本文主要是介绍算是一些Transformer学习当中的重点内容,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、基础概念
Transformer是一种神经网络结构,由Vaswani等人在2017年的论文Attentions All YouNeed”中提出,用于处理机器翻译、语言建模和文本生成等自然语言处理任务。Transformer同样是encoder-decoder的结构,只不过这里的“encoder”和“decoder”是由无数个同样结构的encoder层和decoder层堆叠组成
在进入encoder或decoder前,源序列和目标序列需要经过一些“加工”,由wordembedding将序列转换为模型所能理解的词向量表示,其中包含了序列的内容信息;positionalencoding在内容信息的基础上添加位置信息;在进行机器翻译时,encoder解读源语句 (被翻译的句子)的信息,并传输给decoder,decoder接收源语句信息后,结合当前输入 (目前翻译的情况),预测下一个单词,直到生成完整的句子
Transformer模型不包含RNN,所以无法在模型中记录时序信息,会导致模型无法识别由顺序改变而产生的句子含义的改变,如“我爱我的小猫”和“我的小猫爱我”,为弥补这个缺陷,选择在输入数据中额外添加表示位置信息的位置编码


2.1 Encoder
Encoder负责处理输入的源序列,并将输入信息整合为一系列的上下文向量(context vector) 输出,每个encoder层中存在两个子层:多头自注意力和基于位置的前馈神经网络,子层之间使用了残差连接,并使用了层规范化

多头注意力看前文了解即可,基于位置的前馈神经网络被用来对输入中的每个位置进行非线性变换,它由两个线性层组成,层与层之间需要经过ReLU激活函数,相比固定的ReLU函数,基于位置的前馈神经网络可以处理更加复杂的关系,并且由于前馈网络是基于位置的,可以捕获到不同位置的信息,并为每个位置提供不同的转换
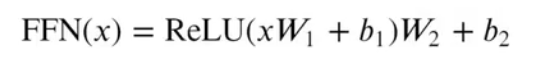

二者充称为“Add &Norm”(本质上是残差连接后紧跟了一个LayerNorm层)

2.2 Decoder
解码器将编码器输出的上下文序列转换为目标序列的预测结果Y该输出将在模型训练中与真实目标输出进行比较计算损失,不同于编码器,每个Decoder层中包含两层多头注意力机制,并在最后多出一个线性层,输出对目标序列的预测结果。

- 第一层:计算目标序列的注意力分数的掩码多头自注意力
- 第二层:用于计算上下文序列与目标序列对应关系,其中Decoder掩码多头注意力的输出作为query,Encoder的输出(上下文序列)作为key和value
二、带掩码的多头注意力
- 在处理目标序列的输入时,时刻的模型只能“观察”直到-1时刻的所有词元,后续的词语不应该一并输入Decoder中
- 为了保证在t时刻,只有t-1个词元作为输入参与多头注意力分数的计算,需要在第一个多头注意力中额外增加一个时间掩码,使目标序列中的词随时间发展逐个被暴露出来,该注意力掩码可通过三角矩阵实现,对角线以上的词元表示为不参与注意力计算的词元,标记为1

三、与传统NLP特征提取类模型的主要区别
- Transformer是一个纯基于注意力机制的结构,并将自注意力机制和多头注意力机制的概念运用到模型中
- 由于缺少RNN模型的时序性,Transformer引入了位置编码,在数据上而非模型中添加位置信息
四、以上的处理带来了优点
- 更容易并行化,训练更加高效
- 在处理长序列的任务中表现优秀,可以快速捕捉长距离中的关联信息
- 通过transformer实现文本机器翻译

这篇关于算是一些Transformer学习当中的重点内容的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




