本文主要是介绍Clickhouse集群化(三)集群化部署,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 准备
clickhouse支持副本和分片的能力,但是自身无法实现需要借助zookeeper或者clickhouse-operator来实现不同节点之间数据同步,同时clickhouse的数据是最终一致性 。
2. Zookeeper
副本的写入流程
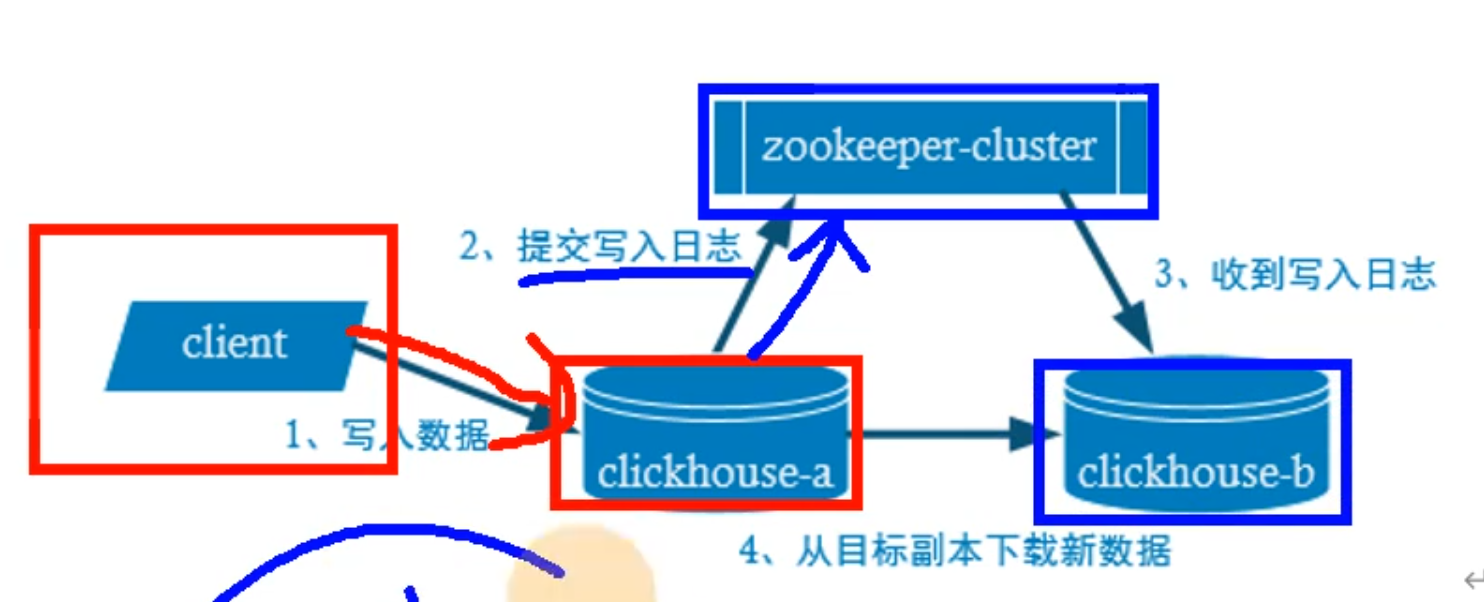
没有主从概念 平等地位 互为副本
2.1. 部署zookeeper
# Setup Service to provide access to Zookeeper for clients
apiVersion: v1
kind: Service
metadata:# DNS would be like zookeeper.zoonsname: zookeeperlabels:app: zookeeper
spec:ports:- port: 2181name: client- port: 7000name: prometheusselector:app: zookeeperwhat: node
---
# Setup Headless Service for StatefulSet
apiVersion: v1
kind: Service
metadata:# DNS would be like zookeeper-0.zookeepers.etcname: zookeeperslabels:app: zookeeper
spec:ports:- port: 2888name: server- port: 3888name: leader-electionclusterIP: Noneselector:app: zookeeperwhat: node
---
# Setup max number of unavailable pods in StatefulSet
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:name: zookeeper-pod-disruption-budget
spec:selector:matchLabels:app: zookeepermaxUnavailable: 1
---
# Setup Zookeeper StatefulSet
# Possible params:
# 1. replicas
# 2. memory
# 3. cpu
# 4. storage
# 5. storageClassName
# 6. user to run app
apiVersion: apps/v1
kind: StatefulSet
metadata:# nodes would be named as zookeeper-0, zookeeper-1, zookeeper-2name: zookeeperlabels:app: zookeeper
spec:selector:matchLabels:app: zookeeperserviceName: zookeepersreplicas: 2updateStrategy:type: RollingUpdatepodManagementPolicy: OrderedReadytemplate:metadata:labels:app: zookeeperwhat: nodeannotations:prometheus.io/port: '7000'prometheus.io/scrape: 'true'spec:affinity:podAntiAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: "app"operator: Invalues:- zookeeper# TODO think about multi-AZ EKS# topologyKey: topology.kubernetes.io/zonetopologyKey: "kubernetes.io/hostname"containers:- name: kubernetes-zookeeperimagePullPolicy: IfNotPresentimage: "zookeeper:3.8.4"resources:requests:memory: "512M"cpu: "1"limits:memory: "4Gi"cpu: "2"ports:- containerPort: 2181name: client- containerPort: 2888name: server- containerPort: 3888name: leader-election- containerPort: 7000name: prometheusenv:- name: SERVERSvalue: "3"# See those links for proper startup settings:
# https://github.com/kow3ns/kubernetes-zookeeper/blob/master/docker/scripts/start-zookeeper
# https://clickhouse.yandex/docs/en/operations/tips/#zookeeper
# https://github.com/ClickHouse/ClickHouse/issues/11781command:- bash- -x- -c- |HOST=`hostname -s` &&DOMAIN=`hostname -d` &&CLIENT_PORT=2181 &&SERVER_PORT=2888 &&ELECTION_PORT=3888 &&PROMETHEUS_PORT=7000 &&ZOO_DATA_DIR=/var/lib/zookeeper/data &&ZOO_DATA_LOG_DIR=/var/lib/zookeeper/datalog &&{echo "clientPort=${CLIENT_PORT}"echo 'tickTime=2000'echo 'initLimit=300'echo 'syncLimit=10'echo 'maxClientCnxns=2000'echo 'maxTimeToWaitForEpoch=2000'echo 'maxSessionTimeout=60000000'echo "dataDir=${ZOO_DATA_DIR}"echo "dataLogDir=${ZOO_DATA_LOG_DIR}"echo 'autopurge.snapRetainCount=10'echo 'autopurge.purgeInterval=1'echo 'preAllocSize=131072'echo 'snapCount=3000000'echo 'leaderServes=yes'echo 'standaloneEnabled=false'echo '4lw.commands.whitelist=*'echo 'metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider'echo "metricsProvider.httpPort=${PROMETHEUS_PORT}"echo "skipACL=true"echo "fastleader.maxNotificationInterval=10000"} > /conf/zoo.cfg &&{echo "zookeeper.root.logger=CONSOLE"echo "zookeeper.console.threshold=INFO"echo "log4j.rootLogger=\${zookeeper.root.logger}"echo "log4j.appender.CONSOLE=org.apache.log4j.ConsoleAppender"echo "log4j.appender.CONSOLE.Threshold=\${zookeeper.console.threshold}"echo "log4j.appender.CONSOLE.layout=org.apache.log4j.PatternLayout"echo "log4j.appender.CONSOLE.layout.ConversionPattern=%d{ISO8601} - %-5p [%t:%C{1}@%L] - %m%n"} > /conf/log4j.properties &&echo 'JVMFLAGS="-Xms128M -Xmx4G -XX:ActiveProcessorCount=8 -XX:+AlwaysPreTouch -Djute.maxbuffer=8388608 -XX:MaxGCPauseMillis=50"' > /conf/java.env &&if [[ $HOST =~ (.*)-([0-9]+)$ ]]; thenNAME=${BASH_REMATCH[1]} &&ORD=${BASH_REMATCH[2]};elseecho "Failed to parse name and ordinal of Pod" &&exit 1;fi &&mkdir -pv ${ZOO_DATA_DIR} &&mkdir -pv ${ZOO_DATA_LOG_DIR} &&whoami &&chown -Rv zookeeper "$ZOO_DATA_DIR" "$ZOO_DATA_LOG_DIR" &&export MY_ID=$((ORD+1)) &&echo $MY_ID > $ZOO_DATA_DIR/myid &&for (( i=1; i<=$SERVERS; i++ )); doecho "server.$i=$NAME-$((i-1)).$DOMAIN:$SERVER_PORT:$ELECTION_PORT" >> /conf/zoo.cfg;done &&if [[ $SERVERS -eq 1 ]]; thenecho "group.1=1" >> /conf/zoo.cfg;elseecho "group.1=1:2:3" >> /conf/zoo.cfg;fi &&for (( i=1; i<=$SERVERS; i++ )); doWEIGHT=1if [[ $i == 1 ]]; thenWEIGHT=10fiecho "weight.$i=$WEIGHT" >> /conf/zoo.cfg;done &&zkServer.sh start-foregroundreadinessProbe:exec:command:- bash- -c- 'IFS=; MNTR=$(exec 3<>/dev/tcp/127.0.0.1/2181 ; printf "mntr" >&3 ; tee <&3; exec 3<&- ;);while [[ "$MNTR" == "This ZooKeeper instance is not currently serving requests" ]];doecho "wait mntr works";sleep 1;MNTR=$(exec 3<>/dev/tcp/127.0.0.1/2181 ; printf "mntr" >&3 ; tee <&3; exec 3<&- ;);done;STATE=$(echo -e $MNTR | grep zk_server_state | cut -d " " -f 2);if [[ "$STATE" =~ "leader" ]]; thenecho "check leader state";SYNCED_FOLLOWERS=$(echo -e $MNTR | grep zk_synced_followers | awk -F"[[:space:]]+" "{print \$2}" | cut -d "." -f 1);if [[ "$SYNCED_FOLLOWERS" != "0" ]]; then./bin/zkCli.sh ls /;exit $?;elseexit 0;fi;elif [[ "$STATE" =~ "follower" ]]; thenecho "check follower state";PEER_STATE=$(echo -e $MNTR | grep zk_peer_state);if [[ "$PEER_STATE" =~ "following - broadcast" ]]; then./bin/zkCli.sh ls /;exit $?;elseexit 1;fi;elseexit 1; fi'initialDelaySeconds: 10periodSeconds: 60timeoutSeconds: 60livenessProbe:exec:command:- bash- -xc- 'date && OK=$(exec 3<>/dev/tcp/127.0.0.1/2181 ; printf "ruok" >&3 ; IFS=; tee <&3; exec 3<&- ;); if [[ "$OK" == "imok" ]]; then exit 0; else exit 1; fi'initialDelaySeconds: 10periodSeconds: 30timeoutSeconds: 5volumeMounts:- name: datadir-volumemountPath: /var/lib/zookeeper# Run as a non-privileged usersecurityContext:runAsUser: 1000fsGroup: 1000volumes:- name: datadir-volumeemptyDir:medium: "" #accepted values: empty str (means node's default medium) or MemorysizeLimit: 1Gi

3. 借助多副本模式部署clickhouse
clickhouse-operator可以只通过配置标签来部署集群化clickhouse
尝试使用部署多个pod的方式+zookeeper来进行数据同步与分片
3.1. 多副本
修改副本数:3
修改pod亲和:使得不通pod分不到不同node节点中
---
apiVersion: apps/v1
kind: StatefulSet
metadata:name: clickhouselabels:app: clickhousenamespace: default
spec:replicas: 3serviceName: clickhouseselector:matchLabels:app: clickhousetemplate:metadata:labels:app: clickhousespec:containers:- name: clickhouseimage: clickhouse/clickhouse-server:24.1.2.5imagePullPolicy: IfNotPresentenv:- name: TZvalue: "Asia/Shanghai"ports:- containerPort: 8123protocol: TCPvolumeMounts:- mountPath: /var/lib/clickhousename: clickhouse-data- mountPath: /etc/clickhouse-server/config.dname: clickhouse-config- mountPath: /etc/clickhouse-server/conf.dname: clickhouse-conf- mountPath: /etc/clickhouse-server/users.dname: clickhouse-usersaffinity:nodeAffinity:requiredDuringSchedulingIgnoredDuringExecution:nodeSelectorTerms:- matchExpressions:- key: kubernetes.io/hostnameoperator: Invalues:- "master"- "node1"- "node2"- "node3"podAntiAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: appoperator: Invalues:- clickhousetopologyKey: "kubernetes.io/hostname"volumes:- name: clickhouse-dataemptyDir: {}- hostPath:path: /apps/data/gzzx/clickhouse2/config/config.dname: clickhouse-config- hostPath:path: /apps/data/gzzx/clickhouse2/config/conf.dname: clickhouse-conf- hostPath:path: /apps/data/gzzx/clickhouse2/config/users.dname: clickhouse-users
---
apiVersion: v1
kind: Service
metadata:labels:app: clickhousename: clickhousenamespace: default
spec:ipFamilies:- IPv4# - IPv6ipFamilyPolicy: PreferDualStacktype: NodePort # 将类型修改为 NodePortports:- port: 8123 #服务端口protocol: TCPtargetPort: 8123nodePort: 31125selector:app: clickhouse3.2. clickhouse配置信息
使用k8s部署时 需要使用挂载的方式来修改clickhouse中的配置信息 因为需要修改配置信息较多 采用文件目录挂载的方式
clickhouse配置挂载目录 /etc/clickhouse-server/conf.d
/etc/clickhouse-server/config.d
用户配置:/etc/clickhouse-server/users.d
共需要修改的地方
zookeeper信息
macros:宏信息 可以在建表的时候帮助自动生成相关副本信息
remote_servers:clickhosue集群信息(分片 副本等)
user:用户信息
3.2.1. zookeeper配置信息
host使用k8s默认的coreDns zookeeper使用statefulset方式创建
podname.service.namespace.svc.cluster.local
<yandex><zookeeper><node><host>zookeeper-0.zookeepers.default.svc.cluster.local</host><port>2181</port></node><node><host>zookeeper-1.zookeepers.default.svc.cluster.local</host><port>2181</port></node></zookeeper><distributed_ddl><path>/clickhouse/ck-cluster2/task_queue/ddl</path></distributed_ddl>
</yandex>3.2.2. 集群副本配置
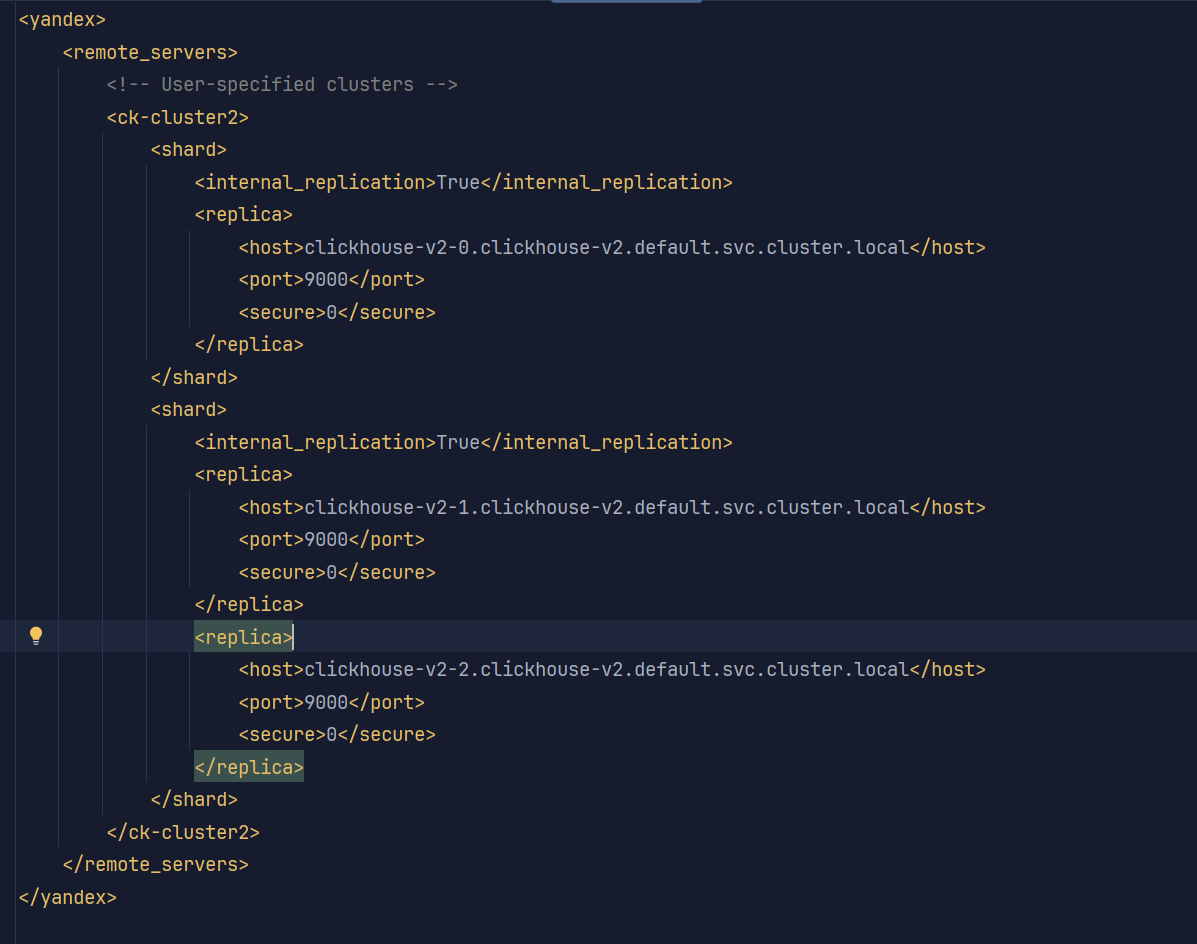
副本和分片配置信息 <shard> <replica>
host信息为 podname+service+namespace.svc.cluster.local
remote_servers下面的标签名表示定义的集群名 ck-cluster
多副本就在shard中指定多个replica 其中host表示不同pod节点
多分片就定义多个shard标签
<yandex><remote_servers><!-- User-specified clusters --><ck-cluster><shard><internal_replication>True</internal_replication><replica><host>clickhouse-v2-0.clickhouse-v2.default.svc.cluster.local</host><port>9000</port><secure>0</secure></replica><replica><host>clickhouse-v2-1.clickhouse-v2.default.svc.cluster.local</host><port>9000</port><secure>0</secure></replica></shard></ck-cluster></remote_servers>
</yandex>3.2.3. 宏设置
这样我们分布式表的时候会自动根据这里面的宏信息进行命名 避免手动指定
这里面所有的涉及到集群信息的配置 在不同机器上需要不同 如replica shard
如果有分片设置 啧shard参数需要修改 不然创建表会有问题
如果有副本设置 则replica值需要不同
<yandex><macros><installation>ck-cluster</installation><all-sharded-shard>0</all-sharded-shard><cluster>ck-cluster</cluster><shard>0</shard><replica>replica1</replica></macros>
</yandex>
3.2.4. 监听配置
ipv4使用0.0.0.0
ipv6使用 [::]
<yandex><!-- Listen wildcard address to allow accepting connections from other containers and host network. --><listen_host>0.0.0.0</listen_host><listen_try>1</listen_try>
</yandex>
3.2.5. hostanme
如果不指定 clickhouse部署时候会自动生成
<yandex><tcp_port_secure>0</tcp_port_secure><https_port>0</https_port>
</yandex>
3.2.6. 用户信息配置
自定一个用户使用 user2标签即为用户名 也可以定义其他
password支持sha256加密
也可以直接使用<password>标签明文指定
<yandex><users><user2><networks><ip>::1</ip><ip>127.0.0.1</ip><ip>::/0</ip></networks><password_sha256_hex>65e84be33532fb784c48129675f9eff3a682b27168c0ea744b2cf58ee02337c5</password_sha256_hex><profile>default</profile><quota>default</quota></user2></users>
</yandex>
3.2.7. 其他配置
日志配置等
查看clickhouse中服务启动情况
cat /var/log/clickhouse-server/clickhouse-server.log
3.3. 配置步骤
(4)集群同步
通过yaml挂载config.d目录 将自定义配置文件 写入pod
(5)apply部署
3.4. 创建表
副本只能同步数据,不能同步表结构,所以需要在每台机器上自己手动建表
或者借助集群创建表 ck-cluster是我们在集群配置里面的标签名
create table test on cluster 'ck-cluster' (id UInt32,sku_id String,total_amount Decimal(16,2),create_time Datetime
) engine =ReplicatedMergeTreepartition by toYYYYMMDD(create_time)primary key (id)order by (id,sku_id);insert into test values
(101,'sku_001',1000.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 12:00:00'),
(103,'sku_004',2500.00,'2020-06-01 12:00:00'),
(104,'sku_002',2000.00,'2020-06-01 12:00:00'),
(105,'sku_003',600.00,'2020-06-02 12:00:00');执行插入 查看不同副本数据信息
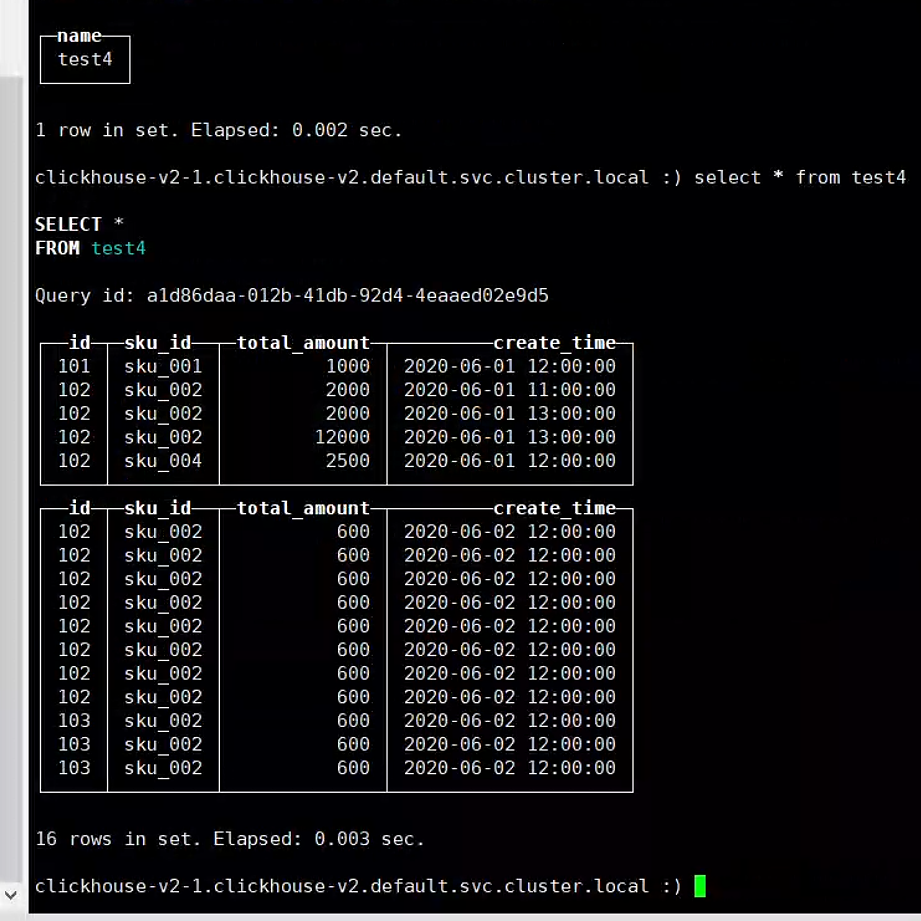
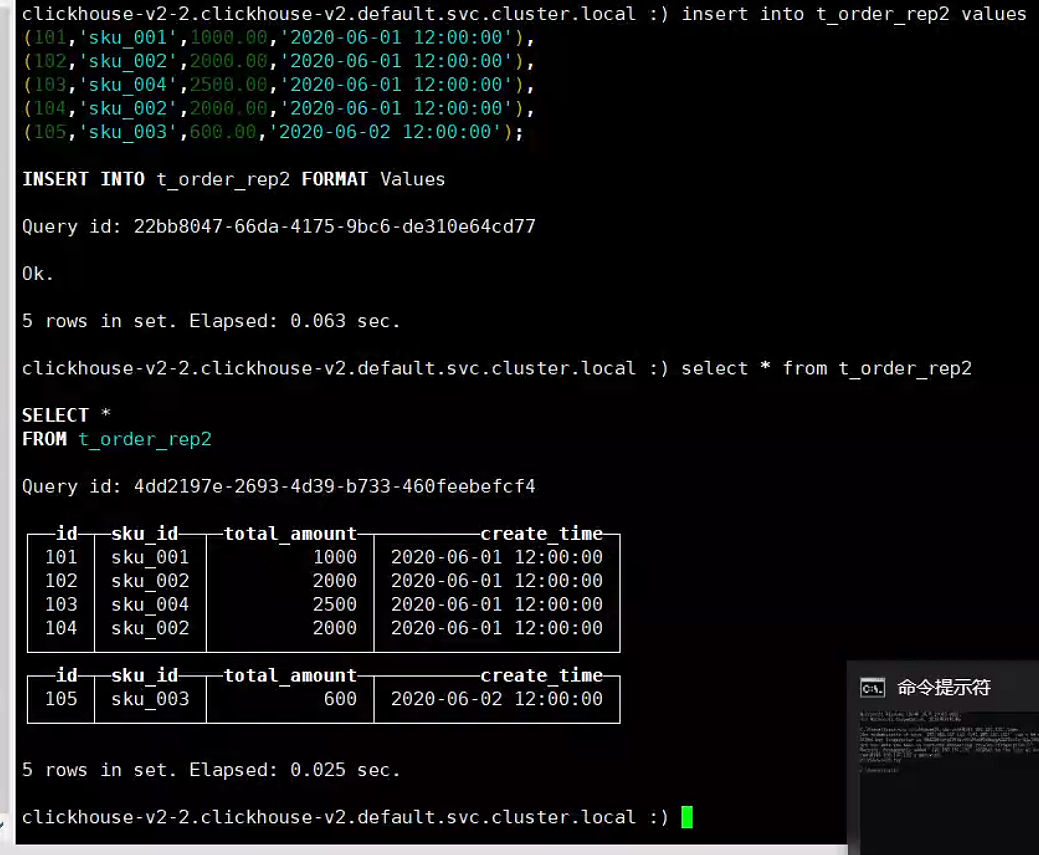
副本测试成功
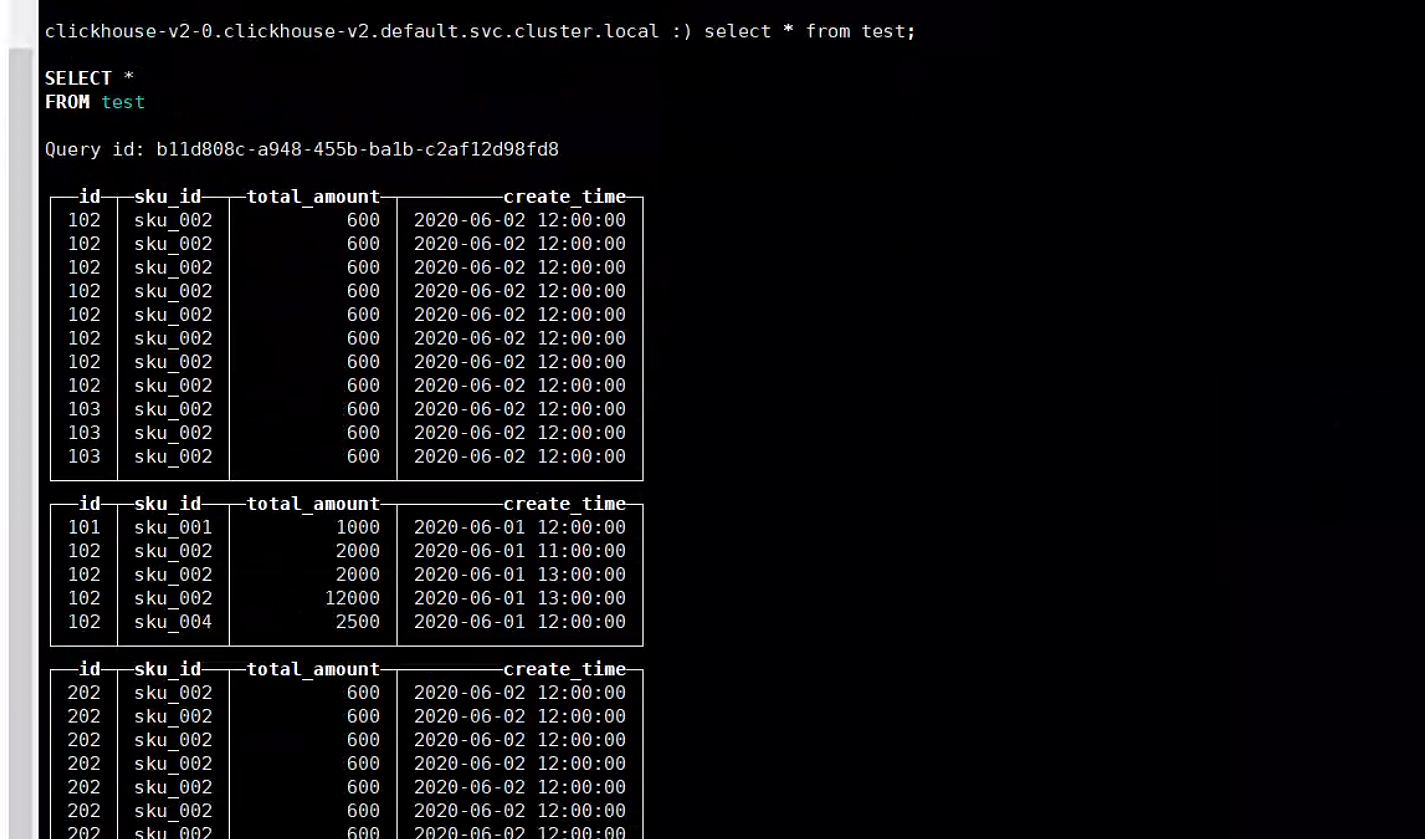
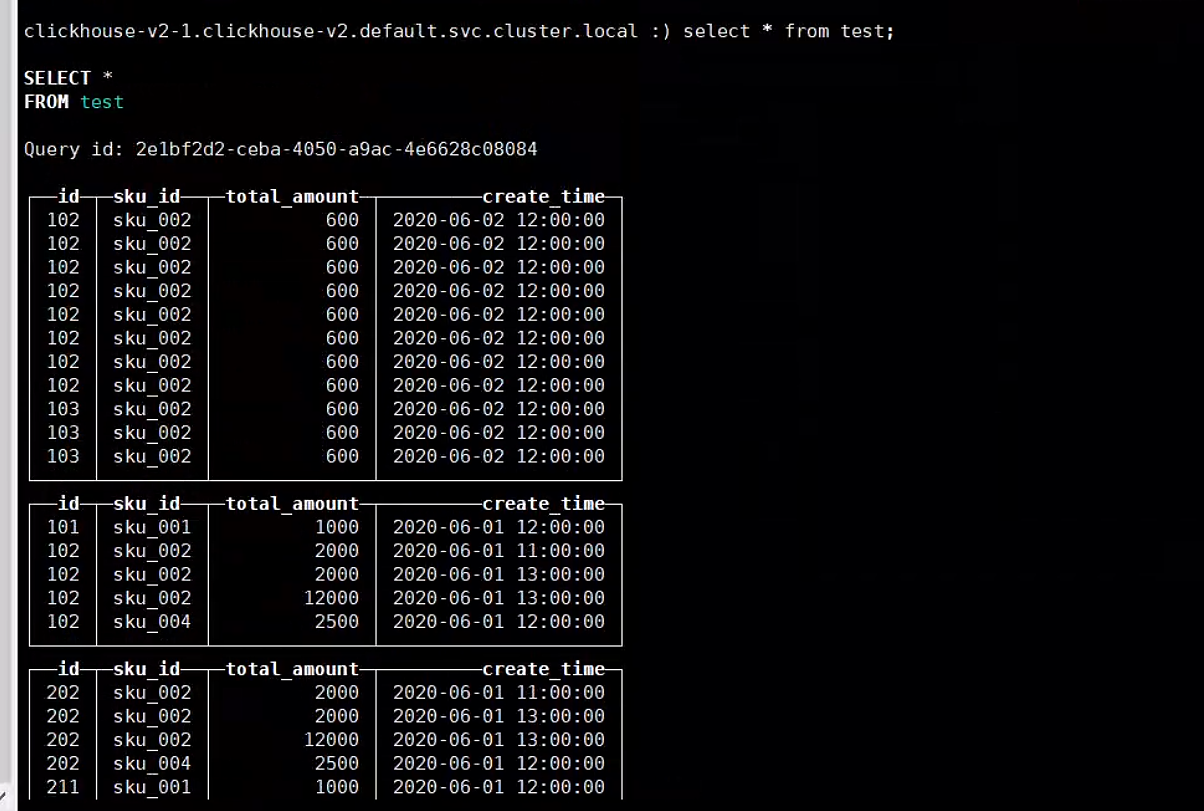
3.5. 分片存储
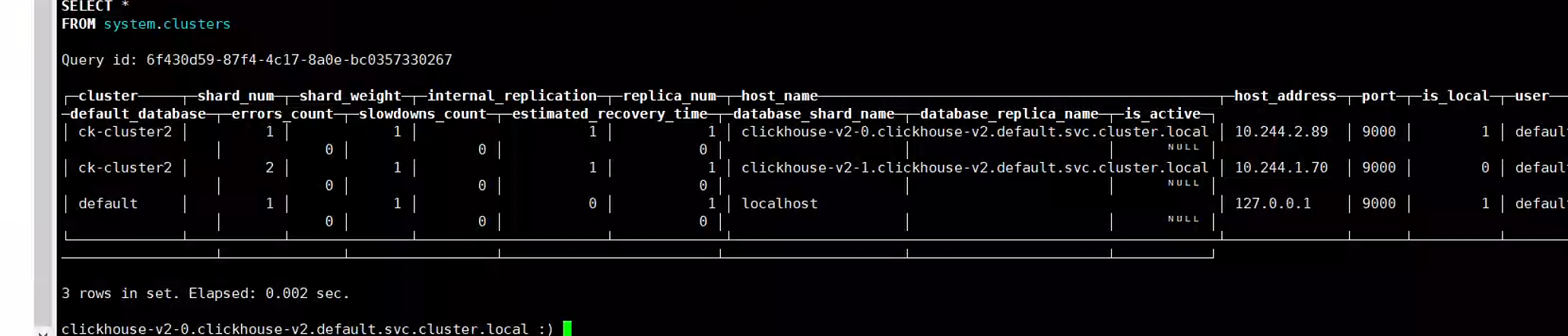
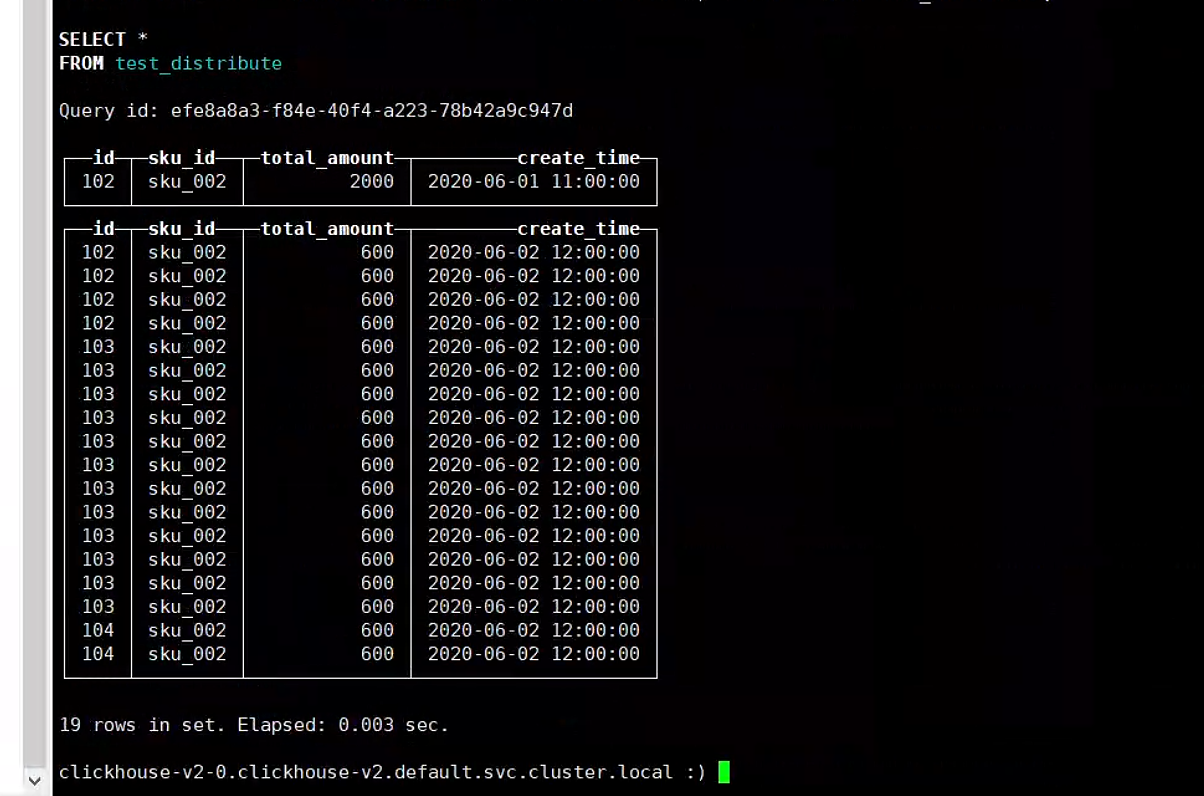
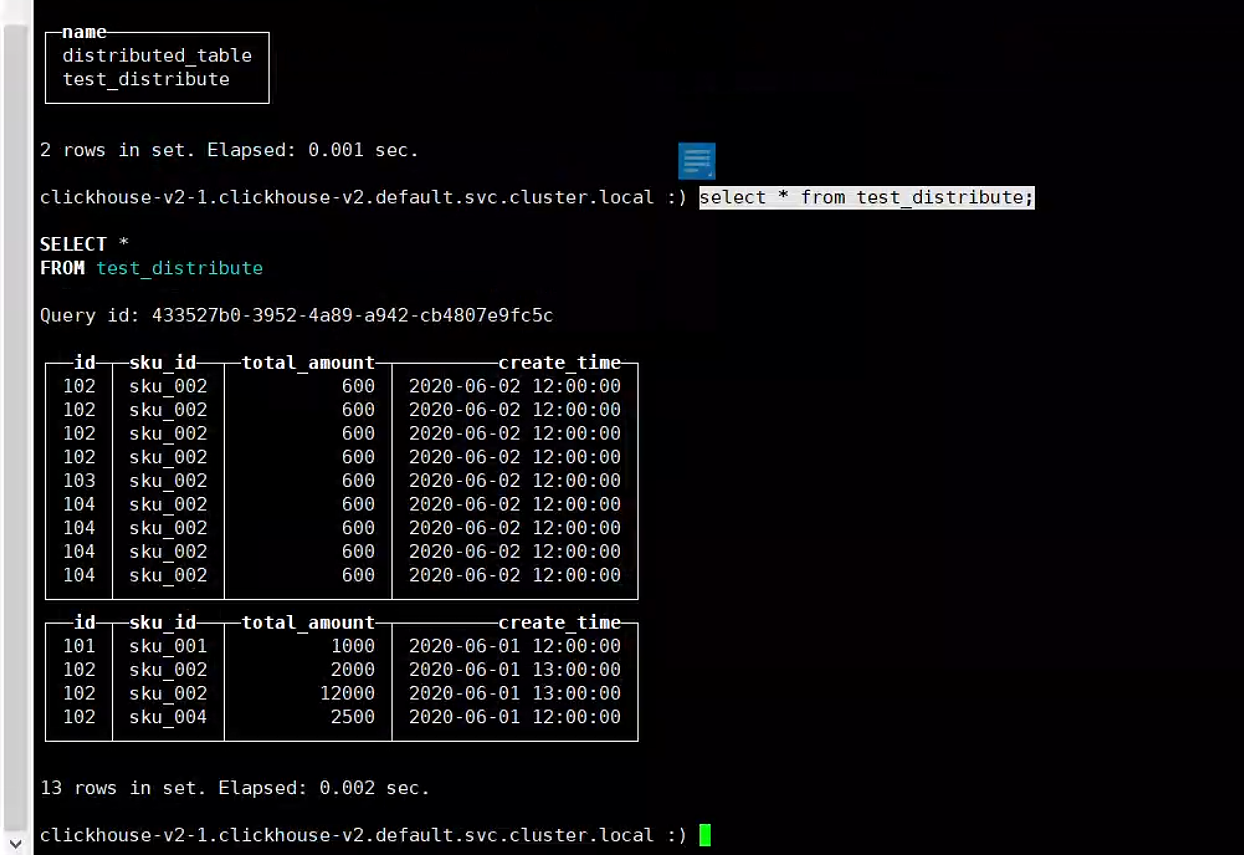
3.6. 分布式表中的default用户问题
分布式表的操作是通过无密码的default用户 但是生产环境一般不允许无密码操作 如果直接在user.xml修改default用户会导致连接分布式表错误 所以有以下几种解决方式
(1) 一种方式是在clickhouse配置的分片中设置访问用户和密码
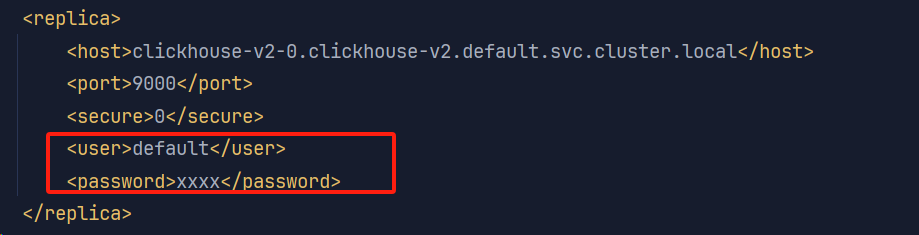
这种方式不是特别好 密码需要明文存储在配置信息中
(2) 还有一种方式是使用无密码的default用户 在用户配置端配置限制ip
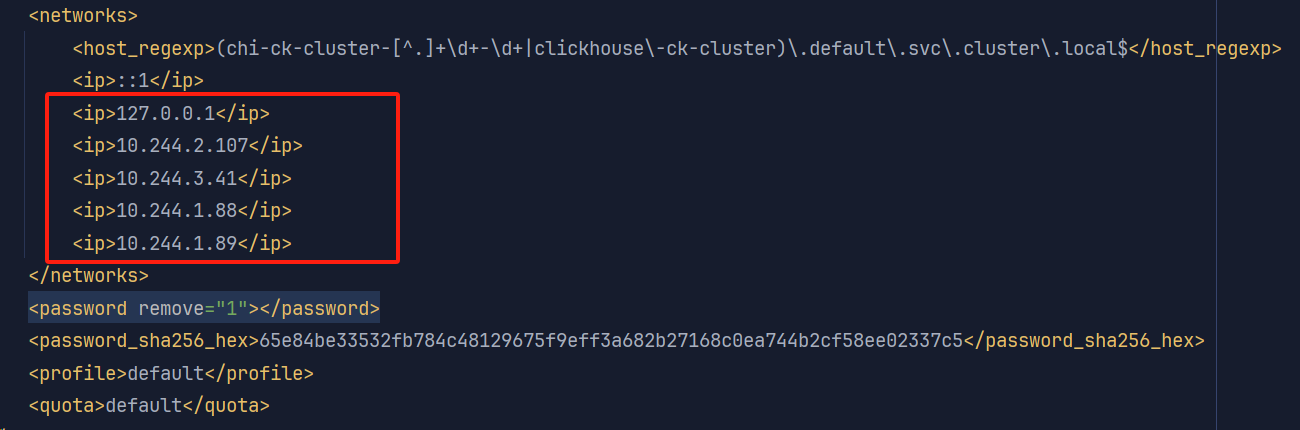
但是k8s中集群的ip是随机分配的
(3)采用集群内部加密令牌访问
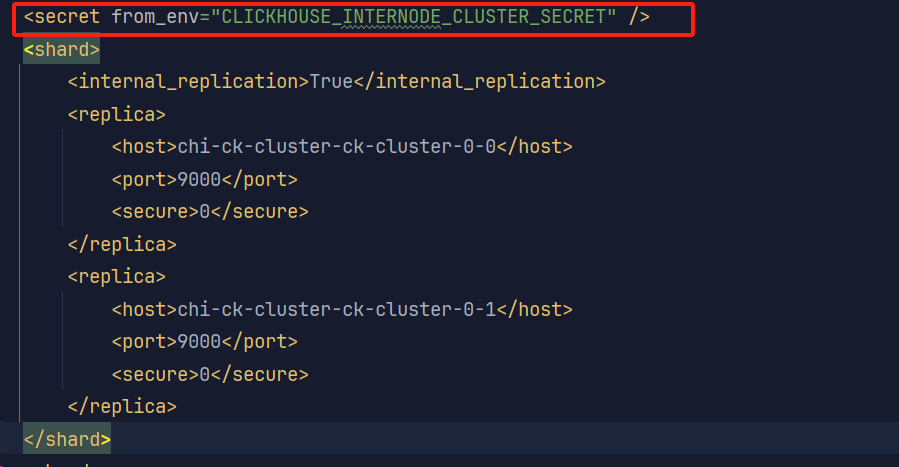
#CLICKHOUSE_INTERNODE_CLUSTER_SECRET为环境变量 可以在配置文件的时候指定- name: CLICKHOUSE_INTERNODE_CLUSTER_SECRETvalueFrom:secretKeyRef:name: clickhouse-secretskey: secret可以在容器内部使用printenv | grep "CLICKHOUSE_INTERNODE_CLUSTER_SECRET"查看
建议使用default的用户也进行ip限制 创建一个新的用户用于访问ck
4. 容器配置
实现生产配置中还需要完善配置
探针
数据挂载(pv pvc)
反亲和配置
livenessProbe:httpGet:#协议scheme: HTTP#路径path: /ping# 端口port: 8123# 延迟探测时间(秒) 【 在k8s第一次探测前等待秒 】initialDelaySeconds: 600# 执行探测频率(秒) 【 每隔秒执行一次 】periodSeconds: 10# 超时时间timeoutSeconds: 10successThreshold: 1# 不健康阀值failureThreshold: 6volumeMounts:- mountPath: /var/logs/name: clickhouse-logs- mountPath: /var/lib/clickhousename: clickhouse-data- mountPath: /etc/clickhouse-server/config.dname: clickhouse-configaffinity:nodeAffinity:requiredDuringSchedulingIgnoredDuringExecution:nodeSelectorTerms:- matchExpressions:- key: kubernetes.io/hostnameoperator: Invalues:- "master"- "node1"- "node2"podAntiAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: appoperator: Invalues:- clickhouse-v2topologyKey: "kubernetes.io/hostname"volumes:- hostPath:path: /logs/clickhouse/name: clickhouse-logs- hostPath:path: /data/clickhouse/name: clickhouse-data- hostPath:path: /data/clickhouse/config.dname: clickhouse-config
使用文件挂载或者pv pvc挂载持久化数据存储

apiVersion: v1
kind: PersistentVolume
metadata:labels:clickhouse-pv: "console"name: clickhouse-efs-pv
spec:storageClassName: nfsaccessModes:- ReadWriteManycapacity:storage: 10Ginfs:path: /5c566f78-e67c-4b0d-821e-e80c76a69c16/server: xxx.xx.xx.xxxpersistentVolumeReclaimPolicy: RetainvolumeMode: Filesystem---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name: clickhouse-pvcnamespace: gzzx
spec:storageClassName: nfsaccessModes:- ReadWriteManyresources:requests:storage: 10Giselector:matchLabels:vngf-pv: "console"volumeMode: FilesystemvolumeName: clickhouse-efs-pv---
spec:replicas: 3serviceName: clickhouse-v1template:spec:containers:volumeMounts:- mountPath: /var/lib/clickhousename: clickhouse-dataaffinity:podAntiAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: appoperator: Invalues:- clickhouse-v1topologyKey: "kubernetes.io/hostname"volumes:- name: clickhouse-datapersistentVolumeClaim:claimName: clickhouse-pvc
6. 其他
相关镜像如果拉不下来 可以手动下载并load
docker save -o xx.tar image:xxx
scp xx.tar root@192.168.xxx.xxx:/home
这篇关于Clickhouse集群化(三)集群化部署的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







