本文主要是介绍编译原理-各章典型题型+思路求解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
第2章文法和语言习题

基础知识:

思路:


基础知识:

思路:


基础知识:

编译原理之 短语&直接短语&句柄 定义与区分_编译原理短语,直接短语,句柄-CSDN博客
思路:
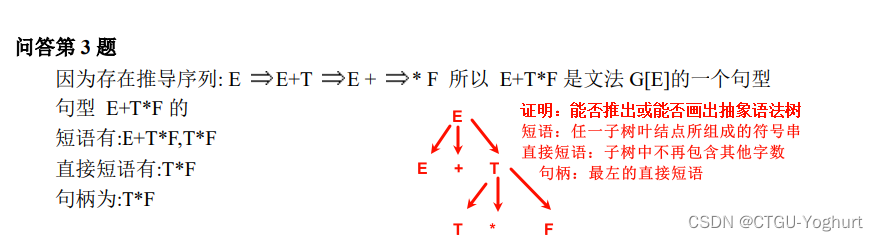
题目:

基础解释:
 简单来说:
简单来说:
上下文无关文法就是这个文法中所有的产生式左边只有一个非终结:
例如:S->Abc
上下文无关文法就是第一个产生式左边有不止一个符号
例如:Sa->Abc
思路:



编译原理 —— 正规式、正规集和正则定义-CSDN博客
【20200401】编译原理课程课业打卡十二之求解正规文法对应正规式_正规式s=(o|10)*-CSDN博客
思路:

第3章词法分析习题

基础解释:

思路:
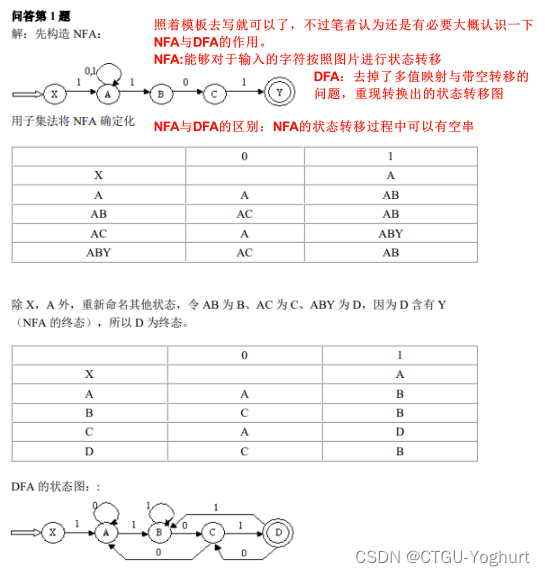
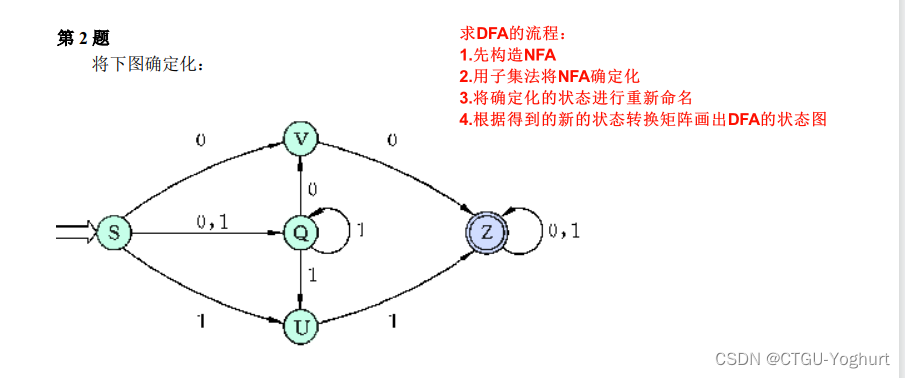 思路:
思路:
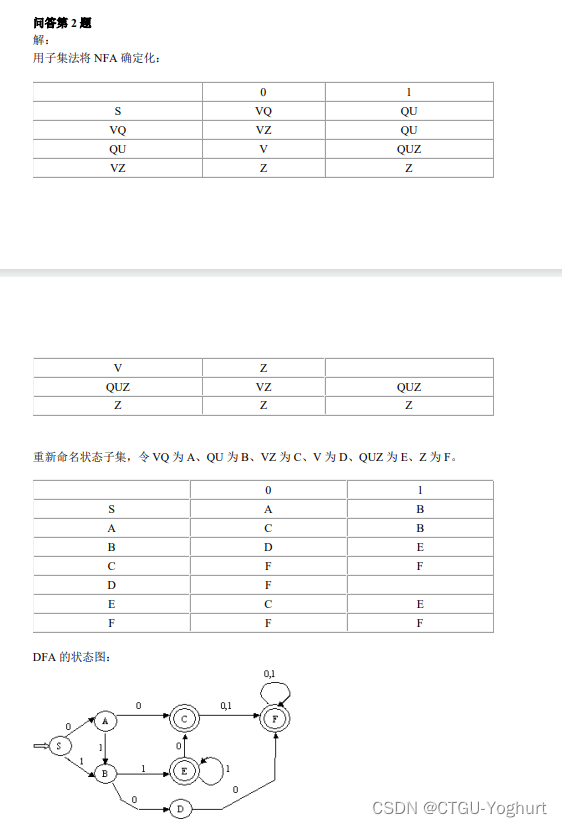
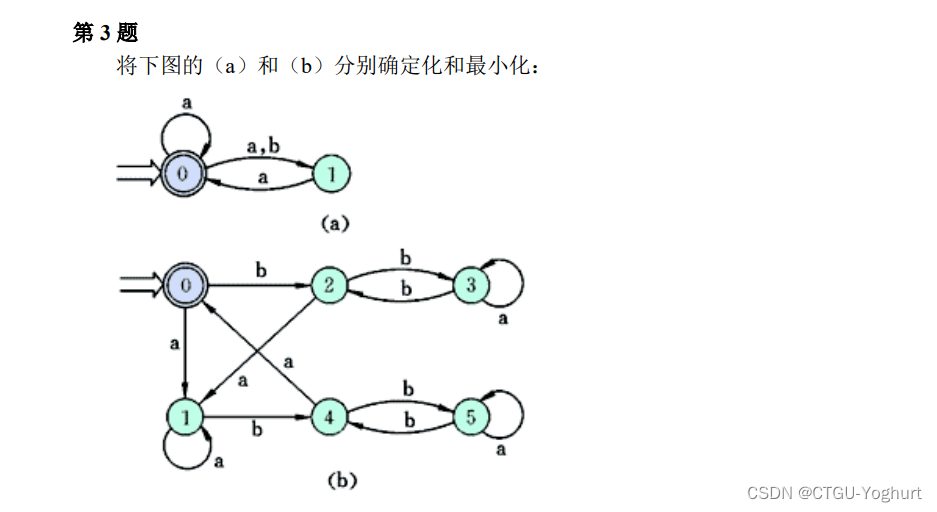
基础解释:
正规式->最小化DFA说明 - 知乎 (zhihu.com)
思路:


基础知识:

思路:
先写出满足条件的正规式,由正规式构造NFA,再把NFA确定化和最小化
对于正规式的构造:
题目给定为字符表有0、1两种字符,则我们可以得到(0|1)*的正规式。
又由于每一个1后面都有一个0,故每次出现1必然为10的形式
故得到正规式:(0|10)*
(答案给的正规式差不多,我们最终也可以得到化简的答案,因为)

第4章自顶向下语法分析习题

基础知识:


对于不带回溯:采用提取公共因子的方法,即让候选首符号集变成两两不相交,不会出现读取一个一个符号后发现下一个符号不匹配又要回到上一个读取位置的情况。



推荐博客:
编译原理第四章总结_不带回溯的递归子程序是什么意思-CSDN博客
思路:


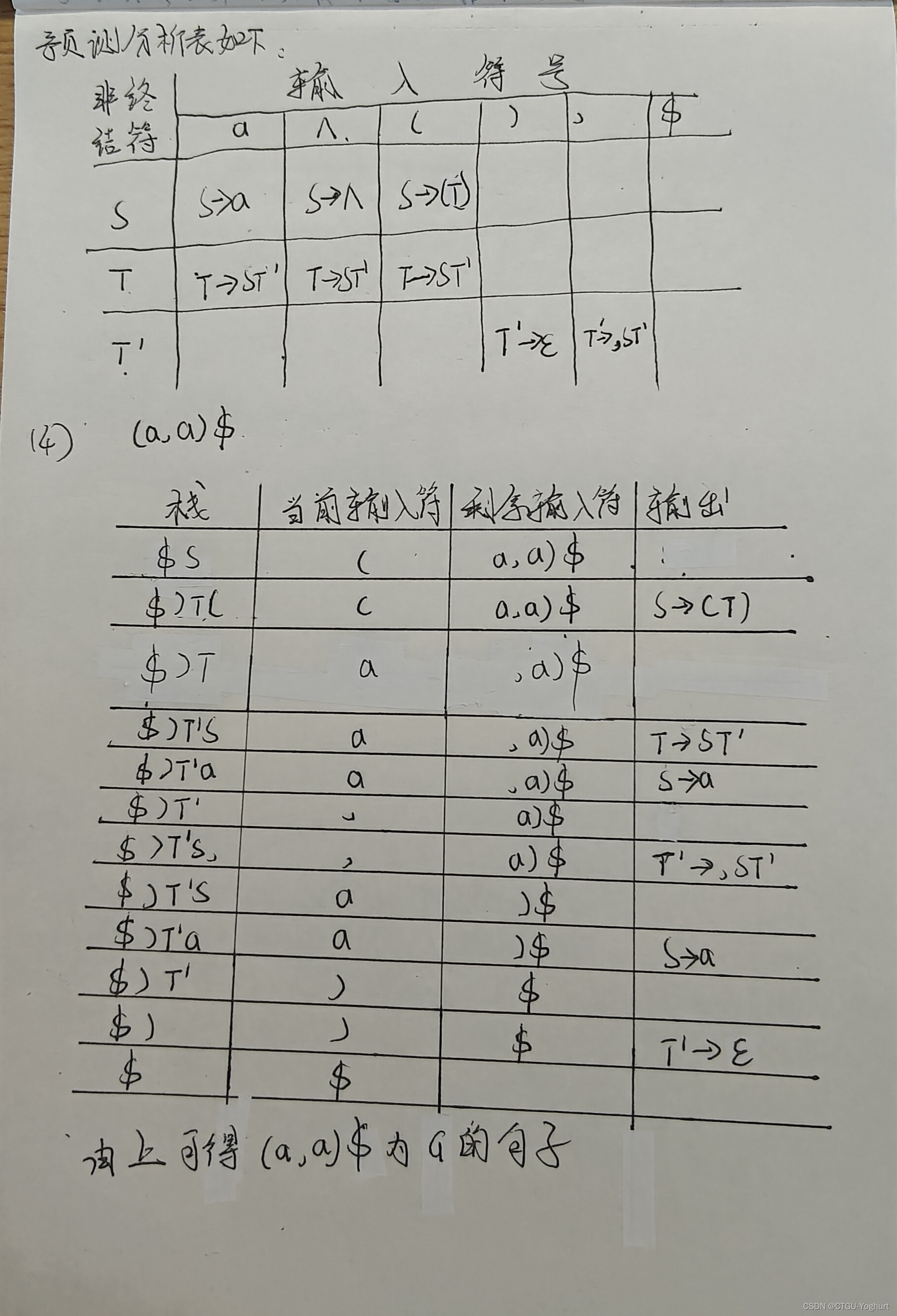
注意:
这里的第2问,笔者书写并不规范,因为当一个文法满足LL(1)条件的时候,我们才能构造一个不带回溯的递归子程序。故在第2问中应先判断改写后的文法G是不是LL(1)型文法,然后再书写不带回溯的递归子程序。
![]()
【20200415】编译原理课程课业打卡十五之求解预测分析表&分析输入串是否为文法句子_对文法g,进行改写,然后对每个非终结符写出不带回溯的递归子程序-CSDN博客

基础知识:
对于LL(1)文法的判断:
 故对于LL(1)文法的判断流程为:先看文法是否存在左递归
故对于LL(1)文法的判断流程为:先看文法是否存在左递归
构建非终结符的FIRST集和FOLLOW集
然后检查各个产生式SELECT集两两不相交

从定义上可以看出SELECT集不存在空集

对于第3点解释:当空串属于a的FIRST集的时候,如果a处于空串这种状态的时候,那么它的FOLLOW集此时也等价于为它的FIRST集。
注意:
关于FIRST集中的空串。简而言之,符号串必须广义推导成一个“纯纯的”空串。此时才将空串放入首符号集中。
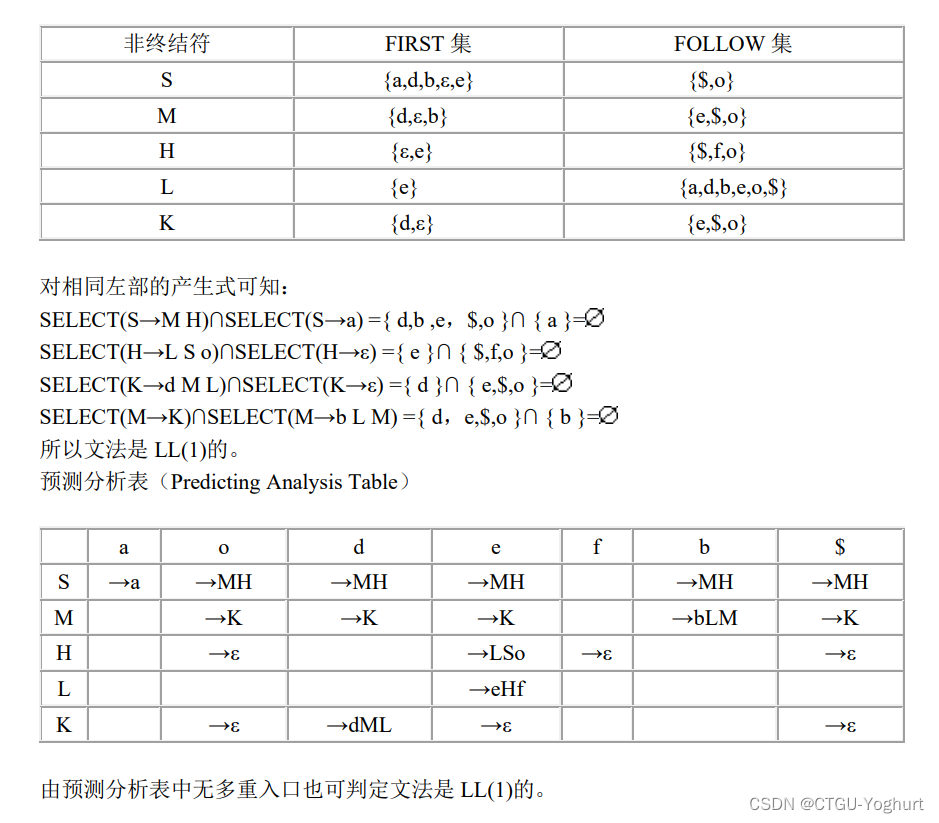
总结:
这节的主要内容为给定文法,对它进行一系列的操作。(以下为粗略的总结,仅仅作为复习,详细细节还需要找到对应定义)
1.对于最左推导:
记住每次都是在保证正确的情况下,从最左边开始匹配即可
2.自上而下分析法:
从文法的开始符号出发,反复使用各种产生式,寻找与输入符号匹配的推导。
3.目前来说,我们改写文法主要有两种手段:
消除直接左递归:为了防止从左边开始进行产生式匹配时出现一直左递归的情况,因为该方式的左边最终一定为一个终结符,故将终结符提前直接表示,重复递归的过程放到右边,方便对于自上而下分析法进行符号匹配(间接左递归:去环即可)
提取左因子:为了防止有多个产生候选式,选择了错误的候选式,导致会出现回溯问题的解决方案。解决方案:反复提取相同的公共左因子,构成新的非终结符,使每个非终结符的所有候选首符号集变成两两不相交
4.FIRST集和FOLLOW集:
FIRST集:
定义:FIRST集为当前非终结符推导出的第一个终结符号所构成的集合,也就是所有的第一个终结符号组合的集合。
构造过程:简单来说就是找第一个终结符,要注意的是对于空串的加入,一定要广义上全部推出为空(即最后推出来的结果,就是一个空集),才能加入。
作用:能够在后面进行预测分析表的时候,直接将表达式写入。简单可以理解为在读取字符进行输入的时候能够通过给定的字符快速的定位到需要用哪一个产生式(即通过第一个非终结符,找到所使用的产生式)。
FOLLOW集:
定义:FOLLOW集为当前非终结符后面的第一个终结符所构成的集合,也就是所有的它后面的第一个终结符的集合。
构造过程:首先需要将终结符放入到开始符号S中(把开始符号S看作一个整体那么该需要读入的字符串就可以看作($S$)),然后依次对于每一个非终结符,将它的第一个终结符放入到集合中。
作用:能够在后面进行预测分析表的时候,直接将表达式写入。简单可以理解为在读取字符进行输入的时候能够通过给定的字符快速的定位到需要用哪一个产生式(即通过第一个非终结符,找到所使用的产生式)。
作用其实和FIRST差不多,但要注意的是在预测分析表中,FOLLOW集只会在FIRST集存在空的时候,才会将FOLLOW集写入(我们可以这样理解:产生式为空,那么我们要根据的第一个字符串定位就等同于FOLLOW集,即该空产生式后面的第一个终结符)
5.SELECT集:
定义:产生式A→α的可选集是指可以选用该产生式进行推导时对应的输入符号的集合,记为SELECT( A→α )
如果 ε not∈ FIRST(α), 那么SELECT(A→α)= FIRST(α) 如果 ε ∈ FIRST(α), 那么SELECT(A→α)=( FIRST(α)-{ε} )∪FOLLOW(A)
作用:可以用于判断文法是否LL(1)文法(即判断下文LL(1)文法的满足条件的2、3条)
判断过程如下:

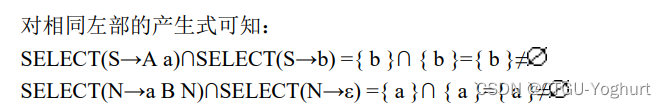
解释:简单来说,SELECT集即为该产生式能够推导产生的第一个终结符的所有集合。 通过SELECT交集的判断,就能判断是否存在相同首终结符的情况,进而判断是否为LL(1)文法
6.LL(1)文法:
LL(1)文字解释:
第一个L表示从左到右去扫描输入串
第二个L表示采用最左推导的方式(这是为什么我们要去掉直接左递归的原因,防止出现一直递推的问题)
1表示分析时,每一步只需要向前看一步即可(这也是为什么我们要提取左因子的原因,让我们能够直接对应表中的值进行推导,其具有唯一对应的关系)
满足条件:
⑴文法不含左递归
⑵文法中每个非终结符A的各个产生式的首终结符集两两不相交,即,若 A→ α1| α 2 |…| α n则 FIRST(αi )∩FIRST(αj )=φ
⑶文法中每个非终结符A若其首字符集中含有ε,则FIRST(αi )∩FOLLOW(A)= φ
7.预测分析表的构建:
对于A->a
首先对产生式右边构造FIRST(a)集,当FIRST(a)集中存在空集的时候,接下来就构造产生式左边非终结符的FOLLOW(A)集,然后根据以上两个集合去在预测分析表中书写对应位置的产生式。
注意这里的为什么要构造FOLLOW(A)集解释一下,当FIRST(a)集广义上都为空的时候,这个时候FOLLOW(A)集就等价于第一个非终结符。(因为我们的分析表就是根据第一个非终结符进行判断)
8.预测分析的过程:
设栈顶符号x和输入符号a
1.当x=a= $ 时,则表示分析成功,停止分析
2.当x=a not= $时,把X从STACK栈顶弹出,a指向下一个输入符号。这里的意思表示a之前指向的字符已经匹配,开始匹配下一个字符。
3.当x为非终结符的时候,查看分析表,找到对应位置的产生式,把x弹出栈顶,把产生式的右部符号,反向进栈(若为空,则不推入东西进栈)。这一步的意思就是通过预测分析表,从当前产生式的起点位置出发,因为当前文法为LL(1)文法,其保证分析时只需要向前看一步,故我们可以采用该方式进行推导。
第5章算符优先分析习题

基础知识:
编译原理------语法分析(二)自下而上的归约(算符优先,LR分析)_待约项目和归约项目-CSDN博客

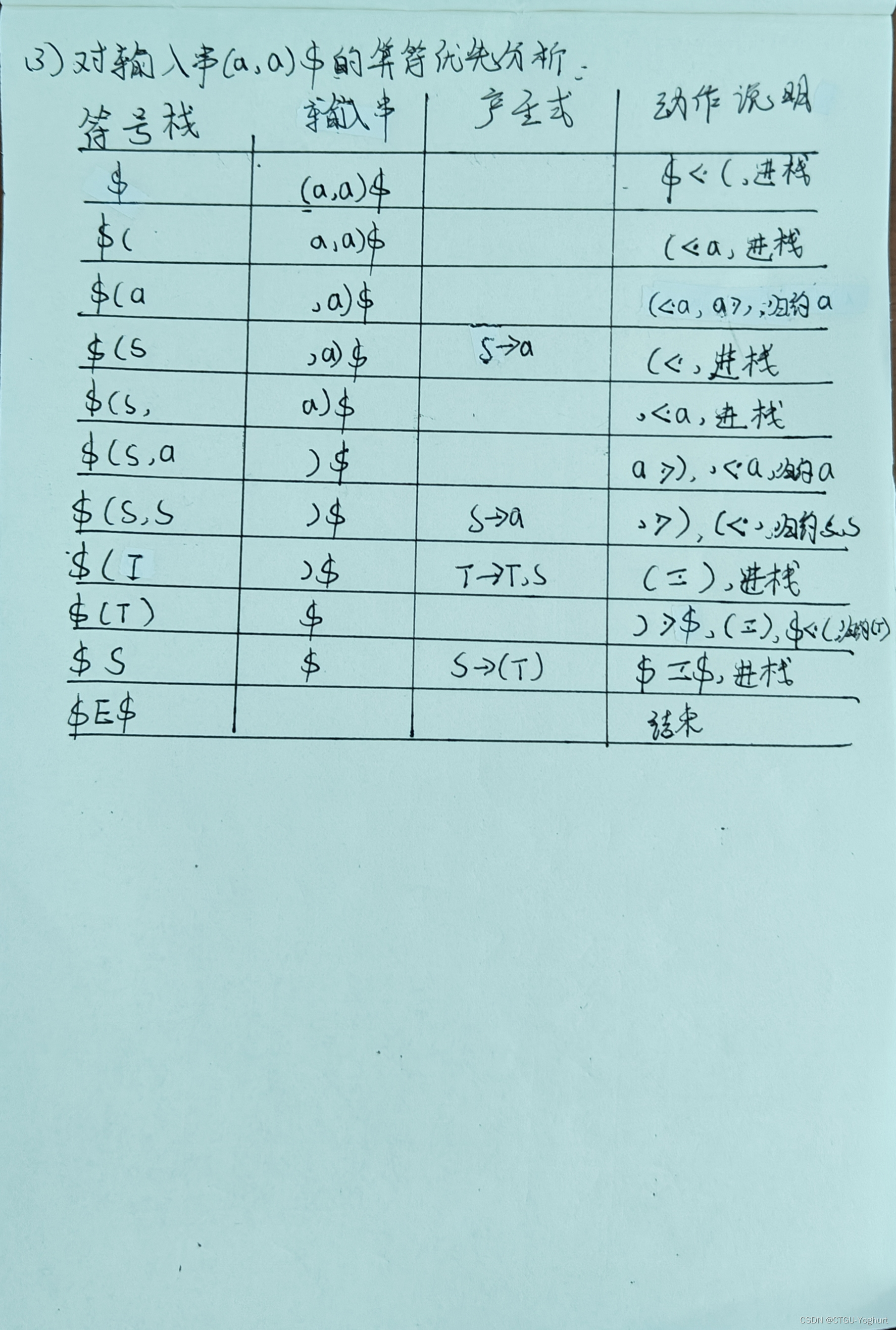
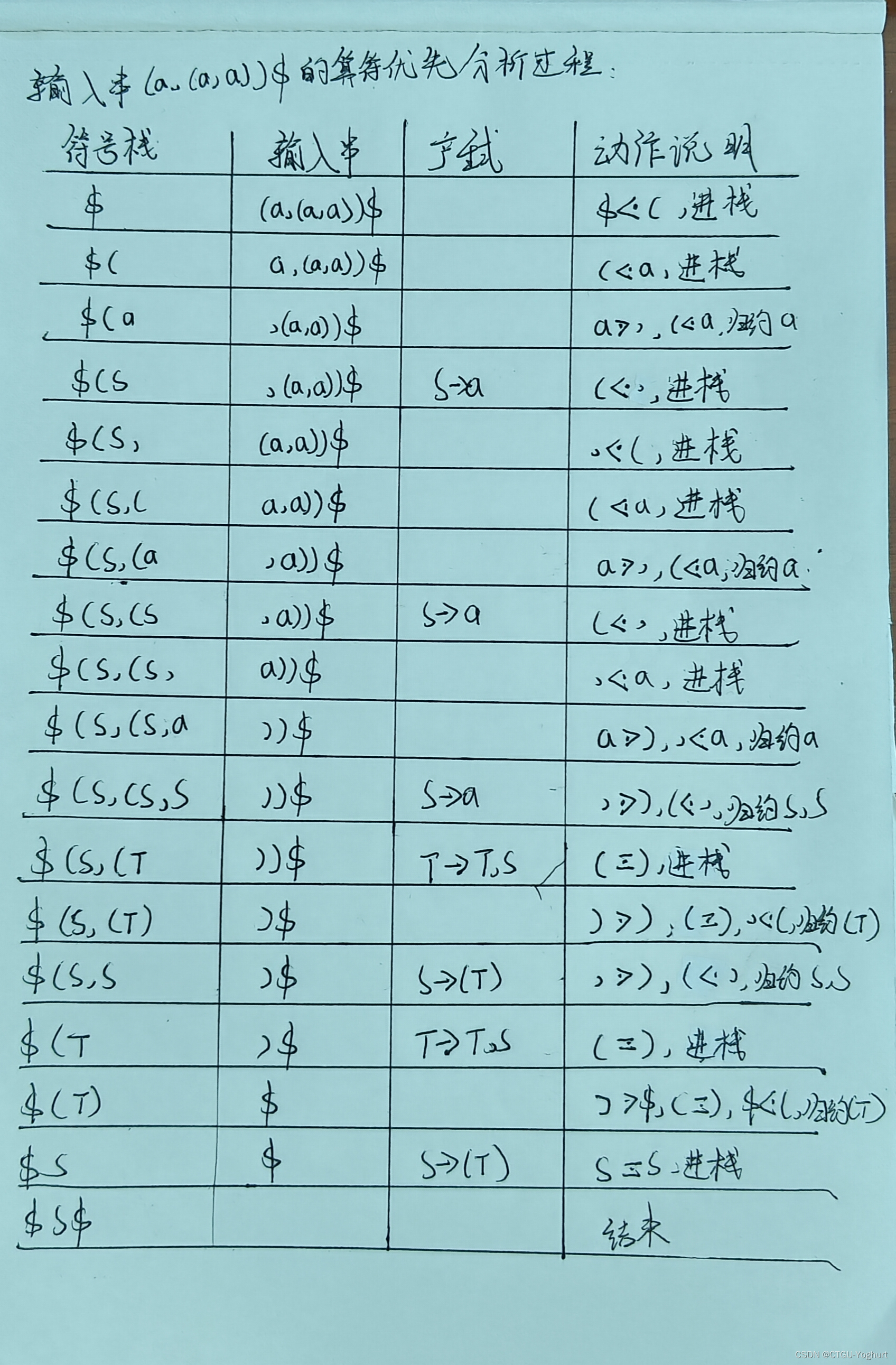
注意:注意算符优先关系表的拓广文法:S'->$S$,可以通过该文法,蒋终结符与$的关系写入算符优先关系表中。


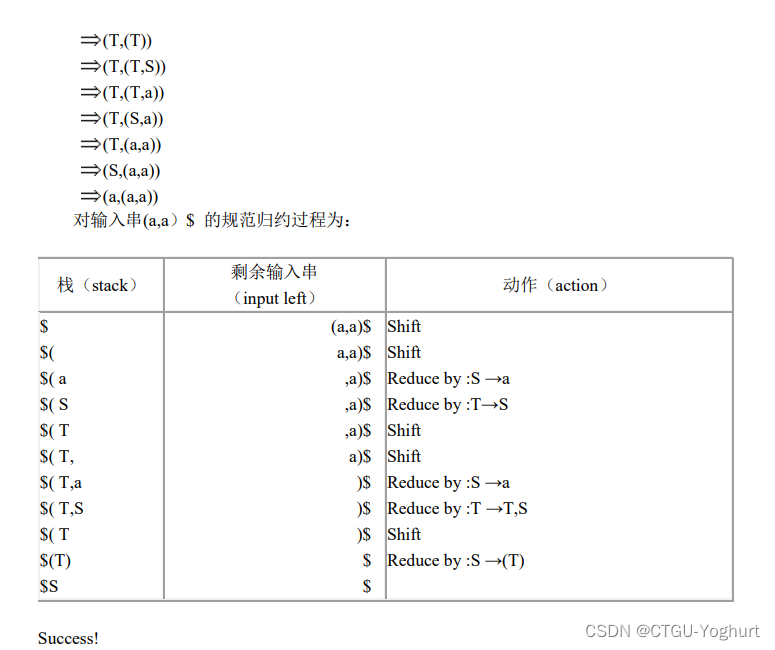


总结:
1.语法分析的方法:

简单来说:
自上而下即从开始符号开始,根据给定的字符串,判断要用什么产生式去推导,然后逐步推导出结果。主要包括递归下降分析法【即通过代码的方式表现出来】和 LL(1)预测分析法【通过消除左递归,消除回溯 计算FIRST、FOLLOW集合,构造预测分析表,然后根据预测分析表对于输入串进行判定】
自下而上是从输入串开始,对字符串进行读入,并根据给定的字符串,判断要用什么产生式去归约,最后逐步规约出结果。主要包括算法优先分析法【计算FIRSTVT和LASTVT集合 构造算符优先关系表,通过最左素短语进行规约】、规范规约【边输入单词符号,边进行规约】、LR分析法
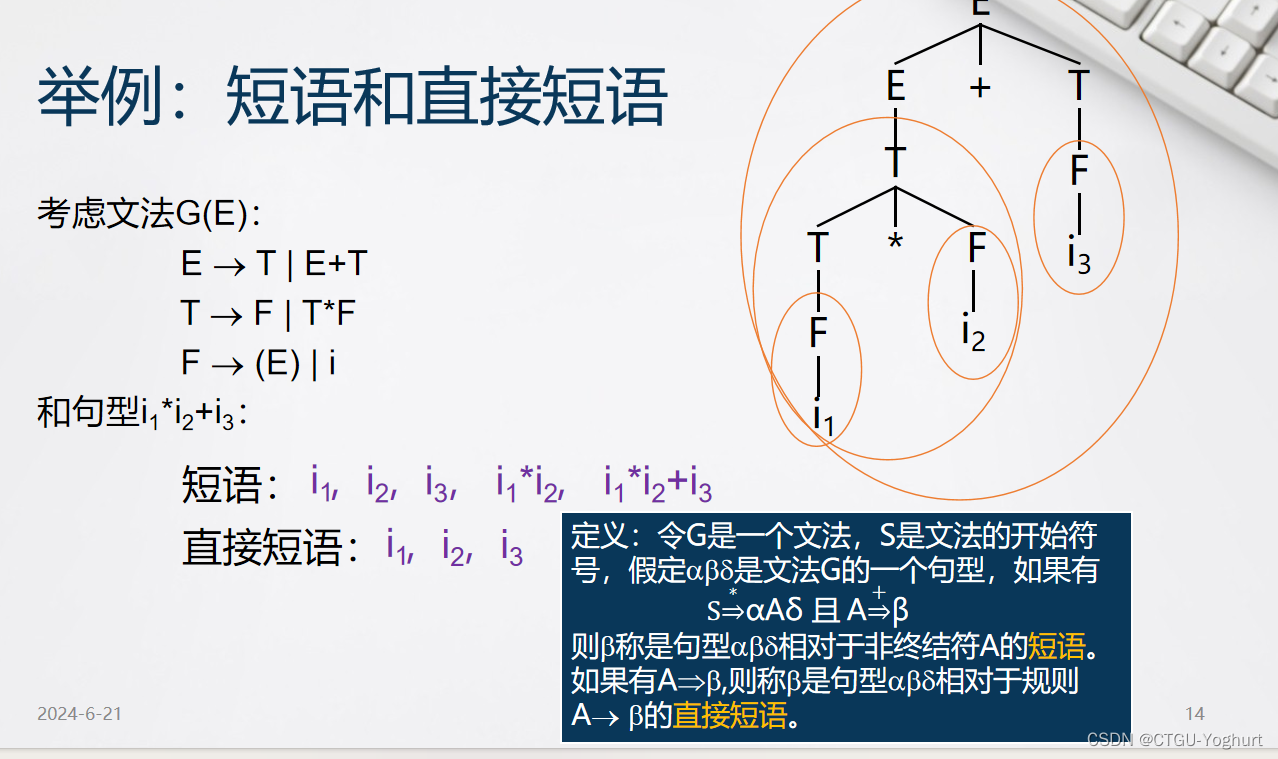
2.短语与直接短语:

3.优先关系:

4.算符文法:

5.算符优先文法:

6.FIRSTVT集与LASTVT集:

简单来说
FIRSTVT集就是 一个终结符的优先级小于 后面所有非终结符 第一层递归 里面的 第一个终结符
LASTVT集就是 一个终结符的优先级大于 前面所有非终结符 第一层递归 里面的 第一个终结符
该两个集合的核心都是 对于在非终结符里面的终结符 大于 与非终结符相邻的终结符,大家可以理解成递归,非终结符就是一个递归程序,我们程序运行的时候肯定是先把最深处递归的内容处理好后,再网上递归,这样就最深处的递归程序里面的内容优先级比上一级的要大。
7.最左素短语:

最左素短语用于算符优先算法进行分析的归约操作。
第6章LR 分析习题(持续更新中)

这篇关于编译原理-各章典型题型+思路求解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









