本文主要是介绍如何抓取网站页面内容,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
很多时候,我们想获取一些网页的内容,可以运用以下几种方法:
HTTPCLIENT
get方法:
HttpClient httpClient = new HttpClient(); GetMethod getMethod = new GetMethod("http://www.baidu.com/"); try { int statusCode = httpClient.executeMethod(getMethod); if (statusCode != HttpStatus.SC_OK) { System.err.println("Method failed: " + getMethod.getStatusLine()); } // 读取内容 byte[] responseBody = getMethod.getResponseBody(); // 处理内容 String html = new String(responseBody); System.out.println(html); } catch (Exception e) { System.err.println("页面无法访问"); }finally{ getMethod.releaseConnection(); } post方法:
HttpClient httpClient = new HttpClient(); PostMethod postMethod = new PostMethod(UrlPath); postMethod.getParams().setParameter(HttpMethodParams.RETRY_HANDLER,new DefaultHttpMethodRetryHandler()); NameValuePair[] postData = new NameValuePair[2]; postData[0] = new NameValuePair("username", "xkey"); postData[1] = new NameValuePair("userpass", "********"); postMethod.setRequestBody(postData); try { int statusCode = httpClient.executeMethod(postMethod); if (statusCode == HttpStatus.SC_OK) { byte[] responseBody = postMethod.getResponseBody(); String html = new String(responseBody); System.out.println(html); } } catch (Exception e) { System.err.println("页面无法访问"); }finally{ postMethod.releaseConnection(); }
wget命令
使用命令: wget -c -r -np -k -p http://blog.csdn.net/lifen0908/article/details/45866853
具体使用命令:官网文档
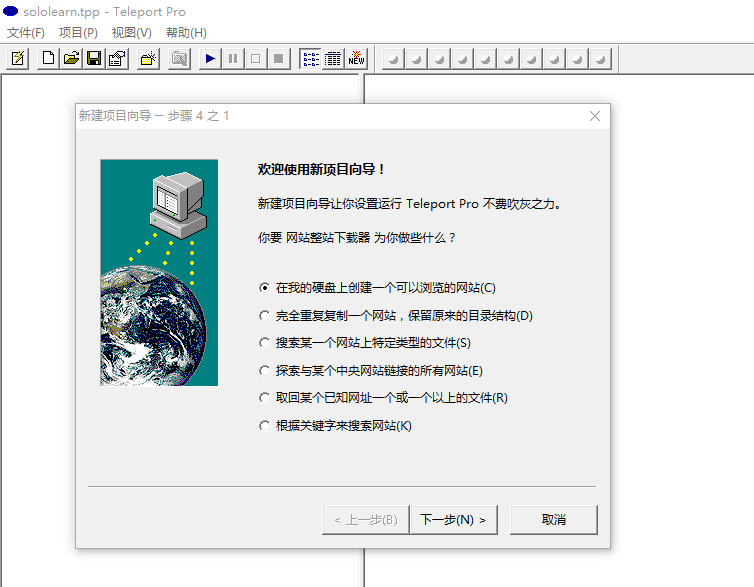
Teleport Pro软件
安装之后直接文件-新项目向导,下一步下一步,填上网址。然后点击标签run就可以了。具体软件下载地址:Teleport Pro
这篇关于如何抓取网站页面内容的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




