本文主要是介绍计算机组成原理 —— 存储系统(主存储器基本组成),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
计算机组成原理 —— 存储系统(主存储器基本组成)
- 0和1的硬件表示
- 整合结构
- 寻址
- 按字寻址和按字节寻址
- 按字寻址
- 按字节寻址
- 区别总结
- 字寻址到字节寻址转化
我们今天来看一下主存储器的基本组成:
0和1的硬件表示
我们知道一个主存储器是由存储体,MAR,MDR 组成的:
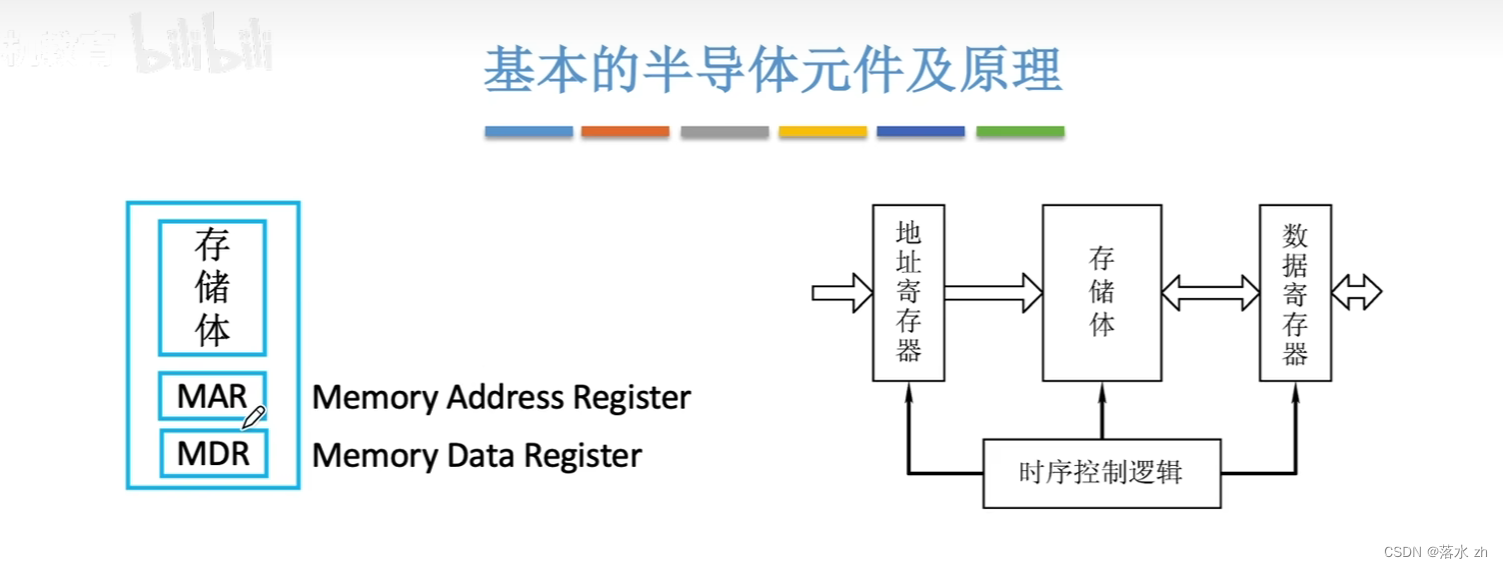
存储体中,我们存储了许多的二进制数据,这些二进制数据都是存储在一个存储单元上的,一个存储单元可以存放一个1或者0:
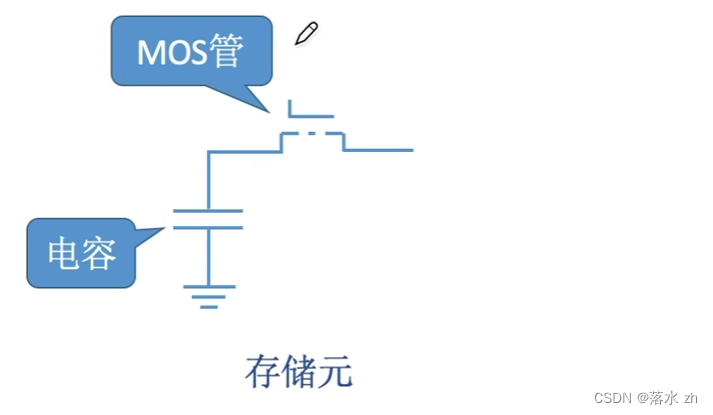
这里MOS管可以理解为一个开关,当电压足够大时,MOS管就会开通。
假如我在电容上充了1v的电压,这个时候,如果我要读取这个1v,那我就要给MOS管施加一个高电压,使之流通,这样在检测端就可以检测到这个1v的电压:
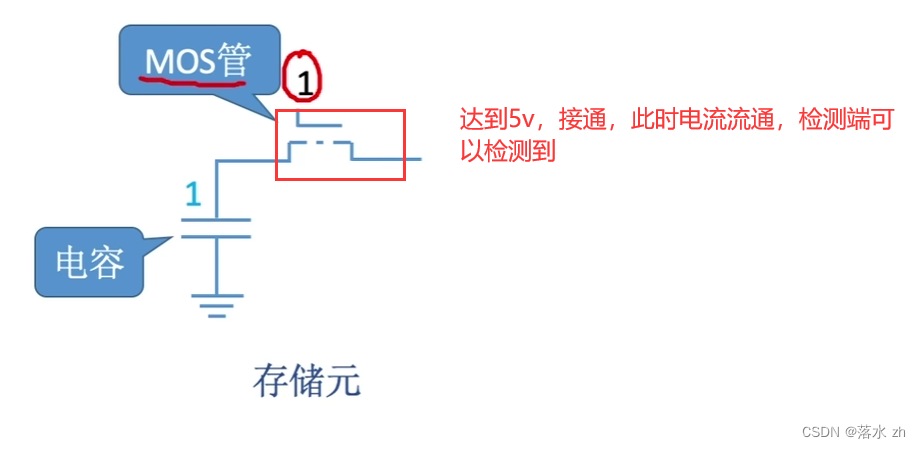
0也是这样储存的。
通过这样的原理,我们将一个一个的存储元排排站,就可以存储连续的二进制数:
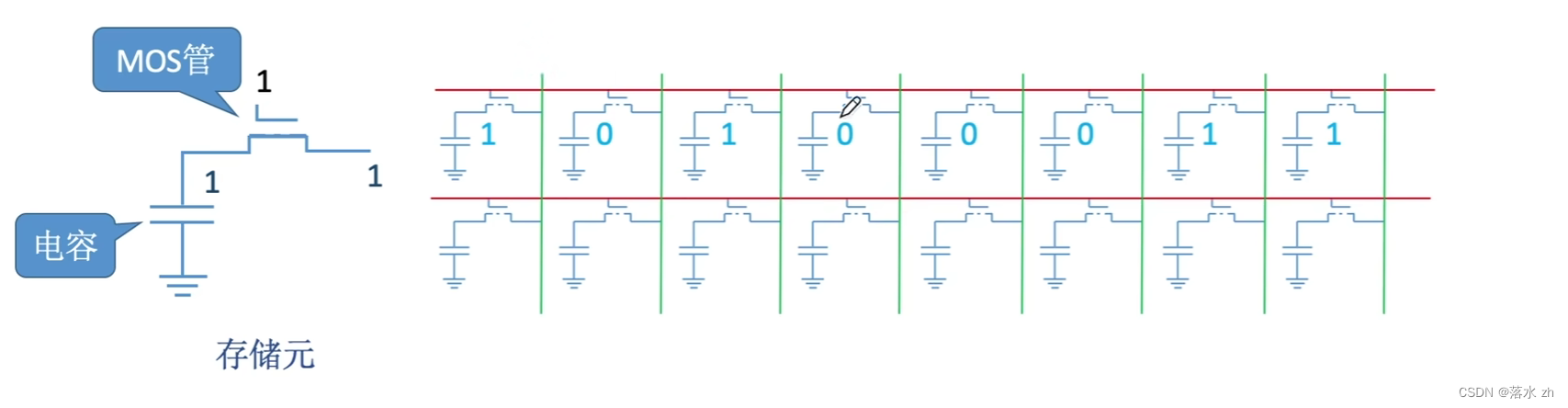 其中红色的线是挑选线(字选线),只要往红线上通高电压,我就可以选中这一行的数据,绿色的线是数据的运送线(数据线),将数据(0或1)运送出去。
其中红色的线是挑选线(字选线),只要往红线上通高电压,我就可以选中这一行的数据,绿色的线是数据的运送线(数据线),将数据(0或1)运送出去。
我们称一行的存储元,为一个存储单元:
 很多个存储单元,为一个存储体:
很多个存储单元,为一个存储体:

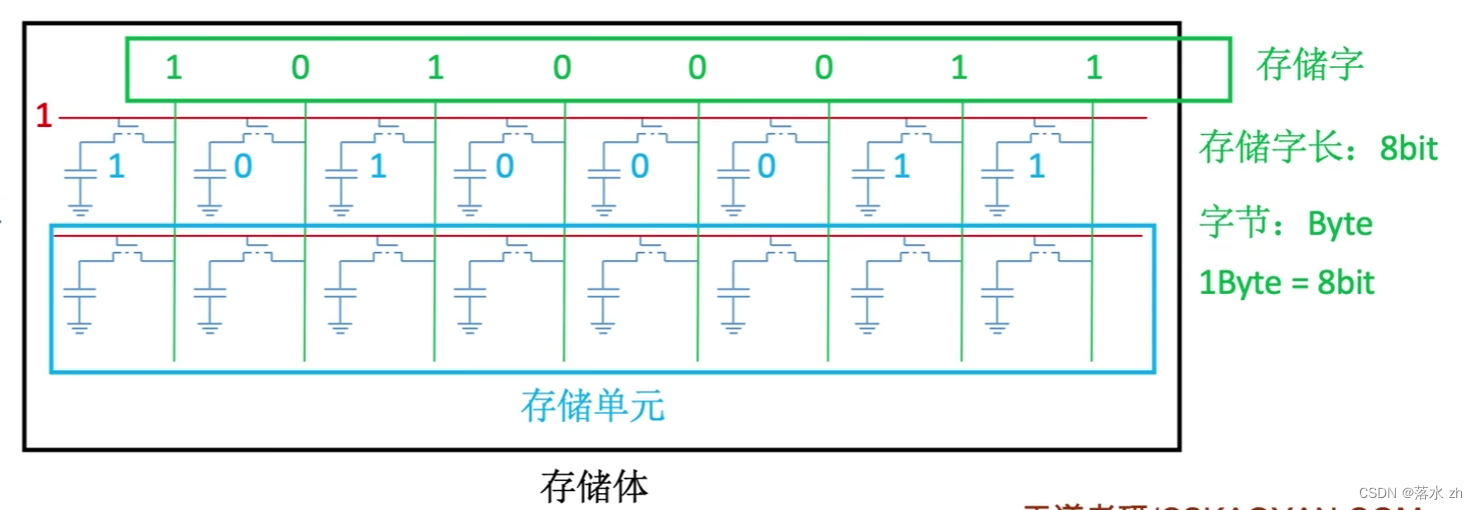
整合结构
现在我们知道0和1是怎么存储的了,现在的问题是,怎么设计呢?
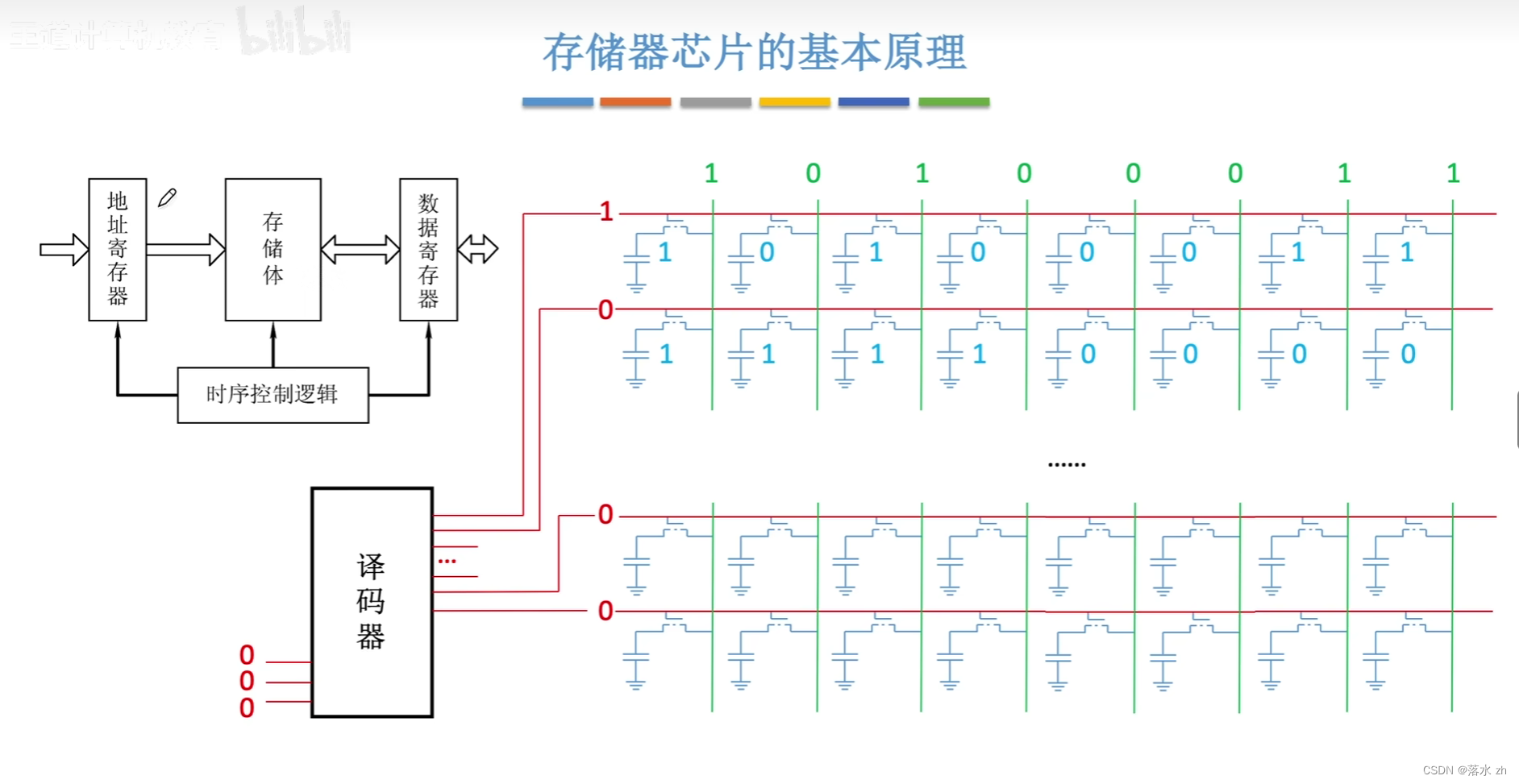 首先第一个问题:选线,我该怎样实现我想选那一条线就选那一条线呢?
首先第一个问题:选线,我该怎样实现我想选那一条线就选那一条线呢?
这就是MAR的功能,MAR会储存我们要选的线的序号,通过译码器,传送到对应的线(字选线)上:
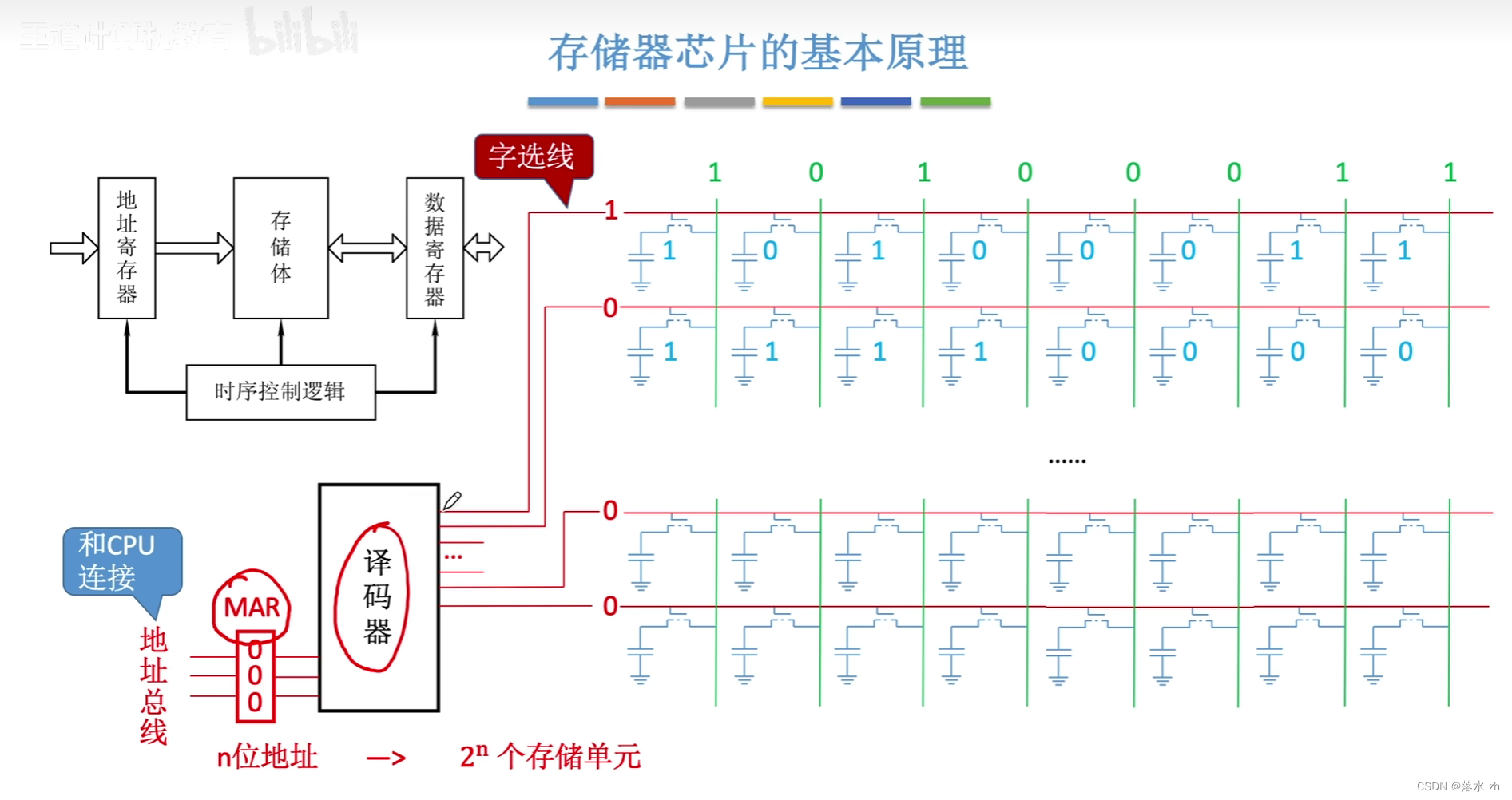
接下来就是,我读出来的数据,该放到哪里呢?,这就是MDR的功能了,读出来的数据通过位线(数据线),放到MDR中,然后CPU通过数据总线,读取数据:
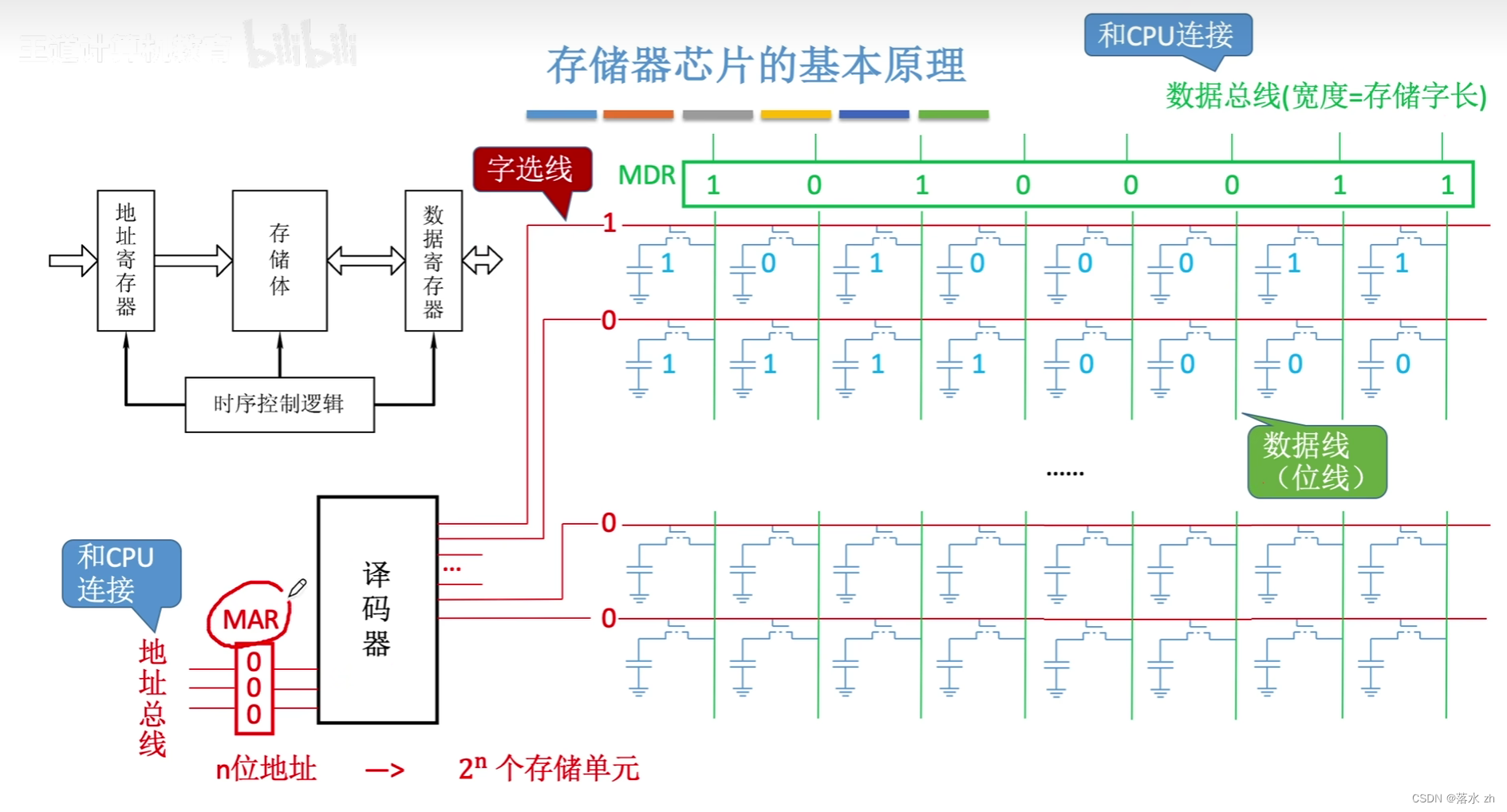
同时我们还要增加一个控制电路,控制MAR,译码器和MDR:
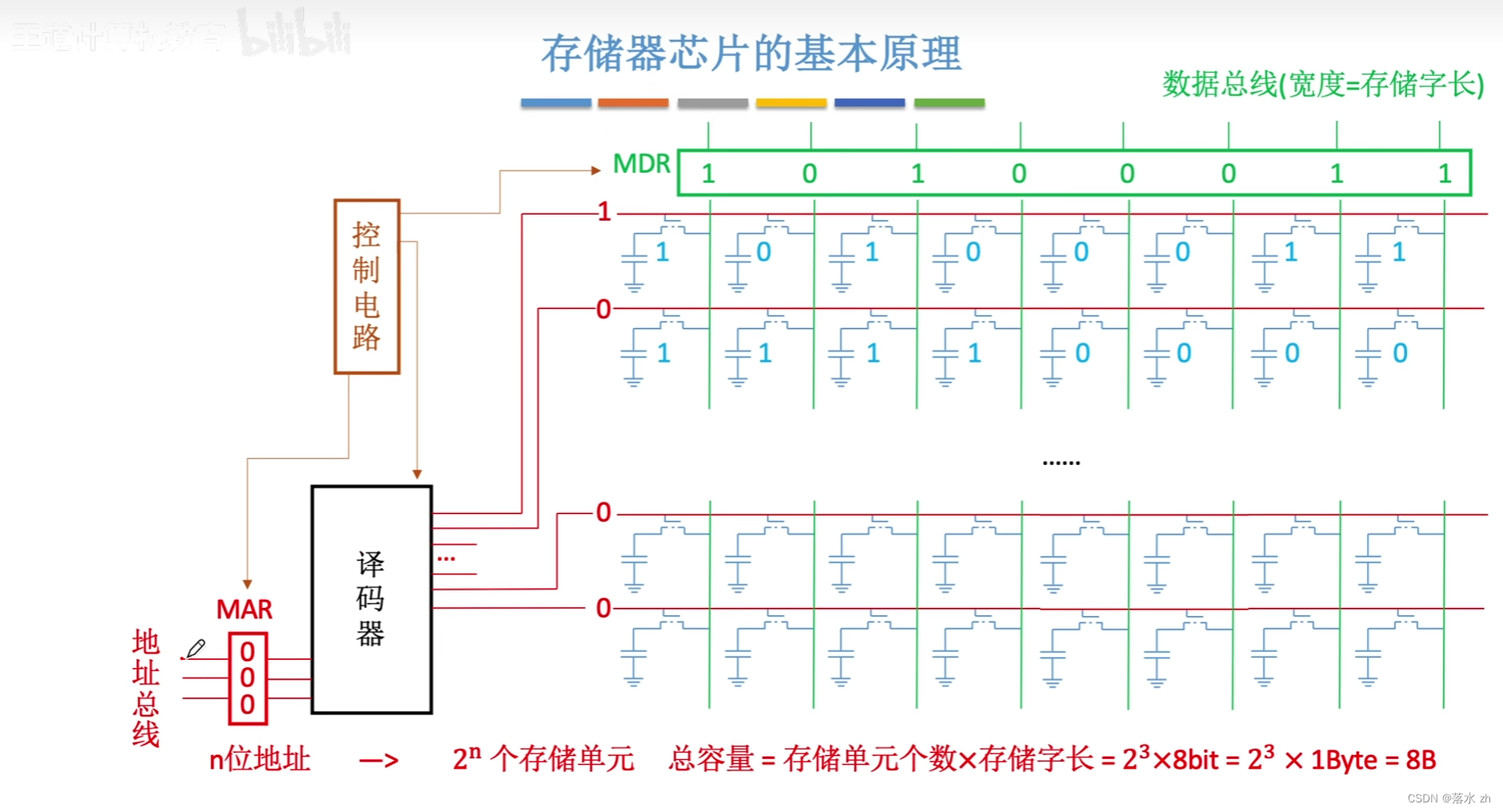 控制电路主要是为了保证电流稳定,稳定之后,再由个部分部件处理
控制电路主要是为了保证电流稳定,稳定之后,再由个部分部件处理
除了这些,我们还要增加片选线(当有多块芯片时,方便我们选择我们想要的芯片)
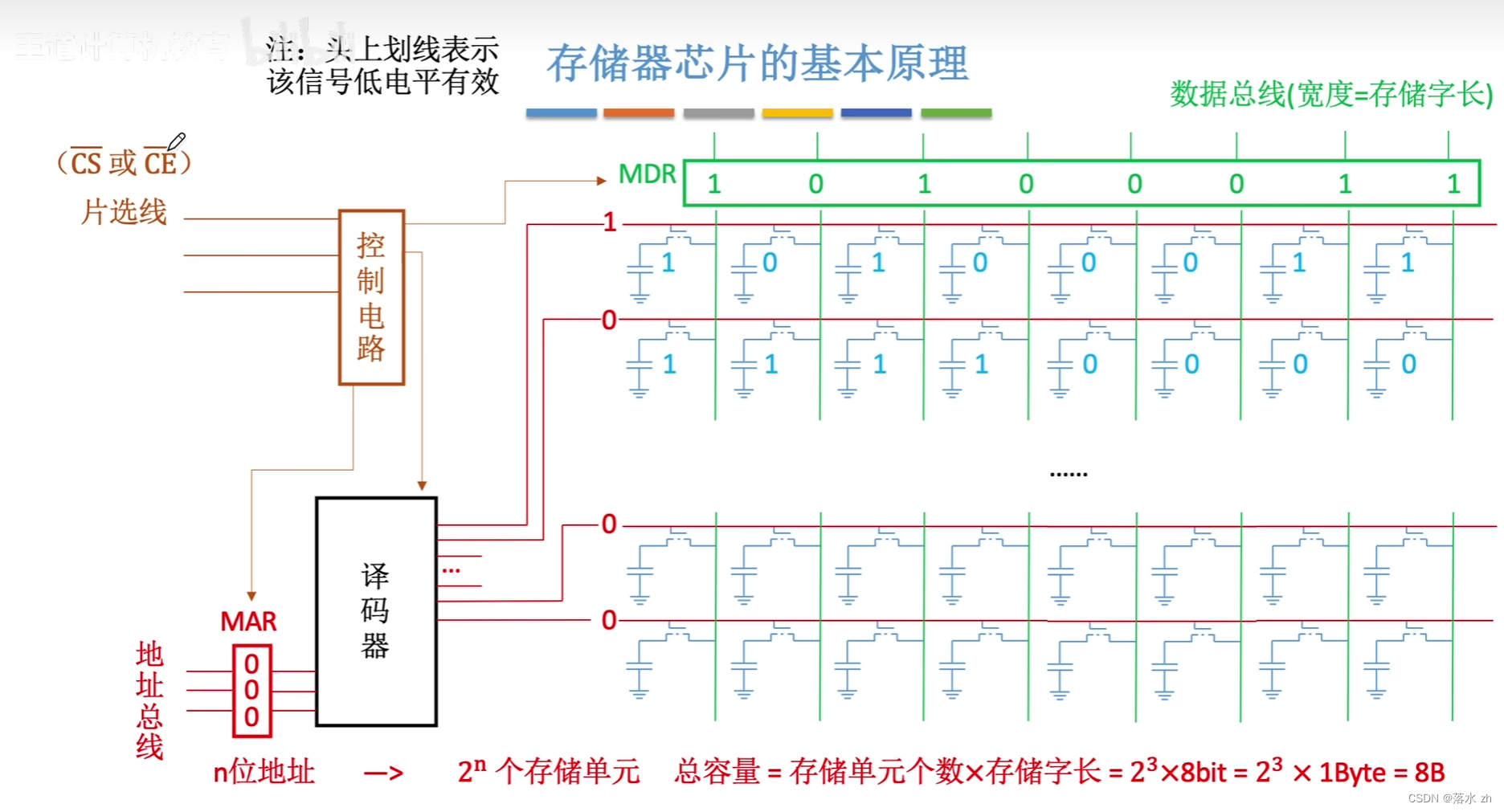
还有读写控制线,有时候是两条,有时候是一条:
 最后封装出来可能是这样的:
最后封装出来可能是这样的:
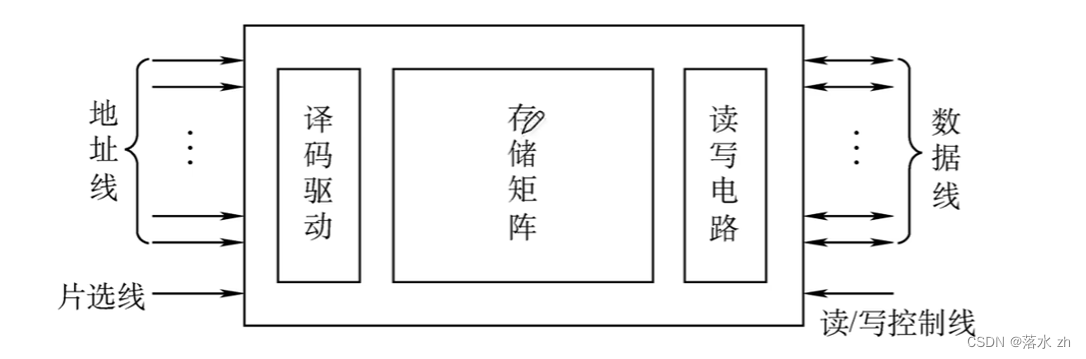
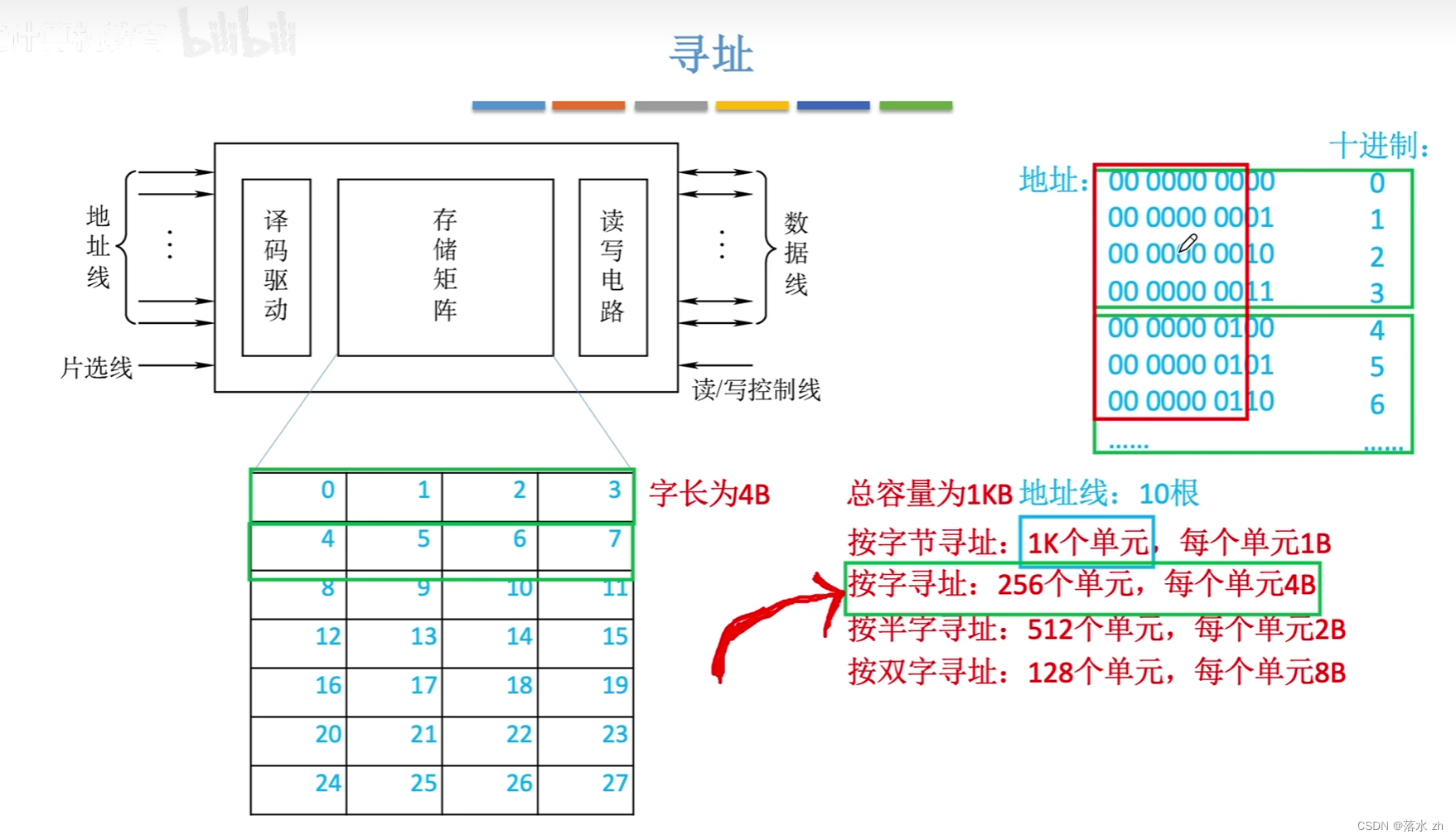
寻址
按字寻址和按字节寻址
按字寻址和按字节寻址是计算机系统中两种不同的数据访问方式,它们分别适用于不同的情景和需求,下面详细解释两者的特点和区别:
按字寻址
- 定义:按字寻址是指处理器直接访问内存中与自身字长相同大小的数据块(即一个“字”)。例如,在32位系统中,处理器一次处理的数据为32位,那么按字寻址就是一次性访问4字节的数据。
- 优势:提高数据处理效率,减少访存次数,尤其适合进行大规模数据操作和高性能计算,因为减少了指令执行和数据传输的开销。
- 限制:要求数据必须按照处理器字长对齐存放,否则可能导致无法直接访问或需要额外的处理步骤来调整数据对齐。
按字节寻址
- 定义:按字节寻址是指处理器能够直接访问内存中的每一个字节。这意味着可以灵活地读取或写入任意字节,而不必受限于字长。
- 优势:灵活性高,适用于处理字符串、字符数据或需要精确控制数据读写位置的场景。它允许对数据进行细粒度的操作。
- 限制:相比按字寻址,按字节寻址可能会降低数据处理速度,尤其是在需要处理大量连续数据时,因为它可能需要更多的访存操作。
区别总结
- 数据单位:按字寻址处理的数据单位是处理器字长的整数倍,而按字节寻址处理的是单个字节。
- 效率与灵活度:按字寻址在处理大数据块时效率高,但不如按字节寻址灵活;按字节寻址虽灵活,但在大规模数据操作时效率较低。
- 对齐要求:按字寻址通常要求数据对齐,而按字节寻址没有此限制。
- 应用场合:按字寻址适用于高性能计算、大规模数据处理;按字节寻址更适合文本处理、数据解析等需要精细数据操作的场景。
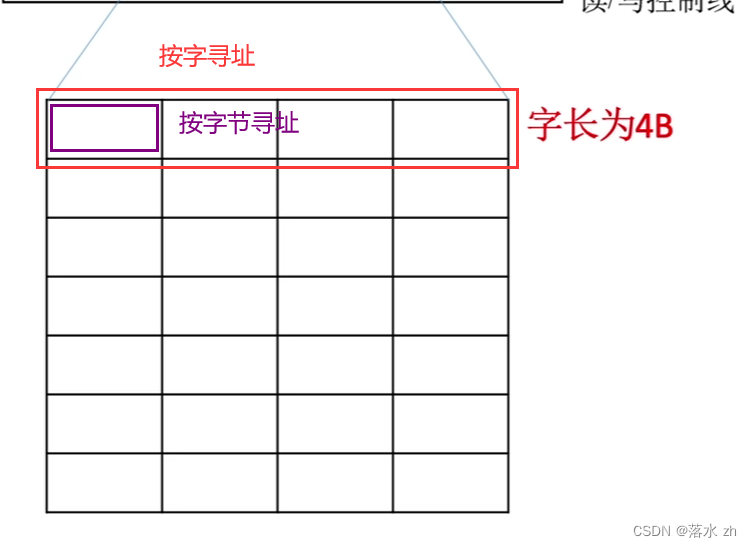
在实际应用中,现代处理器通常支持这两种寻址方式,系统根据具体任务的需求选择最合适的访问模式。
字寻址到字节寻址转化
比如之前我是按照字寻址的,那么对应的图应该是这样:
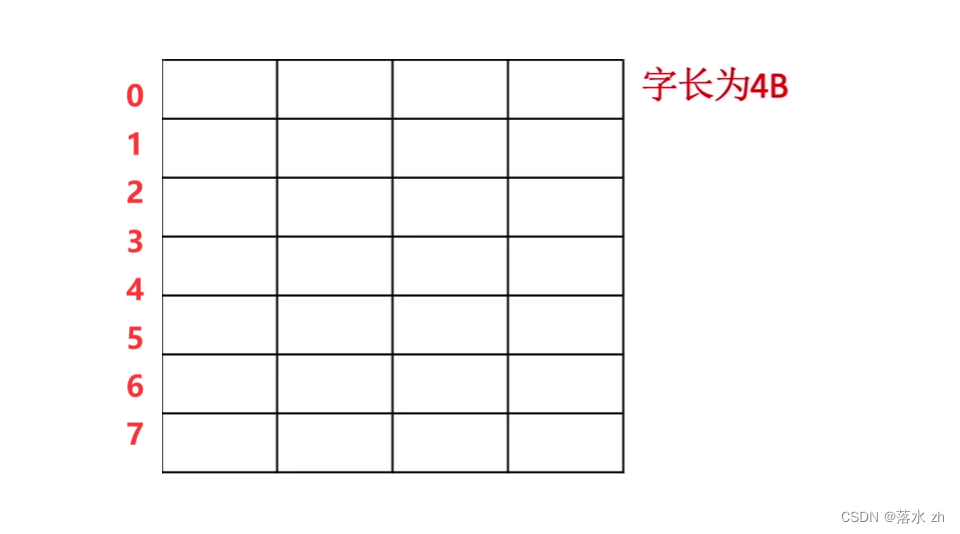 我们想通过字的地址来反推出字节的地址,这里我们1字是32bit,1个字节是8bit,所以我们只要将字地址乘4就可以得出字节地址:
我们想通过字的地址来反推出字节的地址,这里我们1字是32bit,1个字节是8bit,所以我们只要将字地址乘4就可以得出字节地址:
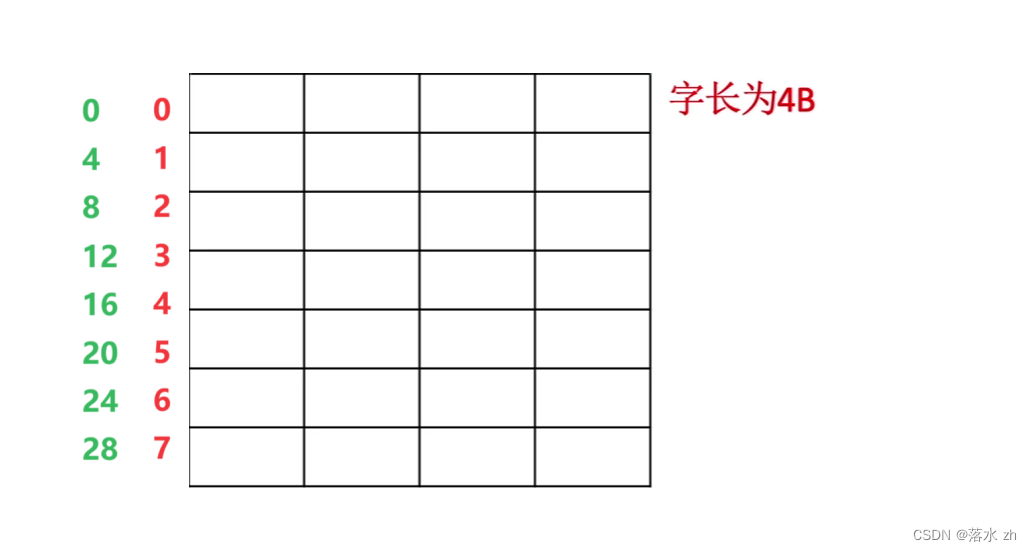 其他寻址方式,以此类推:
其他寻址方式,以此类推:
这篇关于计算机组成原理 —— 存储系统(主存储器基本组成)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








