本文主要是介绍Redis缓存雪崩(主从复制、哨兵模式(脑裂)、分片集群),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
缓存雪崩:
在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。

方法一:
给不同key的TTL添加随机值,以此避免同一时间大量key失效。(用于解决同一时间大量key过期,后面的方法用于解决redis宕机)
方法二:
使用Redis集群提高服务可用性(哨兵模式、分片集群)
主从复制(解决高并发读):
在讲哨兵模式之前,我们需要先了解一下主从复制

单节点处理并发的能力有限,我们需要提供搭建集群来提高应对并发的能力。

主节点命名为master、子节点命名为(slave/replica)。由于redis基本上都是在执行读操作,所以我们只需要安排主节点负责写操作、子节点负责读操作就可以有效的提高应对并发的能力。不过这里就有一个问题,主节点执行了写操作后,怎么和子节点进行数据同步呢?
全量同步:

流程:
(以下是第一次同步的流程)
-
子节点执行replicaof命令建立连接。
这里大家可能会有疑问,子节点什么时侯要建立连接呢?
其实这个命令是在搭建集群的时候执行的,在搭建集群时我们会执行如下命令。
# 服务器 B 执行这条命令以设置服务器A为自己的主节点 replicaof <服务器 A 的 IP 地址> <服务器 A 的 Redis 端口号>
执行完命令后,我们就建立好主从节点之间的连接了。
-
子节点请求数据同步(这里有两个很重要的参数:replid、offest)
-
主节点判断是否是第一次同步。就是通过replid来判断,一个数据集不论增删改查它的replid不变,所以如果子节点的replid和主节点不同,代表一定是第一次同步)
-
是第一次则返回数据版本信息(replid、offest)
-
子节点保存版本信息(这里子节点的replid就和主节点相同了)
-
主节点执行bgsave,生成RDB
-
主节点发送RDB
-
子节点清空数据并加载RDB(根据RDB生成数据)
-
主节点记录RDB期间所有的命令(有一步的原因:在子节点清空并生成数据的过程中,主节点可能会接收到写操作,但是发送的RDB里面数据是接收到写操作之前的数据,所以需要一个repl_baklog来记录生成RDB后接收的操作)
-
主节点发送repl_baklog中的命令(再次进行同步,确保数据相同)
-
子节点执行接受到的命令
(以下是非第一次同步的流程)
-
主节点发送repl_baklog中的命令(这里就用到刚刚说的重要的变量offest,在第一次同步时,步骤4发送了第一次offest,此后步骤10只需要根据offest,就可以判断需要发送哪些数据,比如说第一次步骤4发送的offest为5,而在子节点生成数据期间,repl_baklog记录的数据为7条,此时主节点的offest就变成了 5+7=12,那么主节点就会发送 12-5=7 条最新的命令给子节点以完成同步)
-
子节点执行接受到的命令
增量同步:
实际上和全量同步的非第一次同步流程很像,但是增量同步主要应对slave重启
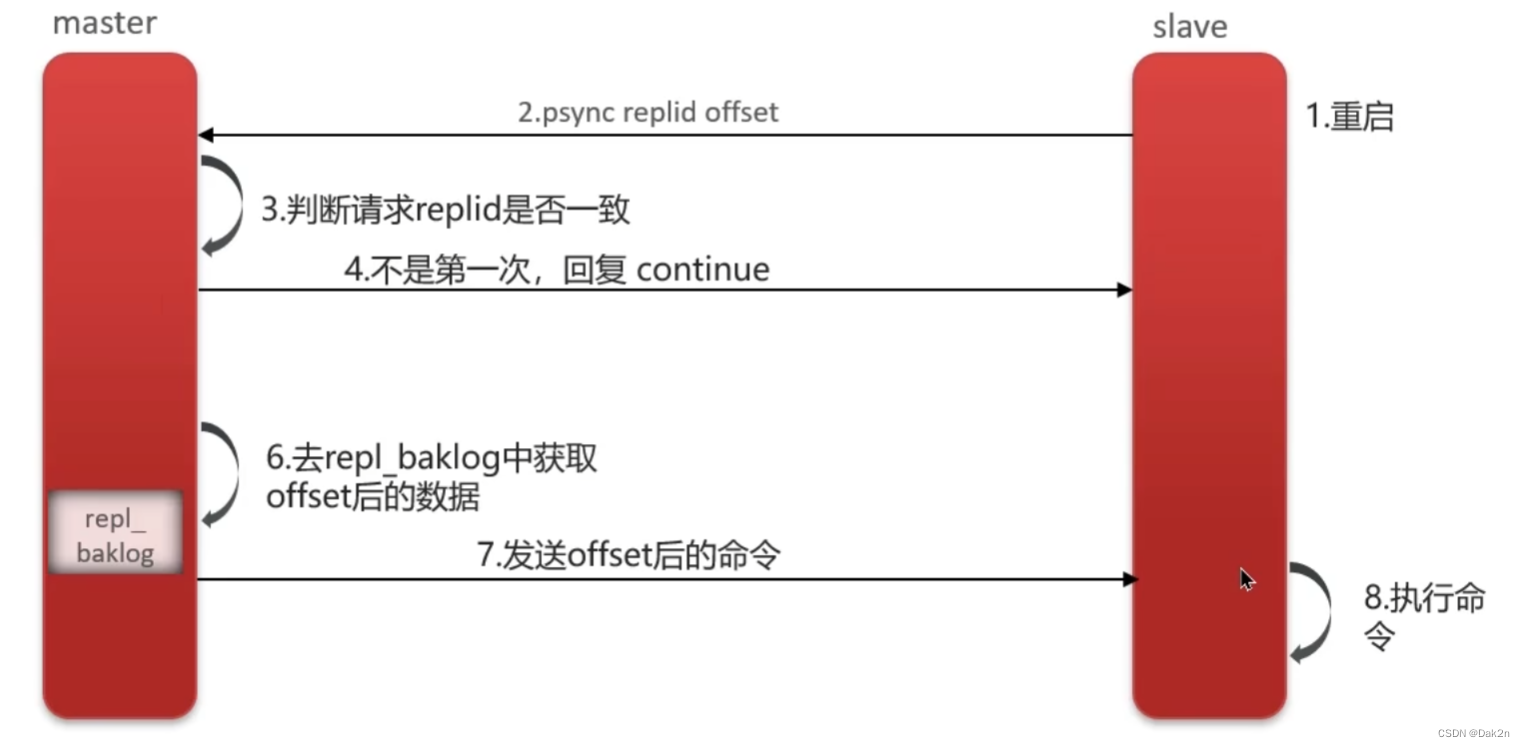
流程:
-
子节点重启
-
子节点请求数据同步(这里同样会发送两个参数:replid、offest)
-
主节点判断是否是第一次(replid是否一致,不过这里我们建立过链接,只是因为slave重启了要重新同步数据)
-
不是第一次,主节点发送continue
-
主节点根据slave传入的offest(步骤2)来判断要发送那些repl_baklog中的命令
-
主节点发送repl_baklog中的命令
-
子节点执行命令
哨兵模式(解决高可用):
主从复制存在一个问题,如果主节点挂了,那么整个集群就不可用了(只有主节点执行写操作),为了应对这种情况,redis提供了哨兵机制。

监控:
用于判断节点是否可用

自动故障恢复:
当master节点被判断下线,哨兵就会进行选举

选举逻辑:
-
根据断开时间排除部分节点
-
判断slave-priority中的优先级,最小的被选举为主节点
-
如果slave-priority相同,就根据offest判断,offest越大代表数据越全面
-
最后是根据slave节点的运行id,每个slave节点在运行时都有一个id,越小优先级越高
脑裂问题:
哨兵模式会出现的一个问题,如果说由于某些原因(可能是网络原因),哨兵(sentinel)和master断开了连接(图一),但是master和Clinet的连接并没有中断,由于哨兵模式特有的自动故障修复功能,哨兵会在slave中重新选举出新的master节点(要注意,原本的master节点并没有下线,所有的数据操作仍然是在Client和原本的master之间进行),过了一段时间后,哨兵(sentinel)连接上了原本的主节点,但是由于哨兵认可的是新选举的master节点,所以原本的master节点会被降级为slave节点(图二),然后被降级的salve节点就会清空自己的数据重新申请新master节点的数据,这样会导致脑裂过程中Client和原本的master之间交换的数据全部丢失。

图一

图二
解决方法:
-
设置master节点 min-replicas-to-write 1(表示master节点最少要有一个slave节点,不然不进行数据操作)
-
设置master节点 min-replicas-max-lag 5(表示master节点与slave节点最久5s要通信一次,不然不进行数据操作)
分片集群:
主从复制解决了高并发读的问题,但是因为只有一个master在写,所以无法解决高并发写的问题,如果我们有多个master,是不是就可以解决高并发写的问题了?

-
多个master解决高并发写的问题
-
每个master有多个slave解决高并发读的问题(每个slave都可以读)
-
master通过ping检测彼此状态(sentinel相同功能,如果发现客观下线就在slave中新选举一个master,解决高可用问题)
-
客户端请求可以访问集群任意节点,最终都会被转发到正确节点(要理解这个就要看下面的内容)

简单来说,不管是传进来什么样的数据,都会通过哈希函数计算出哈希值然后存放在对应区间的插槽中(这里要注意,如果key前面有大括号,就将大括号中的数据用于计算,如果没有大括号,就将key本身用于计算)
方法三:
给缓存业务添加降级限流策略(比如说nginx限流,sentinel降级)
方法四:
给业务添加多级缓存(充分利用请求处理的每个环节,分别添加缓存)

这篇关于Redis缓存雪崩(主从复制、哨兵模式(脑裂)、分片集群)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







