本文主要是介绍Jupyter Notebook本地化安装配置结合内网穿透实现跨网络使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1.前言
- 2.Jupyter Notebook的安装
- 2.1 Jupyter Notebook下载安装
- 2.2 Jupyter Notebook的配置
- 2.3 Cpolar下载安装
- 3.Cpolar端口设置
- 3.1 Cpolar云端设置
- 3.2.Cpolar本地设置
- 4.公网访问测试
- 5.结语
1.前言
本文主要介绍如何在Windows系统电脑本地部署Jupyter Notebook交互笔记,并结合cpolar内网穿透工具配置公网地址,实现随时随地远程访问使用本地安装的Jupyter笔记。
在数据分析工作中,使用最多的无疑就是各种函数、图表、代码和说明文档,这些复杂的内容不仅让使用的人头晕脑胀,也让普通的聊天工具一脸蒙圈。沟通工具不给力,就没法协同办公,可数据分析又离不开多人配合,所以Jupyter Notebook就成为大部分数据工作人员的必备工具。正如之前所说,Jupyter Notebook很适应复杂内容的沟通,因此现在也在机器学习、深度学习和教育工作中获得广泛应用。
但Jupyter Notebook也有缺陷,就是被局限在局域网范围。那有什么工具能让Jupyter Notebook在公共互联网下使用吗,答案自然是肯定的。现在我们就来看看,如何[cpolar](cpolar官网-安全的内网穿透工具 | 无需公网ip | 远程访问 | 搭建网站)与Jupyter Notebook配合,实现在公共互联网使用数据分析工作的无缝配合。
2.Jupyter Notebook的安装
由于jupyter notebook来源于IPython,所以想要安装使用jupyter notebook,就要先安装Python环境。好在Python安装并不复杂,直接到Python官网下载合适版本安装即可。
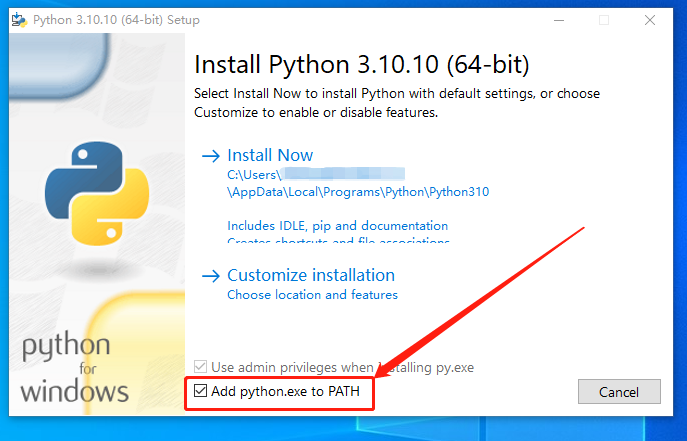
在安装Python时需要注意的是,要记得在安装界面下方勾选Add python.exe to PATH选项,即将python加入环境变量中。
Python安装完成后,就可以进行jupyter notebook的安装。
2.1 Jupyter Notebook下载安装
要安装jupyter notebook,我们需要打开windows的命令行界面,在命令行界面输入命令
pip install jupyter
系统会自动进行安装程序
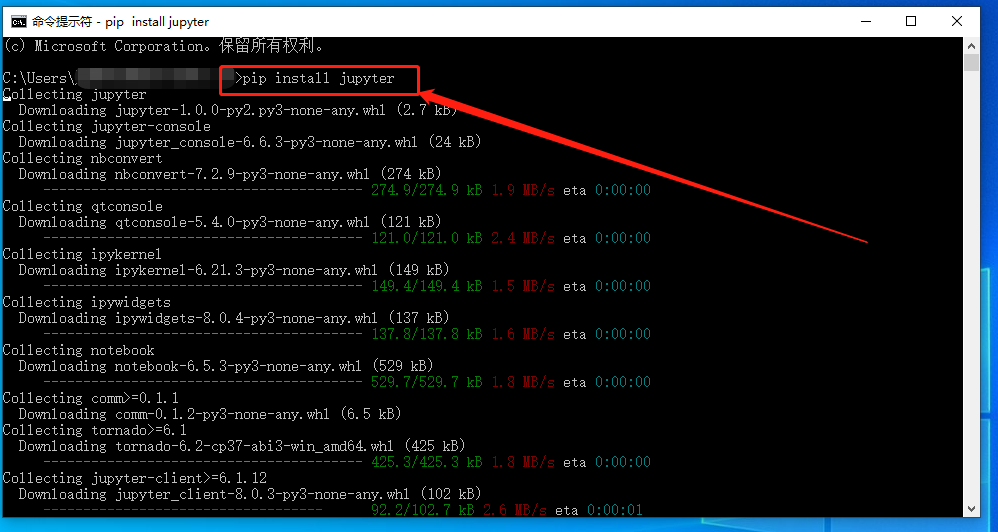
安装完成后,再输入命令
jupyter Notebook
就能启动jupyter notebook程序
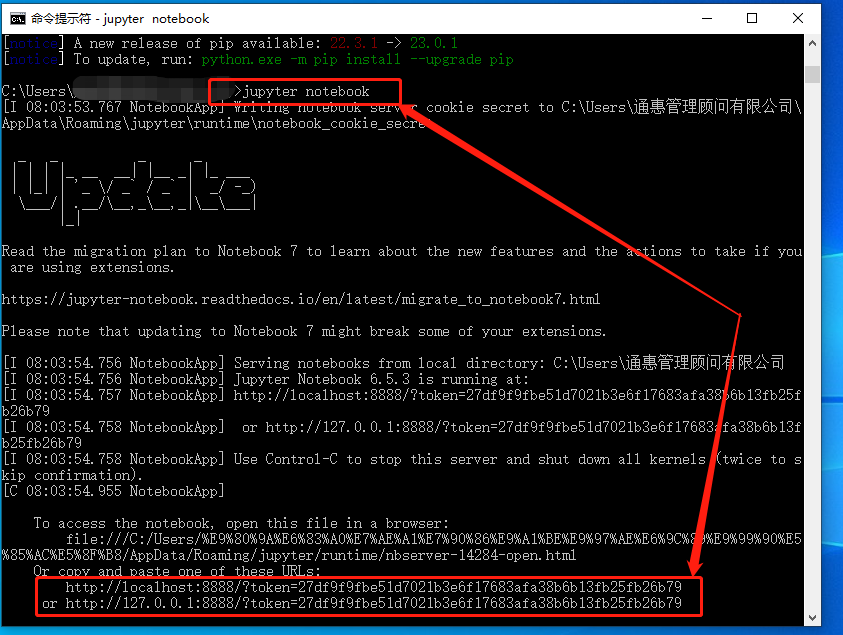
程序启动后,会在最下方显示jupyter notebook的地址,只要在浏览器中贴入这个地址(或者直接输入端口地址)就能打开jupyter notebook。
2.2 Jupyter Notebook的配置
由于我们的jupyter notebook需要连入公共互联网使用,因此有必要加入一道密码防护,并允许互联网连接。
先关闭之前的命令行窗口,再新开一个命令行窗口,输入命令
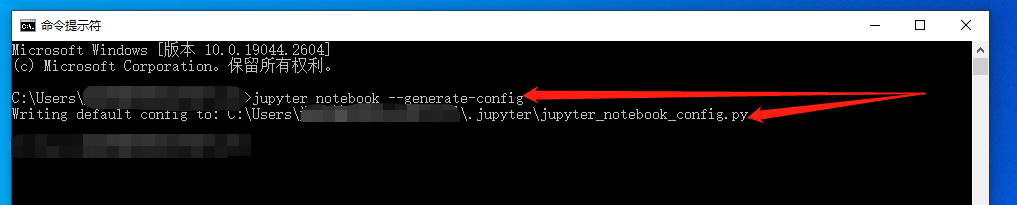
jupyter notebook --generate-config
新建一个配置文件,此时程序会反馈这个配置文件的所在位置,需要记住这个位置方便之后的操作。
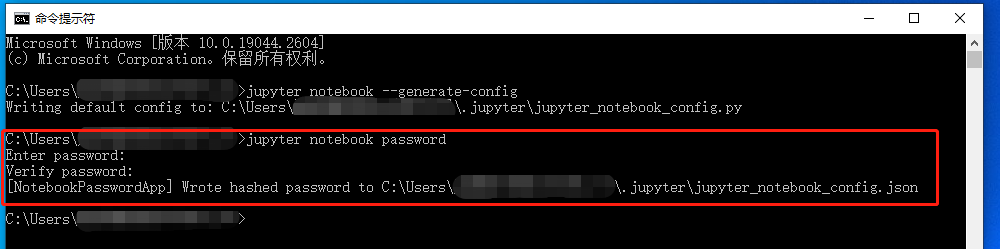
接着输入创建访问密码的命令
jupyter notebook password
系统会要求输入两次密码(确认密码)。输入新密码后,就会反馈密码已经加入配置文件中。
最后,依照之前显示的config文件存放位置,打开jupyter_notebook_config.json文件,将其中那一长串密文复制下来。
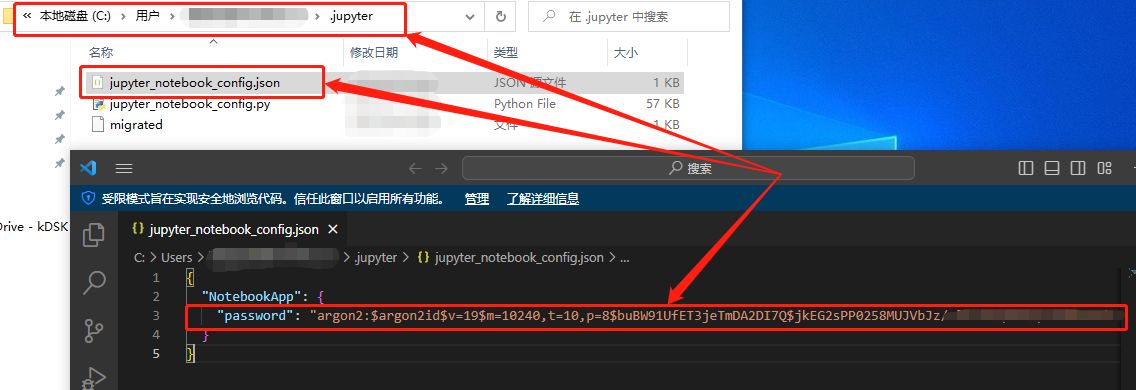
再打开jupyter_notebook_congfig.py配置文件,添加下面的参数并保存保存
c.NotebookApp.ip='*' #允许访问的IP地址,设置为*代表允许任何客户端访问
c.NotebookApp.password = u'argon2:$argon2id$v=19$m=10240,t=10,p=8$QcZlyMBu9icwhDDiUl+lZw$y4EP3WI4gZjc'#刚才生成密码时上面复制的密文
c.NotebookApp.open_browser = False
c.NotebookApp.port =8888 #可自行指定一个端口, 访问时使用该端口
c.NotebookApp.allow_remote_access = True
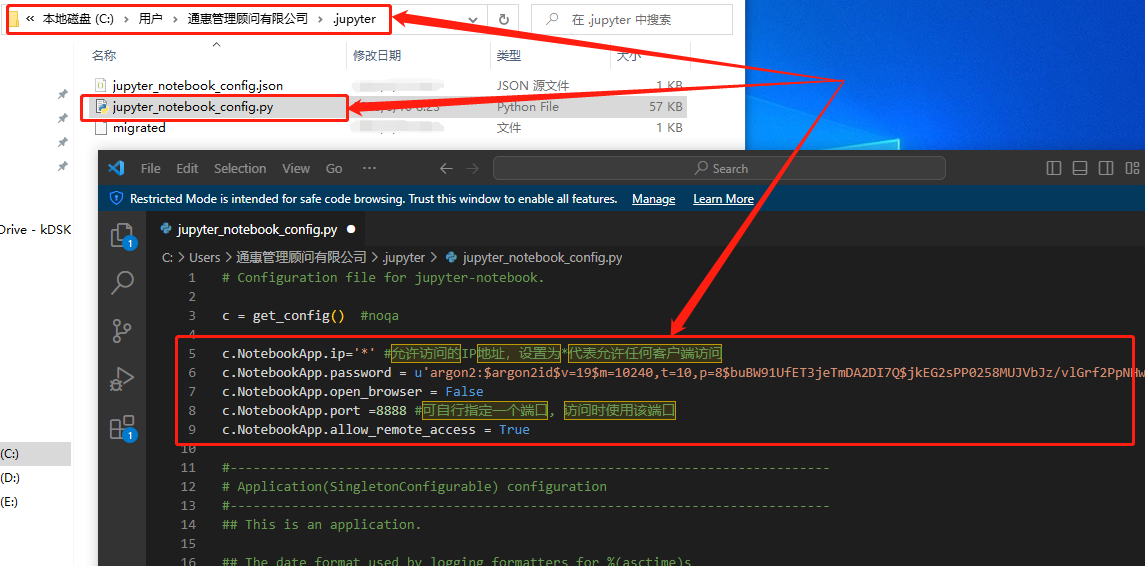
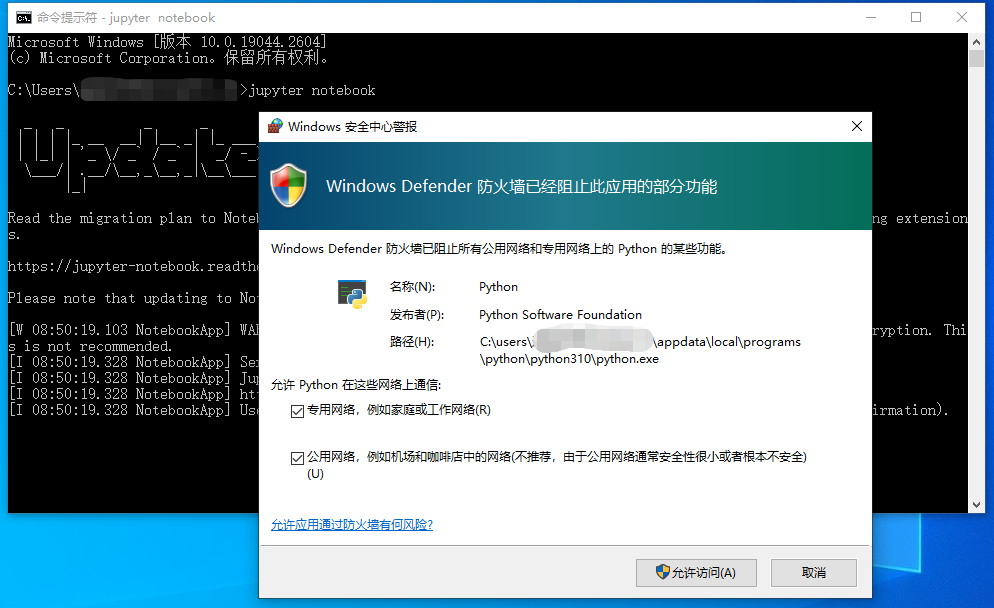
保存所做的修改,退出修改界面,再回到命令行界面,启动jupyter notebook,就会发现在启动时出现了防火墙警报,点击允许访问即可。
同样的,jupyter notebook会出现一个带端口号的地址。
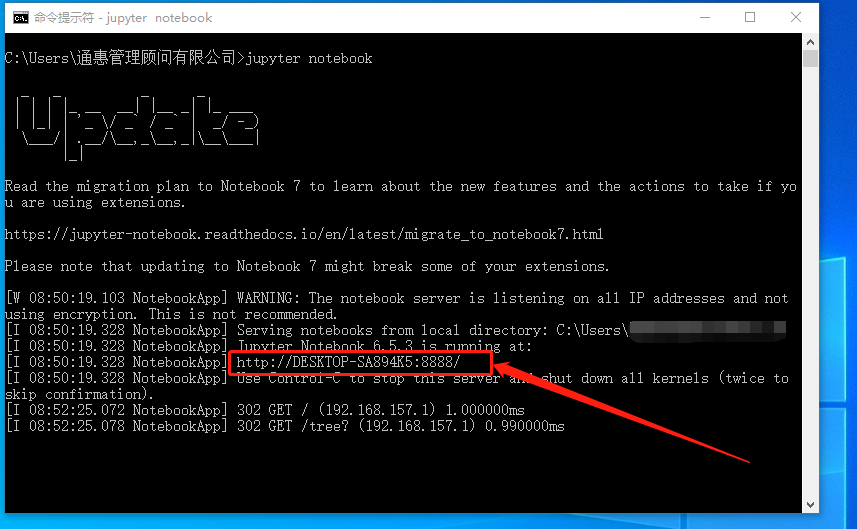
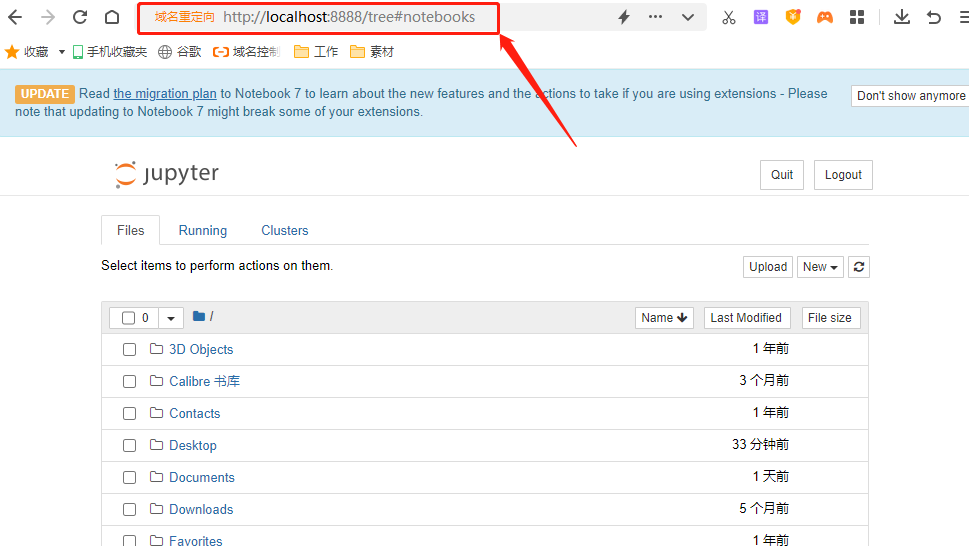
将这个地址粘贴到浏览器中,就会出现要求输入密码才能访问jupyter notebook的页面,就说明我们所做的配置已经生效。
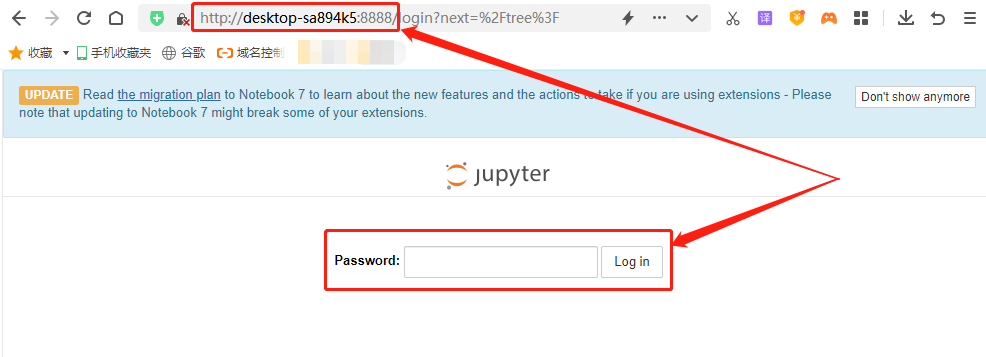
完成了jupyter notebook的配置,我们就可以进行另一项必要工作,即安装cpolar,并使用cpolar为jupyter notebook生成一条专属的内网穿透数据隧道。
2.3 Cpolar下载安装
相较于jupyter notebook,cpolar的安装就无脑多了,只要在cpolar官网
https://www.cpolar.com/下载对应版本的cpolar安装程序即可。
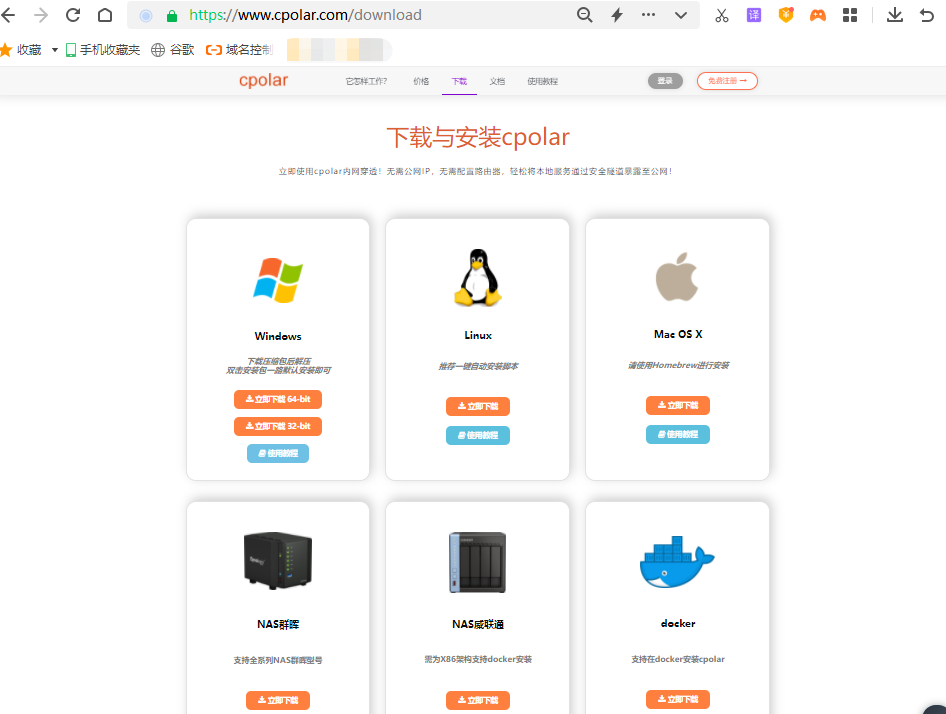
笔者的操作系统为windows,因此选择windows的安装程序,双击.msi程序一路下一步即可。

需要注意的是,cpolar会为每个用户生成专属的数据隧道,并辅以复杂的token口令保证数据传输的安全,因此使用cpolar需要注册个人专属的账号,具体过程就不在此详述。
3.Cpolar端口设置
Cpolar在本地设备上安装完成后,就可以在客户端建立免费的数据隧道,连接jupyter notebook端口(具体过程参见3.2 cpolar本地设置)。不过免费的数据隧道每个24小时就会更新一次公共互联网地址,并不符合笔者的使用场景。因此笔者升级了cpolar的vip套餐,以便获得能长期稳定存在的内网穿透数据隧道。
3.1 Cpolar云端设置
要使用cpolar设立长期稳定数据隧道,需要先登录cpolar的官网,在cpolar主页面左侧找到预留按钮,进入预留数据隧道页面。在这个页面中,找到保留的二级子域名栏位。
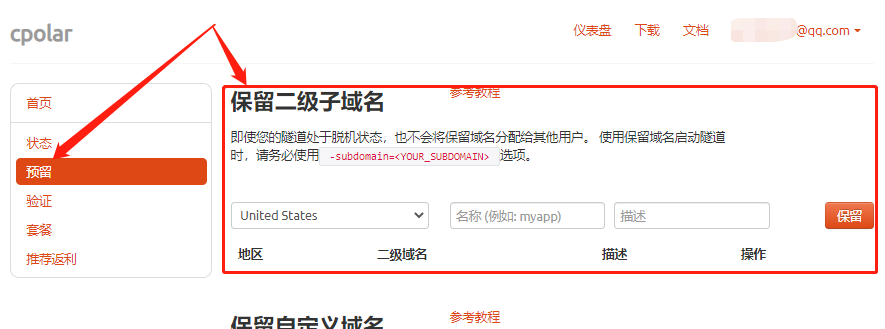
在保留二级子域名栏位中,我们需要对几个信息进行设置,以便cpolar生成一条我们定义的空白数据隧道,这条数据隧道最终会与jupyter notebook的端口连接起来。需要设置的信息为以下3项:
- 地区:即服务器地址,就近选择就好;
- 二级域名:即打算生成什么样的域名,这个二级域名会显示在最终域名中,因此需要注意输入的内容;
- 描述:即这条数据隧道的说明,只要自己可以分辨即可。
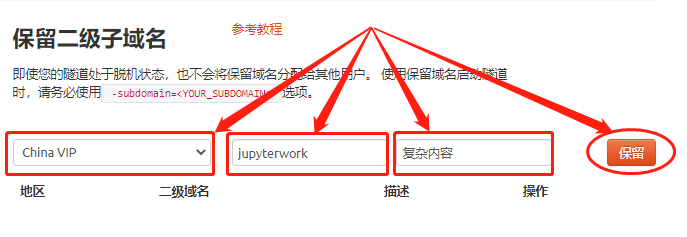
完成设置后,就可以点击右侧的保留按钮,生成一条空白数据隧道。如果不打算再使用这条数据隧道,就可以点击右侧的小X,将这条数据隧道轻易删除。
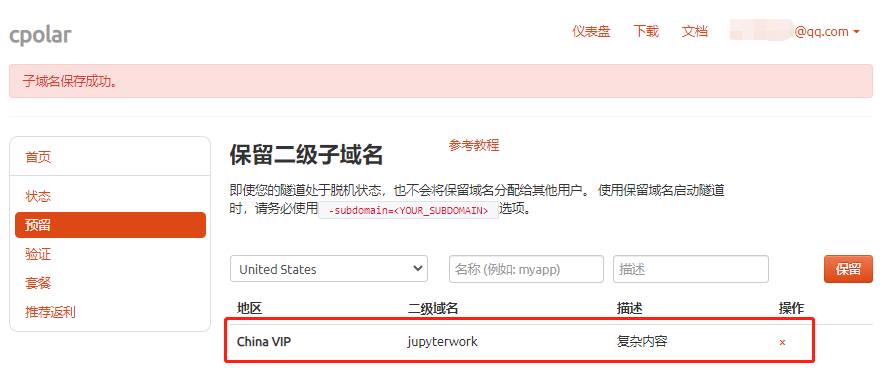
3.2.Cpolar本地设置
在完成cpolar云端的空白数据隧道设置后,就可以回到本机的cpolar客户端,将空白数据隧道与本地jupyter notebook端口连接起来(如果没有cpolar的vip,可以直接在客户端设置临时隧道,而设置步骤都是一样的)。我们可以在开始菜单中找到cpolar的快捷方式,也可以在浏览器中输入localhost:9200,打开cpolar的Web-UI界面。
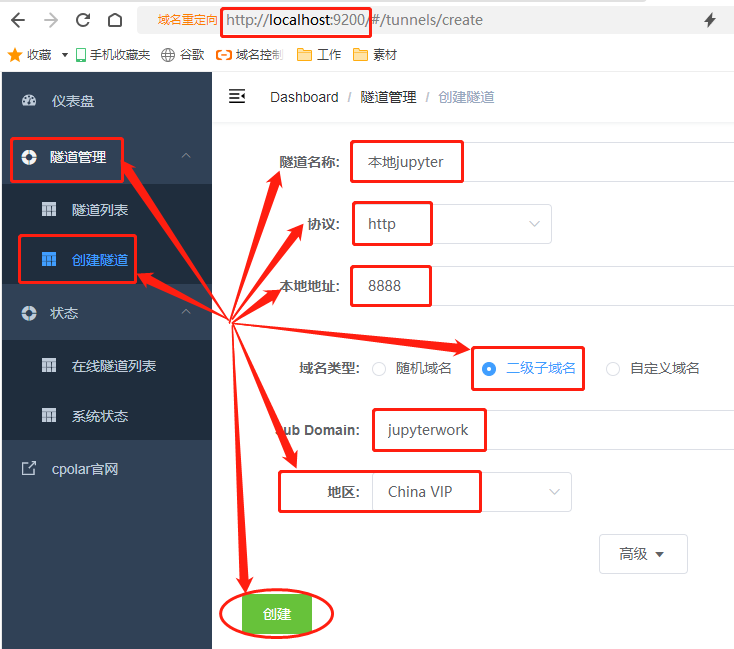
在cpolar客户端的主界面,点击左侧“隧道管理”项下的“创建隧道”按钮,进入本地隧道创建页面。与cpolar的云端设置一样,在cpolar客户端也需要进行几项设置。这些设置包括
- 隧道名称:可以看做cpolar本地的隧道信息注释,只要方便分辨即可;
- 协议:即以何种方式连接本地端口,这里我们选择http协议;
- 本地地址:本地地址即为本地网站的输出端口号,在这里输入888;
- 域名类型:由于我们已经在cpolar云端预留了二级子域名的固定隧道,因此勾选“二级子域名”(如果有自定义域名,则勾选自定义域名),并在下一行“Sub Domain”栏中填入预留的二级子域名,该例子中为“jupyterwork”。如果打算设置临时内网穿透数据隧道,这里则勾选“随机域名”;
- 地区:与cpolar云端预留的信息一样,我们依照实际使用地填写即可;
完成这些设置后,就可以点击页面下方的“创建”按钮,生成能够穿透本地局域网的数据隧道。
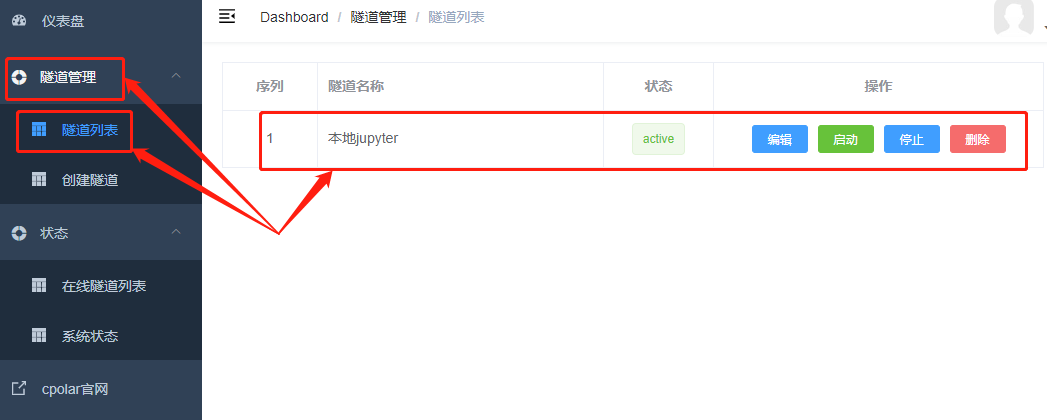
本地隧道生成后,可以在隧道管理项下的隧道列表中看到,并且还可以在这里对这条隧道的开启、关闭、删除进行操作,当然,也能在编辑中对这条隧道的信息进行变更。
而这条隧道的公共互联网地址,则可以在状态项下的在线隧道列表中找到
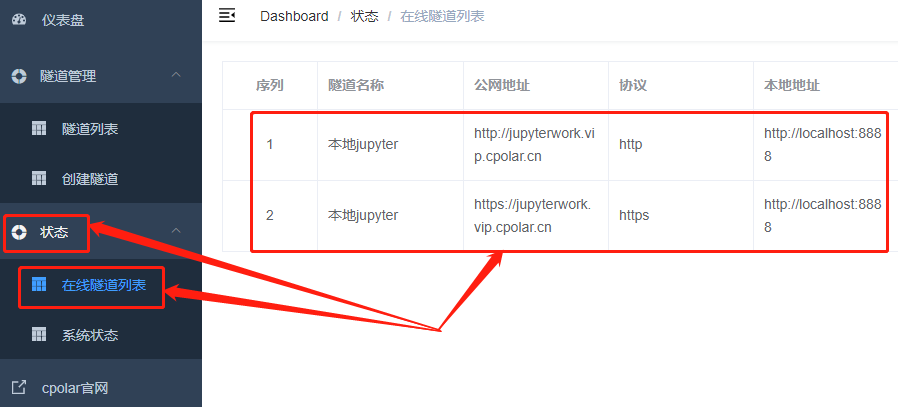
4.公网访问测试
最后,我们将cpolar客户端显示的地址粘贴到位于本地局域网以外设备的浏览器中,就能打开本地的jupyter notebook。
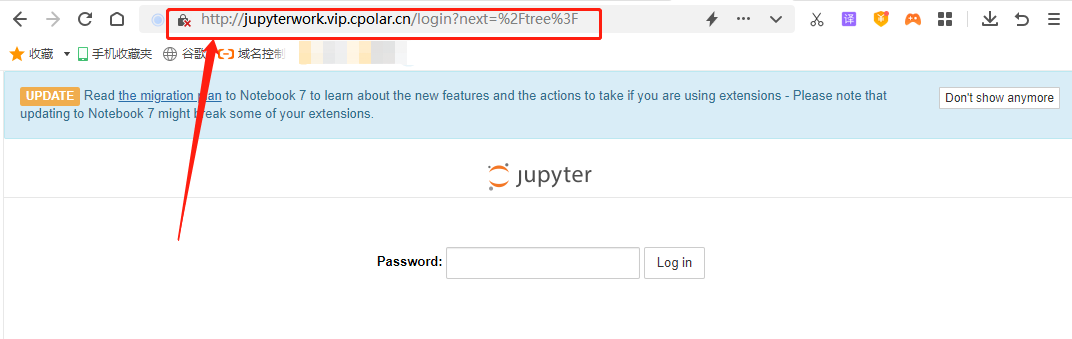
5.结语
至此,我们就完成了使用cpolar生成的数据隧道,将内网的jupyter notebook发布到公共互联网的操作。虽然步骤看着很多,但实际操作起来非常快。只要注意对jupyter notebook配置时不要输入错误指令,应该能很轻松的完成。
这篇关于Jupyter Notebook本地化安装配置结合内网穿透实现跨网络使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





