重) 扣减 + 保存记录stockConsumer.exec(stockRecord);// 删除redis中的 key 释放空间RedisUtil.hdel(historyKey, stockRecord.getRecordRedisKey());});
}1.4.4 为啥不走DB
商品库存数据在DB最终会落到单库单表的一行数据。无法通过分库分表提高请求的并行度。而在单节点场景,数据库吞吐远不如Redis。最基础的原因:IO效率不是一个量级,DB是磁盘操作,而且还可能要多次读盘,Redis是一步到位的内存操作。
同时,一般DB都是提交读隔离级别,为保证原子性,执行库存扣减,得加锁,无论悲观乐观。不仅性能差(抢不到锁要等待),而且因为非公平竞争,易出现线程饥饿。而redis是单线程操作,不存在共享变量竞争。
有些优化思路,如合并扣减,走批降低请求的并行连接数。但伴随的集单的时延,以及按库分批的诉求;还有拆库存行,商品A100个库存拆成2行商品A50库存,然后扣减时分发请求,以提高并行连接数(多行可落在不同库来提高并行连接数)。但伴随的:
- 复杂的库存行拆分管理(把什么库存行在什么时候拆分到哪些库)
- 部分库存行超卖的问题(加锁优化就又串行了,不加总量还有库存,个别库存行不足是允许一定系数超卖还是返回库存不足就是一个要决策的问题)
部分头部电商采用弱缓存抗读(非库存不足,不实时更新),DB抗写的方案。该方案前提在于,通过一系列技术方案,流量落到库存已相对低且平滑了(扛得住,不用再自己实现操作原子性)。
关注我,紧跟本系列专栏文章,咱们下篇再续!
作者简介:魔都架构师,多家大厂后端一线研发经验,在分布式系统设计、数据平台架构和AI应用开发等领域都有丰富实践经验。
各大技术社区头部专家博主。具有丰富的引领团队经验,深厚业务架构和解决方案的积累。
负责:
中央/分销预订系统性能优化
活动&券等营销中台建设
交易平台及数据中台等架构和开发设计
车联网核心平台-物联网连接平台、大数据平台架构设计及优化
LLM Agent应用开发
区块链应用开发
大数据开发挖掘经验
推荐系统项目
目前主攻市级软件项目设计、构建服务全社会的应用系统。
参考:
- 编程严选网
本文由博客一文多发平台 OpenWrite 发布!
这篇关于高并发业务下的库存扣减技术方案设计的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




