本文主要是介绍【Git之窗】(九)Sparse checkout解决pull远程库特定文件失败问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
零、业务场景
公司开发前后端分离的图书管理系统"Library System",其中前端代码、后端代码、原型图,被设计放到了同一个GitLab仓库中(公司之前使用SVN做VCS控制),当远程Repository中代码越来越多的时候,“前端同事A”发现:为什么每次git pull origin master之后,会拉取很多后端代码的更新,“后端同事B”也困惑:为什么我是在后端路径(非git本地仓库根路径)下拉取代码,却拉取了许多原型图的更新??心疼内存啊!!!
如上,是今天早晨在公司里遇到的问题,由于同事们刚刚从SVN切到Git,对于SVN仅仅Check out子文件夹中的代码使用的得心应手,发现Git竟然在这里竟然有这样的问题,很是不解。小编开始也是一头雾水,思路慢慢清晰后通过强大的Google解决了这个问题,现在对此做个分析。一、对比SVN和Git仅仅拉取“项目子文件”
(1)SVN
svn是基于文件方式的集中存储,天生支持从集中存储的库中拉取单个子文件。
(2)GitGit基于元数据方式分布式存储文件信息的,它会在每一次Clone的时候将所有信息都取回到本地,即相当于在你的机器上生成一个克隆版的版本库。
如上所述,也就解释了从SVN转到Git之后,不能拉取单个文件的问题了。
二、Sparse checkout介绍
在官方的一个文档中介绍了“Sparse checkout”,链接如下:https://schacon.github.io/git/git-read-tree.html#_sparse_checkout ,其中讲到:
"Sparse checkout" allows to sparsely populate working directory. It uses skip-worktree bit (see git-update-index(1)) to tell Git whether a file on working directory is worth looking at.
"git read-tree" and other merge-based commands ("git merge", "git checkout"…) can help maintaining skip-worktree bitmap and working directory update. $GIT_DIR/info/sparse-checkout is used to define the skip-worktree reference bitmap. When "git read-tree" needs to update working directory, it will reset skip-worktree bit in index based on this file, which uses the same syntax as .gitignore files. If an entry matches a pattern in this file, skip-worktree will be set on that entry. Otherwise, skip-worktree will be unset.
Then it compares the new skip-worktree value with the previous one. If skip-worktree turns from unset to set, it will add the corresponding file back. If it turns from set to unset, that file will be removed.
While $GIT_DIR/info/sparse-checkout is usually used to specify what files are in. You can also specify what files are not in, using negate patterns. For example, to remove file "unwanted":
*
!unwanted*Then you can disable sparse checkout. Sparse checkout support in "git read-tree" and similar commands is disabled by default. You need to turn core.sparseCheckout on in order to have sparse checkout support.
据此,我了解到,通过使用“Sparse checkout”可以实现在SVN中检出单个文件的功能,原理就在上文中哦~~~
注意:只有git版本在1.7.0及其以上才可以使用!!!
三、Sparse checkout实验
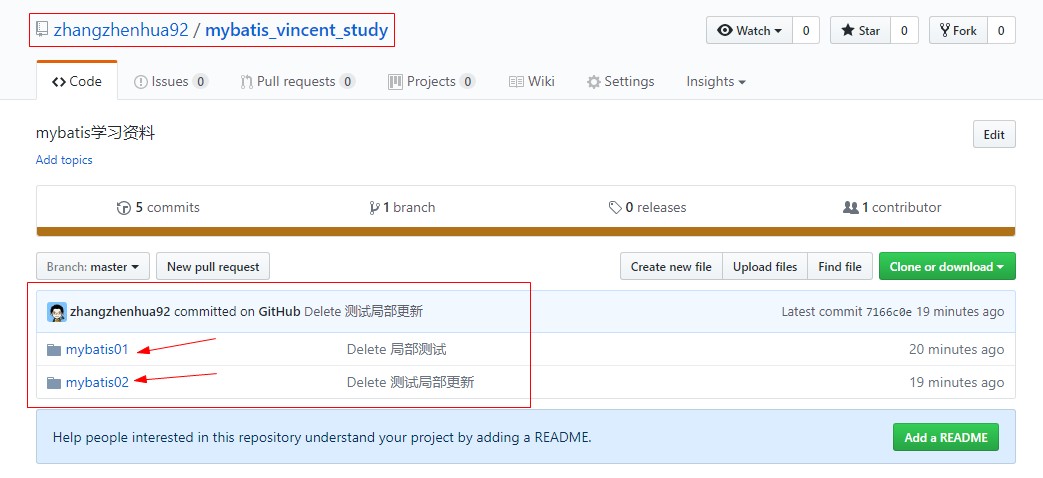
如图,是我最近托管的一个项目:
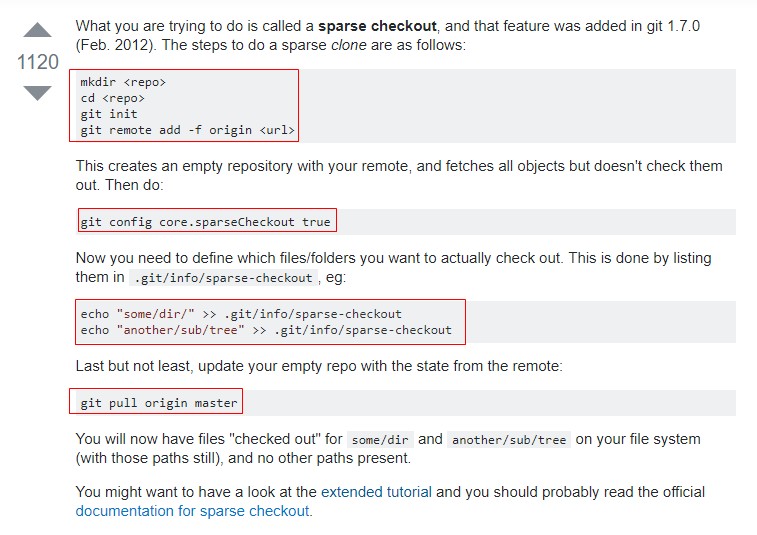
这个名为“mybatis_vincent_study”的repository中,有mybatis01和mybatis02两个单独的项目,现在我仅仅想clone下来repository中的mybatis01,我想利用“sparse checkout”方法来做,在stackoverflow中搜索到了一个操作办法,链接:https://stackoverflow.com/questions/600079/how-do-i-clone-a-subdirectory-only-of-a-git-repository,如图(这是在linux中的操作,经过测试windows同样适用):
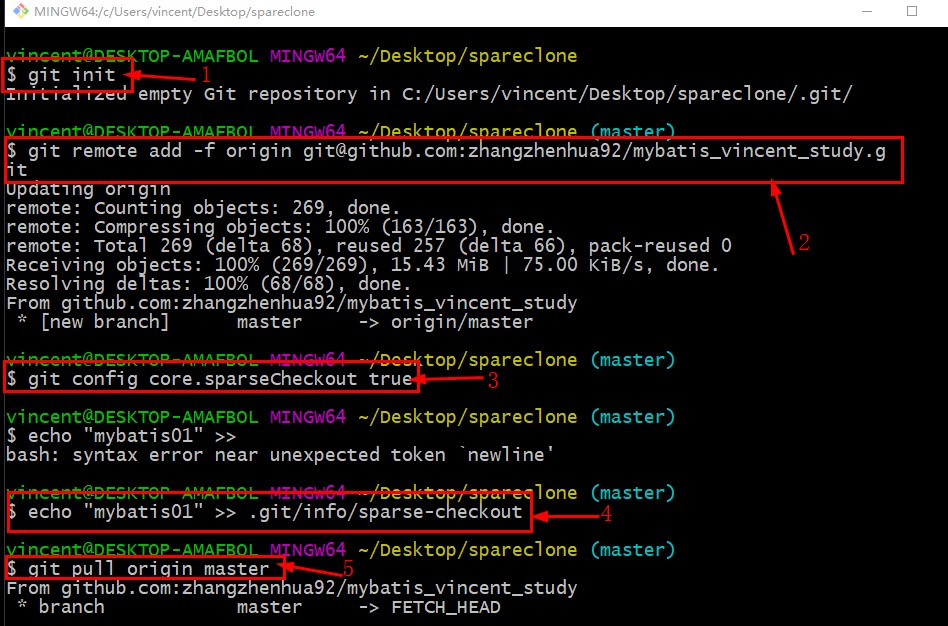
按照其中的配置,我做了如下操作,如图:
其中一共5个步骤,分别进行分析:
(1)在指定的文件夹下,创建一个空的repository。
(2)获取远程仓库中的所有对象,但不Check out它们到本地,同时将远程Git Server URL加入到Git Config文件中,这个过程会耗时多一点,如果项目比较大。
(3)在Config中允许使用Sparse Checkout模式。
(4)定义要实际检出的文件/文件夹。这是通过在列表中借助“.git/info/sparse-checkout”将他们列出。
(5)见证奇迹的时刻,从远程库中拉取你要检出的项目。
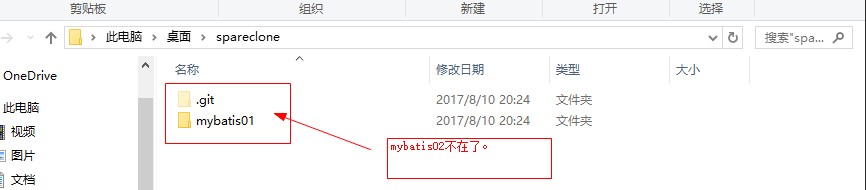
刷新我的本地仓库,如图:
验证成功!
四、sparse checkout的应用场景
个人或者公司通过git托管项目,有时候项目很多,但是都不大,单独为每个项目创建一个repository又不值得,这个时候,可以把相似功能的项目抽到一个repository当中,这个时候,可以通过sparse checkout来实现我们所要的功能。
五、缺点
暂时Google上没有搜到使用sparse checkout的缺点,我个人猜测即使出问题,会出在数据同步、一致性上,这一点还有待观察。
六、补充
由于图书管理系统是前后端分离的,前端代码和原型图可以捆绑在一起,放到一个repository当中,后端代码单独托管到一个repository当中,也是一个非常好的解决办法,今天遇到的问题,其实就是repository中项目粒度的划分问题,多几次这样的实践,以后经验就更丰富了。
这篇关于【Git之窗】(九)Sparse checkout解决pull远程库特定文件失败问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








