本文主要是介绍RabbitMQ消息队列的高可靠使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
整体解决方案
TopicExchange型交换机,会根据RouteKey将消息路由至匹配队列(推模式下,消息将被推送至消费者的监听函数处理),消息流转和路由的示意图如下。
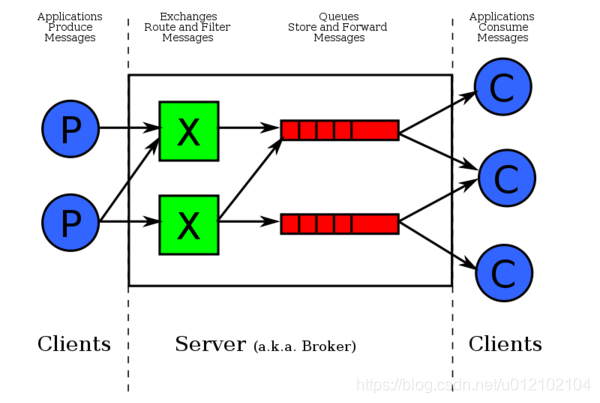

高可靠机制
RabbitMQ的高可靠保障主要在投递、持久化、消费三个方面,分别对应于生产者、消息队列、消费者,具体部流程如下图所示。

生产端可靠性保障
为防止消息在未发送到Broker前就由于网络原因或其他情况导致丢失,生产者端需要保障消息成功送达中间件,手段一般有两种,一是使用事务机制,但这种做法是非异步的,吞吐量性能较差;另一种是确认机制,本例使用确认机制。
- 将Channel设为confirm模式,RabbitMQ会在消息到达Exchange后回调生产者ConfirmCallback接口;(如果消息和队列是可持久化的,那么包含msgId的ack会在消息被写入磁盘之后发出)
- 将Channel设为return模式,若消息没有被路由到任何一个队列,RabbitMQ会回调生产者ReturnCallback接口。
生产端高可靠只能让生产者知道自己投递的消息是否成果到达交换机或某个队列,但是无法知道消费者有没有成功消费。
// 设置消息入队失败回调
rabbitTemplate.setMandatory(true);
rabbitTemplate.setConfirmCallback(new RabbitTemplate.ConfirmCallback() {@Overridepublic void confirm(CorrelationData correlationData, boolean b, String s) {log.debug(s); }
});// 设置消息发送至交换机回调
rabbitTemplate.setReturnCallback(new RabbitTemplate.ReturnCallback() {@Overridepublic void returnedMessage(Message m,int i,String s,String q,String q) {log.debug(s); }
});MessageProperties messageProperties = new MessageProperties();
// 开启消息持久化
messageProperties.setDeliveryMode(MessageDeliveryMode.PERSISTENT);
messageProperties.setReceivedDeliveryMode(MessageDeliveryMode.PERSISTENT);
// 设置消息ID
messageProperties.setMessageId(UUID.randomUUID().toString());
// 设置消息格式
messageProperties.setContentType("application/json");
Message message = new Message("msgBody".getContent().getBytes(), messageProperties);
// 发送消息
rabbitTemplate.send("exchangeName", "routingKey", message);
消息和队列可靠性保障
为防止消息中间件在重启或宕机等场景丢失消息,开启消息和队列的持久化设置。主要有两个步骤:
- 申明队列时,开启durable模式,队列的持久化能保证其本身的元数据不会因异常情况而丢失。
- 发送消息时选择MessageDeliveryMode.PERSISTENT投递模式,消息会被持久化到磁盘,确保消息不会丢失。
/*************** 交换机配置**************/
@Bean
public TopicExchange exchange() {return new TopicExchange(EXCHANGE_NAME);
}/*************** 队列配置**************/
@Bean
public Queue queue() {// 参数2true代表持久化队列return new Queue(QUEUE_NAME, true, false, false);
}@Bean
public Binding binding(Queue queue, TopicExchange exchange) {return BindingBuilder.bind(queue).to(exchange).with(ROUTING_KEY);
}
消费端可靠性保障
为防止消息不能成功送达消费者,需要使用消费确认机制,消费者在订阅队列时将acknowledge-mode设为manual,在消息被成功消费后主动响应。
此处为推模式:即队列把消息推送给监听者
@Component
@RabbitListener(queues = QUEUE_NAME, containerFactory = "rabbitListenerContainerFactory")
public class MsgListener {@Autowiredprivate MsgService msgService;@RabbitHandlerpublic void processStatisticMessage(Message message, Channel channel, Map content) throws Exception {MessageProperties msgProperties = message.getMessageProperties();String messageId = msgProperties.getMessageId();String routingKey = msgProperties.getReceivedRoutingKey();long deliveryTag = msgProperties.getDeliveryTag();// 幂等判断,拒绝重复消息if (msgService.hasDuplicateMsgId(messageId)) {channel.basicReject(deliveryTag, false);return;}try {// 消费消息msgService.process(content, routingKey);channel.basicAck(deliveryTag, false);} catch (Exception e) {channel.basicNack(deliveryTag, false, false);}}
}
复用连接、并发消费
- 使用连接池CachingConnectionFactory复用连接,避免频繁新建销毁等性能开销。缓存模式为CacheMode.CHANNEL。
@Bean
public CachingConnectionFactory cachingConnectionFactory() {CachingConnectionFactory factory = new CachingConnectionFactory(HOST, PORT);// 设置用户名密码factory.setUsername(rabbitHostConfig.getUsername());factory.setPassword(rabbitHostConfig.getPassword());// 设置虚拟主机factory.setVirtualHost(VIRTUAL_HOST);// 消息送达交换机确认factory.setPublisherConfirms(true);factory.setPublisherReturns(true);// 设置缓存模式factory.setCacheMode(CacheMode.CHANNEL);// 设置缓存数factory.setChannelCacheSize(8);return factory;
}@Bean
public RabbitTemplate rabbitTemplate(CachingConnectionFactory cachingConnectionFactory) {RabbitTemplate rabbitTemplate = new RabbitTemplate();rabbitTemplate.setConnectionFactory(cachingConnectionFactory);rabbitTemplate.setMandatory(true);return rabbitTemplate;
}
- 如果异步化的业务不存在顺序性消费需求,可通过设置并发消费来提升消费者性能,且每个消费者可预取多条消息,增加吞吐量。
@Bean
public SimpleRabbitListenerContainerFactory rabbitListenerContainerFactory(CachingConnectionFactory cachingConnectionFactory) {SimpleRabbitListenerContainerFactory factory = new SimpleRabbitListenerContainerFactory();factory.setConnectionFactory(cachingConnectionFactory);// 消息转换器factory.setMessageConverter(new Jackson2JsonMessageConverter());// ack模式factory.setAcknowledgeMode(AcknowledgeMode.MANUAL);// 消费者并发数factory.setConcurrentConsumers(8);// 预取消息数factory.setPrefetchCount(8);return factory;
}
消费幂等性
在消息生产时,使用UUID构建唯一msgId。
在消息消费前,通过判断Redis中msgId来确认是否重复消费;在消息成功消费后,将msgId保存至Redis并设置过期时间。
指数回退策略重试机制
在消息消费重试机制上,摒弃了requeue模式,因为requeue会和幂等性消费产生冲突,最致命的是requeue可能产生循环,导致队列被阻塞。
采用Spring自带的Retry可以在消费端业务逻辑里重试,避免消息重新入队导致的各种问题。这里将回退策略设置为指数型,最多重试3次,初始间隔6秒,每次间隔10倍。
需在启动类加上注解
@EnableRetry
@Override
@Retryable(value = {Exception.class}, maxAttempts = 3, backoff = @Backoff(maxDelay = 600000L, delay = 6000L, multiplier = 10))
public void process(Map content, String type) throws Exception {log.info("process msg:{}", content);
}
死信队列
消息消费时,若重试超限,将消息转发至死信队列,以备人工排查定位或后期做补偿机制。
@Bean(name = "deadQueue")
public Queue deadQueue() {Map<String, Object> args = new HashMap<String, Object>();// 设置队列长度// args.put("x-max-length", 1000);// 设置死信队列args.put("x-dead-letter-exchange", "dlx.exchange");// 持久化队列return new Queue("dlx.queue", true, false, false, args);
}@Bean(name = "deadExchange")
public TopicExchange deadExchange() {return new TopicExchange("dlx.exchange");
}@Bean(name = "deadBinding")
public Binding deadBinding(@Qualifier("deadQueue") Queue queue, @Qualifier("deadExchange") TopicExchange exchange) {return BindingBuilder.bind(queue).to(exchange).with("dead.#");
}
这篇关于RabbitMQ消息队列的高可靠使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





