本文主要是介绍使用Python和NLTK进行NLP分析的高级指南,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在本文中,将利用数据集来比较和分析自然语言。
本文涵盖的基本构建块是:
- WordNet和同义词集
- 相似度比较
- 树和树岸
- 命名实体识别
WordNet和同义词集
WordNet是NLTK中的大型词汇数据库语料库。WordNet维护与名词,动词,形容词,副词,同义词,反义词等相关的单词的认知同义词(通常称为同义词集)。
WordNet是一个非常有用的文本分析工具。根据许多许可(从开源到商业),它可用于多种语言(中文,英语,日语,俄语,西班牙语等)。第一个WordNet是由普林斯顿大学在类似MIT的许可下为英语创建的。
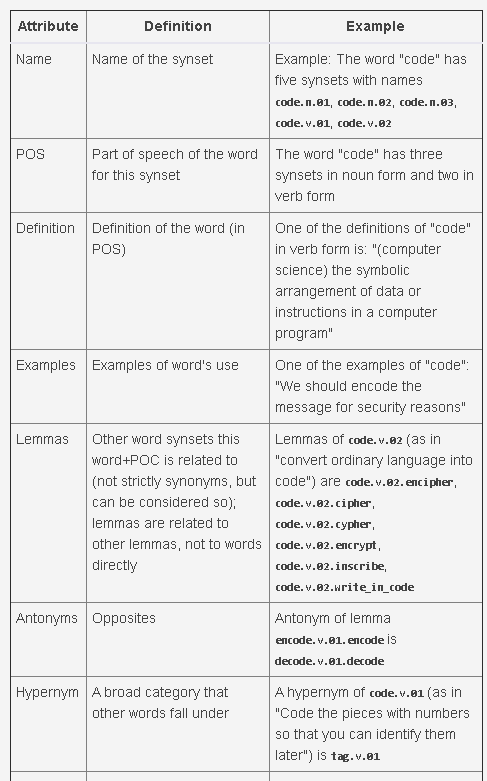
一个单词通常根据其含义和词性与多个同义词集相关联。每个同义词集通常提供以下属性:还有其他一些属性,您可以在中的nltk/corpus/reader/wordnet.py源文件中找到它们<your python install>/Lib/site-packages。
某些代码可能有助于解决这个问题。
这个辅助函数:
def synset_info(synset):print("Name", synset.name())print("POS:", synset.pos())print("Definition:", synset.definition())print("Examples:", synset.examples())print("Lemmas:", synset.lemmas())print("Antonyms:", [lemma.antonyms() for lemma in synset.lemmas() if len(lemma.antonyms()) > 0])print("Hypernyms:", synset.hypernyms())print("Instance Hypernyms:", synset.instance_hypernyms())print("Part Holonyms:", synset.part_holonyms())print("Part Meronyms:", synset.part_meronyms())print()
synsets = wordnet.synsets('code')如下所示
5 synsets:
Name code.n.01
POS: n
Definition: a set of rules or principles or laws (especially written ones)
Examples: []
Lemmas: [Lemma('code.n.01.code'), Lemma('code.n.01.codification')]
Antonyms: []
Hypernyms: [Synset('written_communication.n.01')]
Instance Hpernyms: []
Part Holonyms: []
Part Meronyms: []...Name code.n.03
POS: n
Definition: (computer science) the symbolic arrangement of data or instructions in a computer program or the set of such instructions
Examples: []
Lemmas: [Lemma('code.n.03.code'), Lemma('code.n.03.computer_code')]
Antonyms: []
Hypernyms: [Synset('coding_system.n.01')]
Instance Hpernyms: []
Part Holonyms: []
Part Meronyms: []...Name code.v.02
POS: v
Definition: convert ordinary language into code
Examples: ['We should encode the message for security reasons']
Lemmas: [Lemma('code.v.02.code'), Lemma('code.v.02.encipher'), Lemma('code.v.02.cipher'), Lemma('code.v.02.cypher'), Lemma('code.v.02.encrypt'), Lemma('code.v.02.inscribe'), Lemma('code.v.02.write_in_code')]
Antonyms: []
Hypernyms: [Synset('encode.v.01')]
Instance Hpernyms: []
Part Holonyms: []
Part Meronyms: []
同义词集和引理遵循可以可视化的树结构:
def hypernyms(synset):return synset.hypernyms()synsets = wordnet.synsets('soccer')
for synset in synsets:print(synset.name() + " tree:")pprint(synset.tree(rel=hypernyms))print()
code.n.01 tree:
[Synset('code.n.01'),[Synset('written_communication.n.01'),...code.n.02 tree:
[Synset('code.n.02'),[Synset('coding_system.n.01'),...code.n.03 tree:
[Synset('code.n.03'),...code.v.01 tree:
[Synset('code.v.01'),[Synset('tag.v.01'),...code.v.02 tree:
[Synset('code.v.02'),[Synset('encode.v.01'),...
WordNet不能涵盖所有单词及其信息(今天大约有170,000个英语单词,而最新版本的WordNet则大约有155,000个单词),但这是一个很好的起点。在学习了此构建基块的概念之后,如果发现它不足以满足您的需求,则可以迁移到另一个。或者,您可以构建自己的WordNet!
自己尝试
使用Python库,从开放源代码下载Wikipedia的页面,并列出所有单词的同义词集和引理。
相似度比较
相似度比较是一个标识两个文本之间相似度的构件。它在搜索引擎,聊天机器人等中具有许多应用程序。
例如,“足球”和“足球”这两个词是否相关?
syn1 = wordnet.synsets('football')
syn2 = wordnet.synsets('soccer')# A word may have multiple synsets, so need to compare each synset of word1 with synset of word2
for s1 in syn1:for s2 in syn2:print("Path similarity of: ")print(s1, '(', s1.pos(), ')', '[', s1.definition(), ']')print(s2, '(', s2.pos(), ')', '[', s2.definition(), ']')print(" is", s1.path_similarity(s2))print()
Path similarity of:
Synset('football.n.01') ( n ) [ any of various games played with a ball (round or oval) in which two teams try to kick or carry or propel the ball into each other's goal ]
Synset('soccer.n.01') ( n ) [ a football game in which two teams of 11 players try to kick or head a ball into the opponents' goal ]is 0.5Path similarity of:
Synset('football.n.02') ( n ) [ the inflated oblong ball used in playing American football ]
Synset('soccer.n.01') ( n ) [ a football game in which two teams of 11 players try to kick or head a ball into the opponents' goal ]is 0.05
单词的最高路径相似性得分是0.5,表示它们密切相关。
那么“代码”和“错误”呢?这些词在计算机科学中的相似度得分是:
Path similarity of:
Synset('code.n.01') ( n ) [ a set of rules or principles or laws (especially written ones) ]
Synset('bug.n.02') ( n ) [ a fault or defect in a computer program, system, or machine ]is 0.1111111111111111
...
Path similarity of:
Synset('code.n.02') ( n ) [ a coding system used for transmitting messages requiring brevity or secrecy ]
Synset('bug.n.02') ( n ) [ a fault or defect in a computer program, system, or machine ]is 0.09090909090909091
...
Path similarity of:
Synset('code.n.03') ( n ) [ (computer science) the symbolic arrangement of data or instructions in a computer program or the set of such instructions ]
Synset('bug.n.02') ( n ) [ a fault or defect in a computer program, system, or machine ]is 0.09090909090909091
这些是最高的相似性评分,表明它们是相关的。
NLTK提供了多个相似性评分器,例如:
- 路径相似度
- lch_similarity
- wup_similarity
- res_similarity
- jcn_similarity
- lin_similarity
树和树岸
使用NLTK,您可以树形形式表示文本的结构,以帮助进行文本分析。
这是一个例子:
预处理并带有词性(POS)标记的简单文本:
import nltktext = "I love open source" # Tokenize to words words = nltk.tokenize.word_tokenize(text) # POS tag the words words_tagged = nltk.pos_tag(words)
您必须定义语法以将文本转换为树形结构。本示例使用基于Penn Treebank标签的简单语法。
# A simple grammar to create tree
grammar = "NP: {<JJ><NN>}"
接下来,使用语法创建树:
# Create tree parser = nltk.RegexpParser(grammar) tree = parser.parse(words_tagged) pprint(tree)
这将产生:
Tree('S', [('I', 'PRP'), ('love', 'VBP'), Tree('NP', [('open', 'JJ'), ('source', 'NN')])])您可以通过图形更好地看到它。
tree.draw()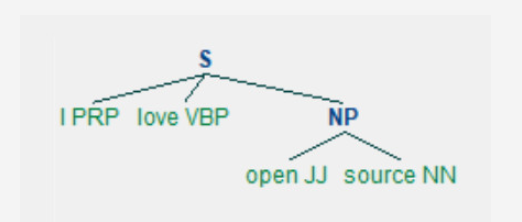
这种结构有助于正确解释文本的含义。例如,在此文本中标识主题:
subject_tags = ["NN", "NNS", "NP", "NNP", "NNPS", "PRP", "PRP$"]
def subject(sentence_tree):for tagged_word in sentence_tree:# A crude logic for this case - first word with these tags is considered subjectif tagged_word[1] in subject_tags:return tagged_word[0]print("Subject:", subject(tree))
它显示“ I”是主题:
Subject: I这是适用于大型应用程序的基本文本分析构建块。例如,当用户说“从1月1日起为我的妈妈Jane预订从伦敦飞往纽约的航班”时,使用此代码块的聊天机器人可以将请求解释为:
动作:书
什么:飞行
旅行者:简
来自:伦敦
到纽约
日期:1月1日(明年)
树库是指带有预标记树的语料库。开源,有条件的免费使用和商业树库可用于多种语言。英文最常用的是Penn Treebank,摘自《华尔街日报》,其子集包含在NLTK中。使用树库的一些方法:
words = nltk.corpus.treebank.words() print(len(words), "words:") print(words)tagged_sents = nltk.corpus.treebank.tagged_sents() print(len(tagged_sents), "sentences:") print(tagged_sents)
100676 words:['Pierre', 'Vinken', ',', '61', 'years', 'old', ',', ...]3914 sentences:[[('Pierre', 'NNP'), ('Vinken', 'NNP'), (',', ','), ('61', 'CD'), ('years', 'NNS'), ('old', 'JJ'), (',', ','), ('will', 'MD'), ('join', 'VB'), ('the', 'DT'), ('board', 'NN'), ('as', 'IN'), ('a', 'DT'), ('nonexecutive', 'JJ'), ('director', 'NN'), ...]
See tags in a sentence:
sent0 = tagged_sents[0]
pprint(sent0)
[('Pierre', 'NNP'), ('Vinken', 'NNP'), (',', ','), ('61', 'CD'), ('years', 'NNS'),...
Create a grammar to convert this to a tree:
grammar = '''Subject: {<NNP><NNP>}SubjectInfo: {<CD><NNS><JJ>}Action: {<MD><VB>}Object: {<DT><NN>}Stopwords: {<IN><DT>}ObjectInfo: {<JJ><NN>}When: {<NNP><CD>}
'''
parser = nltk.RegexpParser(grammar)
tree = parser.parse(sent0)
print(tree)
(S(Subject Pierre/NNP Vinken/NNP),/,(SubjectInfo 61/CD years/NNS old/JJ),/,(Action will/MD join/VB)(Object the/DT board/NN)as/INa/DT(ObjectInfo nonexecutive/JJ director/NN)(Subject Nov./NNP)29/CD./.)
See it graphically:
tree.draw()
NLTK的内置命名实体标记器使用PENN的自动内容提取(ACE)程序,可检测常见的实体,例如组织,人员,位置,设施和GPE(地缘政治实体)。
这篇关于使用Python和NLTK进行NLP分析的高级指南的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






