本文主要是介绍SSD: Single Shot MultiBox Detector解读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
此SSD非彼SSD,不过都有一个特点快,我之前读过了这篇,这次算是重温,而且前面介绍了很多检测网络,尤其是FPN时更是对SSD有一个很根本的解读,所以这篇博客算是一个SSD精华介绍,哈哈。
贡献和特点
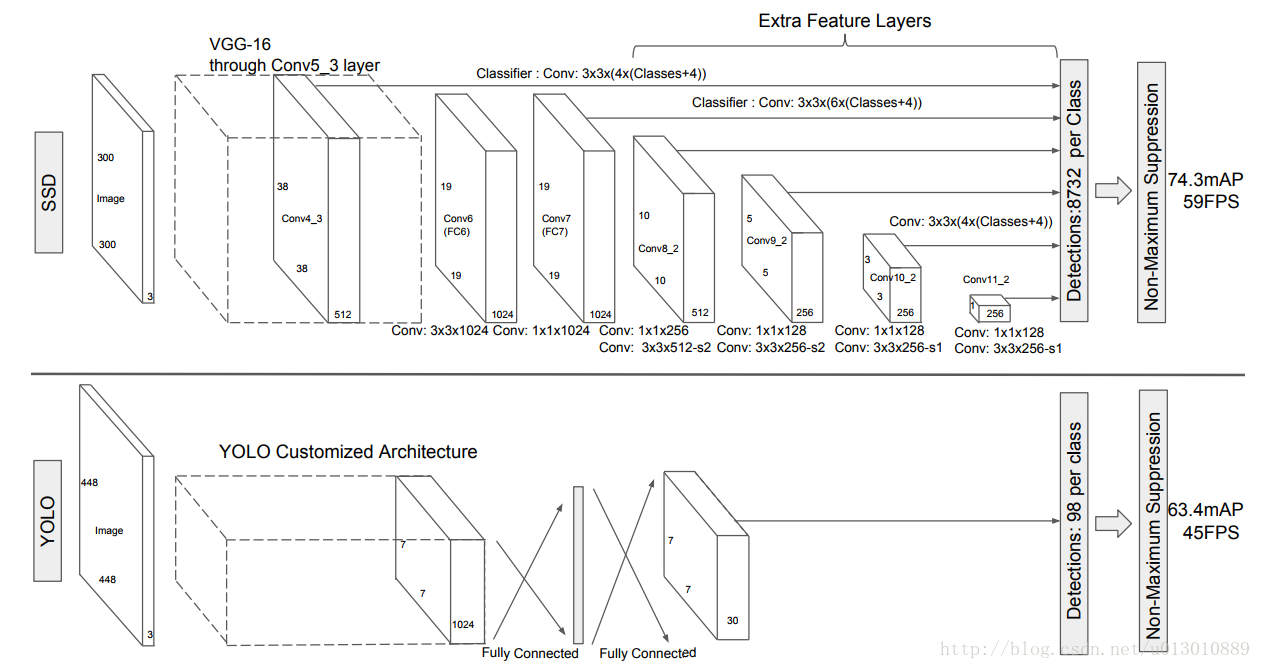
SSD最大的贡献,就是在多个feature map上进行预测,这点我在上一篇FPN也说过它的好处,可以适应更多的scale。第二个是用小的卷积进行分类回归,区别于YOLO及其faster rcnn的fc,大大降低参数和提速。
最大的特点就是不同于region-based的方法如faster rcnn等,ssd是没有region proposal这个过程的,follow了YOLO的工作,把检测的任务转化为了一个回归任务,直接对default box进行暴力回归。
论文中对不同scale的feature map进行预测,主要是conv4_3(之前在问过作者为什么选用conv4_3,这是作者在另一篇parsing的文章ParseNet得到的经验,这一层和特别,具体是什么就是实验证明这个层好)以及多加了一些更强语义的feature。注意 SSD的分类和坐标回归都是全卷积的,不需要roipooling,因为faster rcnn是两步先有rpn对anchor进行2分类和回归然后修正anchor后的proposal需要重新映射到feature上取feature进行后面的细分类和回归,而SSD是一步到位的,直接对default box进行细分类和一次暴力回归。以以C=21类,Conv4_3,分类为例,用3*3的卷积对feature上每个点进行分类,得到84*h*w的结果,类似分割正常应该是21channel的,由于Conv4_3feature上每个点是对应4个default(prior) box的,所以是84channel
# conv4_3上设置的4个不同的比例,feature上每个点对应4个default(prior) box
layer {name: "conv4_3_norm_mbox_conf"type: "Convolution"bottom: "conv4_3_norm"top: "conv4_3_norm_mbox_conf"convolution_param {num_output: 84 # 21*4 feature上每个点对应4个default(prior) box, 21个类别pad: 1kernel_size: 3stride: 1}
}
layer {name: "conv4_3_norm_mbox_loc"type: "Convolution"bottom: "conv4_3_norm"top: "conv4_3_norm_mbox_loc"convolution_param {num_output: 16 # 4*4 feature上每个点对应4个default(prior) box, 4个坐标pad: 1kernel_size: 3stride: 1}
}这里引用一张别人解读的文章Single Shot MultiBox Detector(SSD)的图片,我们刚刚也说了得到feature上每个点对应boxes(4/6)的回归值16*h*w,然后作者把这个拉平成一个向量(红线处flat),然后和gt做loss。就这样简单用一个3*3的卷积得到回归值然后做loss 佩服 网络这能都学会(其实faster rcnn也差不多是用1*1做的,任务简单些)。另一部分就正常softmax分类。
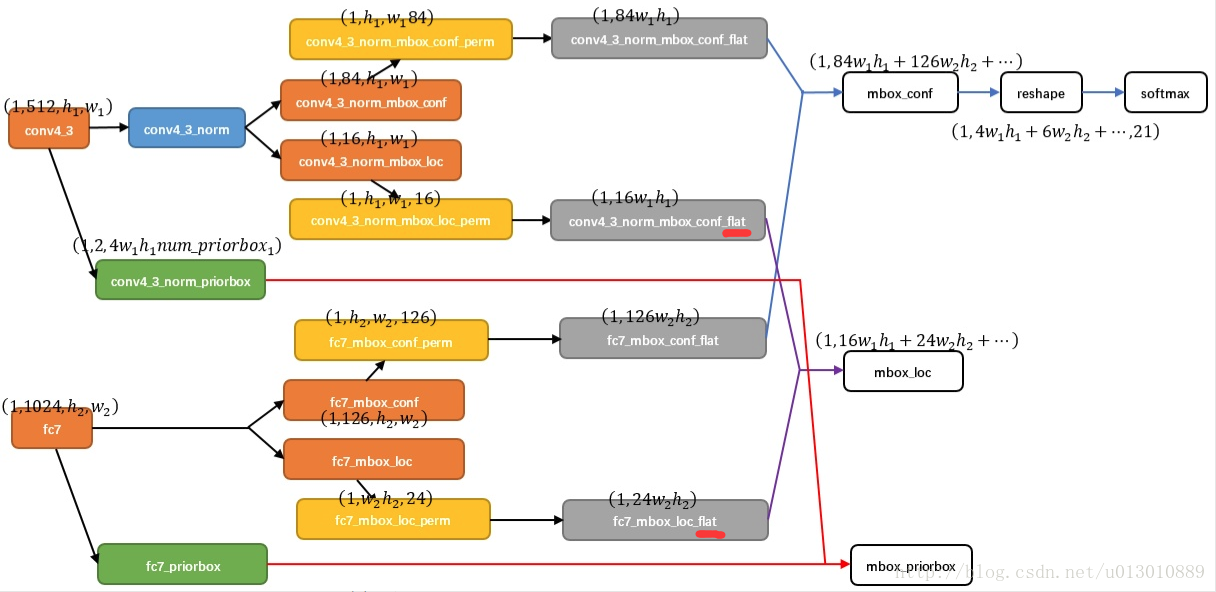
Default box
之前说fpn(发表晚于ssd)时也讲到,解决不同scale物体的检测,通常的做法就是放缩图片送到网络然后融合结果,但是费时,而ssd就是在不同scale的feature上预测不同大小的物体来解决这个问题,不同scale的feature视野域不同,刚好大物体在后面的feature预测,小物体在前面预测。说到底这个default box是十分类似于faster rcnn的anchor的,只是这个box是在不同scale的feature上取的。
不同层default box的大小公式如下,注意每个feature上的点虽然对应4或6个box,但是box并不是整个点对回去的原图,看公式最后的层最大也就0.9。feature上每个点的中心即是其对应box的中心,scale为1时再附带一个S’k的scale。
# SSD300 6个预测的层,他们的步长和比例设置 最后一个feature大小1*1大小步长为300
# 比例为1的其实两个,每个层都有忽略不写了 2是2和1/2 3是3和1/3
mbox_source_layers = ['conv4_3', 'fc7', 'conv6_2', 'conv7_2', 'conv8_2', 'conv9_2']
steps = [8, 16, 32, 64, 100, 300]
aspect_ratios = [[2], [2, 3], [2, 3], [2, 3], [2], [2]]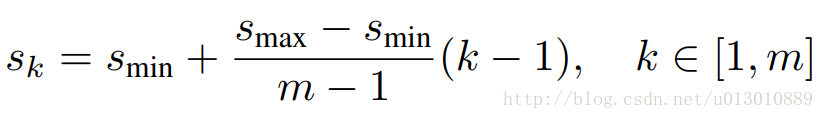

mbox_source_layers = ['conv4_3', 'fc7', 'conv6_2', 'conv7_2', 'conv8_2', 'conv9_2']
# in percent %
min_ratio = 20
max_ratio = 90
step = int(math.floor((max_ratio - min_ratio) / (len(mbox_source_layers) - 2)))
min_sizes = []
max_sizes = []
for ratio in xrange(min_ratio, max_ratio + 1, step):min_sizes.append(min_dim * ratio / 100.)max_sizes.append(min_dim * (ratio + step) / 100.)
min_sizes = [min_dim * 10 / 100.] + min_sizes
max_sizes = [min_dim * 20 / 100.] + max_sizes
print min_sizes
print max_sizes
'''
conv4_3特殊对待了
[30.0, 60.0, 111.0, 162.0, 213.0, 264.0]
[60.0, 111.0, 162.0, 213.0, 264.0, 315.0]
''''''default box的生成'feature_maps' : [38, 19, 10, 5, 3, 1],'min_dim' : 300,'steps' : [8, 16, 32, 64, 100, 300],'min_sizes' : [30, 60, 111, 162, 213, 264],'max_sizes' : [60, 111, 162, 213, 264, 315],'aspect_ratios' : [[2], [2, 3], [2, 3], [2, 3], [2], [2]],
'''
for k, f in enumerate(self.feature_maps):for i, j in product(range(f), repeat=2):f_k = self.image_size / self.steps[k]# unit center x,ycx = (j + 0.5) / f_kcy = (i + 0.5) / f_k# aspect_ratio: 1# rel size: min_sizes_k = self.min_sizes[k] / self.image_sizemean += [cx, cy, s_k, s_k]# aspect_ratio: 1# rel size: sqrt(s_k * s_(k+1))s_k_prime = sqrt(s_k * (self.max_sizes[k] / self.image_size))mean += [cx, cy, s_k_prime, s_k_prime]# rest of aspect ratiosfor ar in self.aspect_ratios[k]:mean += [cx, cy, s_k * sqrt(ar), s_k / sqrt(ar)]mean += [cx, cy, s_k / sqrt(ar), s_k * sqrt(ar)]Conv4_3 38*38的feature map通过3*3的卷积层预测4个不同宽高比的box,Conv7 19*19预测6个,Conv8_2, Conv9_2预测6个不同长宽比的box,Conv 10_2,Conv11_2预测4个。所以38*38*4+19*19*6+10*10*6+5*5*6+3*3*4+4 = 8732,所有不同scale feature map上的点对应8732个box。可能大物体和小物体不占大多数,所以Conv4_3 Conv 10_2 Conv11_2都只有4个scale,而且Conv4_3太大了,scale太多box太多了。
gt匹配策略
还有一个就是给这些box指定gt的策略,基本和faster rcnn类似
1. 对于每个gt,将其指定给与它iou最大的box,保证每个gt都有box去回归
2. 对于剩下的box,只要与任一gt iou>0.5(faster rcnn是0.7),都将这个gt指定给它
3. 貌似剩下的都是负样本了(faster rcnn是与任一gt的iou<0.3才为负样本,其他非正非负忽略掉),这点文中没有直接说,等我看下代码吧
难样本挖掘和数据增强
按照 default boxes 的 confidence 的大小。 选择最高的几个,保持最后的正负样本为1:3,文中训练时没说用nms哎,只有在inference时说了用nms,具体还要我再刷一遍代码。
By using a confidence threshold of 0.01, we can filter out most boxes. We then apply nms with jaccard overlap of 0.45 per class and keep the top 200 detections per image.
数据增强:
1. 使用原始的图像
2. 从原图随机采样一个 patch,但是采样后的patch中与原图所有gt boxes iou的最小值要满足 >0.1 0.3…0.9
3. 从原图随机采样 patch没有任何限制
采样从以上3种形式中随机选取,在这些采样步骤之后,每一个采样的patch被resize到固定的大小,并且以0.5的概率随机的 水平翻转(horizontally flipped)。除此之外,SSD还有一些提前的数据增强S光照啊旋转等等,这也是它最被argue的一点了。
def _crop(image, boxes, labels):height, width, _ = image.shapeif len(boxes)== 0:return image, boxes, labelswhile True:'''1. 使用原始的图像 对应mode: None if mode is None:return image, boxes, labels2. 从原图随机采样一个 patch,但是采样后的patch中与原图所有gt boxes iou的最小值要满足 >0.1 0.3...0.9对应mode: (0.1, None),(0.3, None),等iou = matrix_iou(boxes, roi[np.newaxis])if not (min_iou <= iou.min() and iou.max() <= max_iou):continue3. 从原图随机采样 patch没有任何限制 对应mode: (None, None)if min_iou is None:min_iou = float('-inf')if max_iou is None:max_iou = float('inf')
'''mode = random.choice((None,(0.1, None),(0.3, None),(0.5, None),(0.7, None),(0.9, None),(None, None),))if mode is None:return image, boxes, labelsmin_iou, max_iou = modeif min_iou is None:min_iou = float('-inf')if max_iou is None:max_iou = float('inf')for _ in range(50):scale = random.uniform(0.3,1.)min_ratio = max(0.5, scale*scale)max_ratio = min(2, 1. / scale / scale)ratio = math.sqrt(random.uniform(min_ratio, max_ratio))w = int(scale * ratio * width)h = int((scale / ratio) * height)l = random.randrange(width - w)t = random.randrange(height - h)roi = np.array((l, t, l + w, t + h))iou = matrix_iou(boxes, roi[np.newaxis])if not (min_iou <= iou.min() and iou.max() <= max_iou):continueimage_t = image[roi[1]:roi[3], roi[0]:roi[2]]centers = (boxes[:, :2] + boxes[:, 2:]) / 2mask = np.logical_and(roi[:2] < centers, centers < roi[2:]) \.all(axis=1)boxes_t = boxes[mask].copy()labels_t = labels[mask].copy()if len(boxes_t) == 0:continueboxes_t[:, :2] = np.maximum(boxes_t[:, :2], roi[:2])boxes_t[:, :2] -= roi[:2]boxes_t[:, 2:] = np.minimum(boxes_t[:, 2:], roi[2:])boxes_t[:, 2:] -= roi[:2]return image_t, boxes_t,labels_t
实验结果
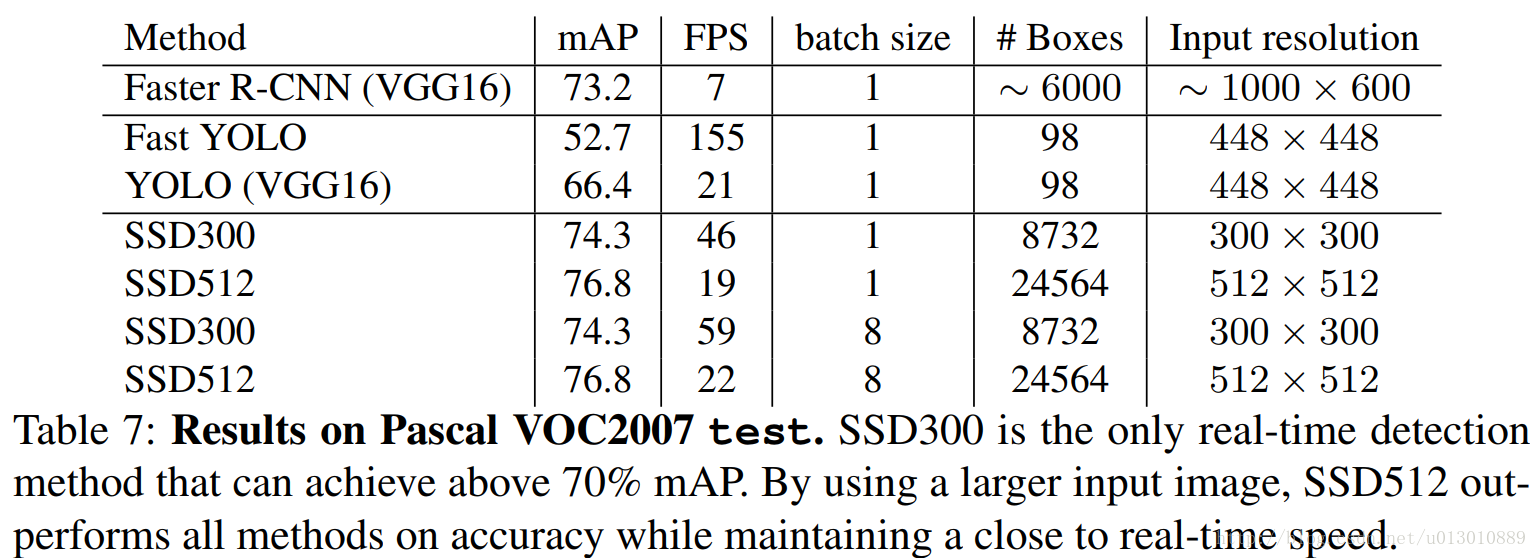
效果真的很赞,又快又好(和作者强大的码力也有很大关系的,膜拜中),一些消融实验就不一一介绍了。
不足之处
- default box的min_size,max_size和aspect_ratio值这些设置很吃经验的,不好调节
- 对小物体依然不ok,预测是从conv4_3开始的,一是有些小物体在这都看不到了,二是浅层feature来预测的话语义又不够强,很难分类,而小物体又很依赖上下文信息来识别,这也是之前讲的fpn的改进之处了,把强语义的feature给融合过来了 (图片第3-6列)
- 因为ssd从多个level的feature进行预测,所以很容易重复地检测到一个物体的多个部件或者把多个物体合并到一个物体里(第一列多个狗头,第二列把两个狗合并成一个狗),具体原因不是特别清楚???(图片第1、2列)

参考了Single Shot MultiBox Detector(SSD)
faster rcnn和ssd我都参看了知乎专栏:机器学习随笔,收益匪浅,ps这个作者之前在csdn现在所有csdn文章都删掉挂到知乎了,特别感谢。
这篇关于SSD: Single Shot MultiBox Detector解读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







