本文主要是介绍每日一题——Python代码实现力扣1. 两数之和(举一反三+思想解读+逐步优化)五千字好文,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

一个认为一切根源都是“自己不够强”的INTJ
![]() 个人主页:用哲学编程-CSDN博客
个人主页:用哲学编程-CSDN博客![]() 专栏:每日一题——举一反三
专栏:每日一题——举一反三
Python编程学习
Python内置函数
Python-3.12.0文档解读
目录
菜鸡写法
代码分析
时间复杂度分析
空间复杂度分析
改进建议
我要更强
方法1: 使用哈希表(字典)
方法2: 排序和双指针
方法3: 使用集合(仅适用于特殊情况)
哲学和编程思想
1. 空间与时间的权衡(Space-Time Tradeoff)
2. 分治法(Divide and Conquer)
3. 迭代与递归
4. 数据结构的选择
5. 算法优化
6. 抽象与具体化
7. 代码的可读性与效率
举一反三
1. 空间与时间的权衡
2. 分治法
3. 迭代与递归
4. 数据结构的选择
5. 算法优化
6. 抽象与具体化
7. 代码的可读性与效率
题目链接:https://leetcode.cn/problems/two-sum/description/
菜鸡写法
class Solution:def twoSum(self, nums: List[int], target: int) -> List[int]:len_nums=len(nums)for i in range(len_nums):for j in range(len_nums):if i==j:continueif nums[i]+nums[j]==target:return [i,j]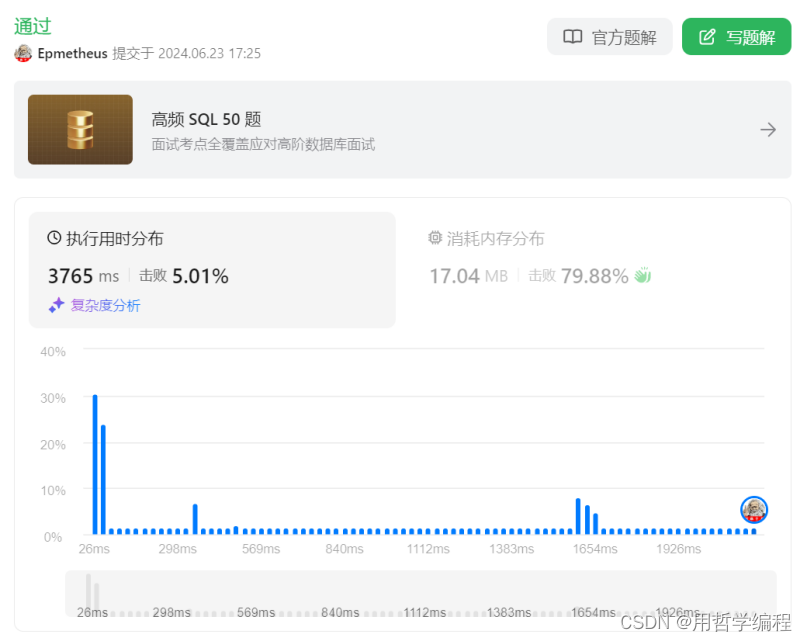
这段代码是一个Python类Solution的方法twoSum,其目的是在给定的整数列表nums中找到两个数,使得这两个数的和等于给定的目标值target。如果找到这样的两个数,方法返回一个包含这两个数索引的列表;如果没有找到,理论上应该返回一个特定的值(如None或[-1, -1]),但这段代码在找到解后立即返回,没有处理无解的情况。
代码分析
- 循环结构:代码使用了两个嵌套的循环来遍历列表nums。外层循环从第一个元素遍历到最后一个元素,内层循环同样从第一个元素遍历到最后一个元素。
- 条件判断:在内层循环中,首先通过if i==j来跳过自身与自身相加的情况,然后通过if nums[i]+nums[j]==target来检查两个数的和是否等于目标值。
- 返回结果:一旦找到满足条件的两个数,立即返回它们的索引。
时间复杂度分析
由于使用了两个嵌套的循环,每个循环都遍历整个列表,因此时间复杂度为O(n^2),其中n是列表nums的长度。这是因为对于列表中的每一个元素,都需要与其他所有元素进行比较。
空间复杂度分析
空间复杂度为O(1),因为除了输入的列表和几个变量(如索引和循环控制变量)外,没有使用额外的数据结构来存储信息。所有的操作都是基于原始列表进行的。
改进建议
这段代码的时间复杂度较高,可以通过使用哈希表(在Python中为字典)来优化。使用哈希表可以在一次遍历中找到解,时间复杂度可以降低到O(n)。
我要更强
方法1: 使用哈希表(字典)
这是最常见的优化方法,通过使用哈希表来存储元素及其索引,可以在一次遍历中找到解。
class Solution:def twoSum(self, nums: List[int], target: int) -> List[int]:num_to_index = {}for i, num in enumerate(nums):complement = target - numif complement in num_to_index:return [num_to_index[complement], i]num_to_index[num] = ireturn None # 如果没有找到,返回None时间复杂度: O(n),其中n是列表nums的长度。我们只遍历了一次列表。 空间复杂度: O(n),因为我们需要一个哈希表来存储元素及其索引。
方法2: 排序和双指针
这种方法首先对数组进行排序,然后使用两个指针分别从头部和尾部开始移动,直到找到解。
class Solution:def twoSum(self, nums: List[int], target: int) -> List[int]:sorted_indices = sorted(range(len(nums)), key=lambda x: nums[x])left, right = 0, len(nums) - 1while left < right:sum_ = nums[sorted_indices[left]] + nums[sorted_indices[right]]if sum_ == target:return [sorted_indices[left], sorted_indices[right]]elif sum_ < target:left += 1else:right -= 1return None # 如果没有找到,返回None时间复杂度: O(n log n),主要来自于排序操作。 空间复杂度: O(n),因为我们需要一个额外的列表来存储排序后的索引。
方法3: 使用集合(仅适用于特殊情况)
如果数组中的数字都是正数且范围有限,我们可以使用集合来存储所有可能的差值,然后检查这些差值是否存在于数组中。
class Solution:def twoSum(self, nums: List[int], target: int) -> List[int]:if all(isinstance(num, int) and num >= 0 for num in nums):possible_diffs = set()for num in nums:if num in possible_diffs:return [target - num, num]possible_diffs.add(target - num)return None # 如果没有找到,返回None时间复杂度: O(n),遍历了一次数组。 空间复杂度: O(n),因为需要一个集合来存储所有可能的差值。
这些方法提供了不同的优化策略,可以根据具体问题的要求和限制选择最合适的方法。
哲学和编程思想
这些优化方法体现了多种哲学和编程思想,包括但不限于:
1. 空间与时间的权衡(Space-Time Tradeoff)
- 哈希表方法:通过使用额外的空间(哈希表)来存储已经遍历过的元素及其索引,减少了时间复杂度。这是一种典型的空间换时间的策略。
- 排序和双指针方法:虽然这种方法需要额外的空间来存储排序后的索引,但它通过排序和双指针的策略,有效地减少了查找匹配对的时间。
2. 分治法(Divide and Conquer)
- 排序和双指针方法:这种方法通过将数组分为两部分,并从两端向中间移动指针,利用了分治的思想。通过比较和调整指针位置,逐步缩小搜索范围,直到找到解。
3. 迭代与递归
- 所有方法:这些方法都使用了迭代而非递归,通过循环结构来遍历数组或集合,这是编程中常用的控制结构,可以有效地处理大量数据。
4. 数据结构的选择
- 哈希表方法:选择哈希表作为数据结构是因为它提供了快速的查找操作(平均时间复杂度为O(1)),这对于需要在遍历过程中快速查找元素的情况非常有效。
- 排序和双指针方法:使用排序后的索引列表和双指针,利用了排序后数组的特性,即相邻元素的顺序关系,来加速查找过程。
5. 算法优化
- 哈希表方法:通过在遍历过程中即时检查目标值的补数是否已存在于哈希表中,避免了不必要的重复计算。
- 排序和双指针方法:通过排序和双指针的策略,避免了遍历整个数组,减少了比较的次数。
6. 抽象与具体化
- 所有方法:这些方法都体现了从具体问题(找到两个数使其和为目标值)到抽象算法(使用哈希表、排序和双指针等)的转换,这是编程中解决问题的关键步骤。
7. 代码的可读性与效率
- 所有方法:在编写代码时,不仅要考虑算法的效率,还要考虑代码的可读性和维护性。这些方法都尽量保持代码简洁明了,易于理解和修改。
通过这些方法,可以看到编程不仅仅是技术操作,更是一种结合了逻辑思维、数学原理和工程实践的艺术。每种方法都体现了对问题本质的深刻理解和创新思维的应用。
举一反三
理解并应用这些哲学和编程思想可以帮助在面对新的编程问题时举一反三。以下是一些技巧和建议:
1. 空间与时间的权衡
- 分析问题:在解决问题时,首先分析是否可以通过增加空间复杂度来减少时间复杂度。例如,使用缓存或哈希表来存储中间结果,以避免重复计算。
- 优化策略:在时间和空间之间找到平衡点。如果内存不是问题,考虑使用更多的空间来加速程序运行。
2. 分治法
- 分解问题:将复杂问题分解为更小的、易于管理的部分。例如,在处理大数据集时,可以将数据集分成几个部分,分别处理后再合并结果。
- 递归应用:对于可以自然分解为子问题的问题,考虑使用递归算法。确保理解递归的终止条件和如何组合子问题的解。
3. 迭代与递归
- 选择合适的控制结构:根据问题的性质选择迭代或递归。迭代通常更高效,而递归可以使代码更简洁和直观。
- 优化递归:如果递归导致性能问题,考虑将其转换为迭代形式,或者使用尾递归优化。
4. 数据结构的选择
- 了解数据结构:熟悉不同数据结构的优缺点,如数组、链表、栈、队列、树、图、哈希表等。
- 选择合适的数据结构:根据问题的需求选择最合适的数据结构。例如,如果需要频繁查找,哈希表可能是一个好选择。
5. 算法优化
- 预处理数据:如果可能,对数据进行预处理,如排序,以加速后续的查找或比较操作。
- 避免不必要的计算:在循环中,确保不会重复计算相同的结果。使用缓存或记忆化技术存储中间结果。
6. 抽象与具体化
- 抽象问题:将具体问题抽象为更一般的模型,这有助于找到通用的解决方案。
- 具体化解决方案:在找到抽象解决方案后,将其具体化以适应特定问题的细节。
7. 代码的可读性与效率
- 编写清晰代码:始终编写清晰、有条理的代码,即使这可能需要更多的代码行。清晰的代码更容易维护和调试。
- 性能优化:在确保代码可读性的同时,寻找提高性能的机会。使用性能分析工具来识别瓶颈。
通过实践这些技巧,将能够更好地理解问题的本质,并开发出既高效又易于理解的解决方案。记住,编程是一个不断学习和实践的过程,通过不断的练习和挑战,编程技能将得到显著提升。
这篇关于每日一题——Python代码实现力扣1. 两数之和(举一反三+思想解读+逐步优化)五千字好文的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





