本文主要是介绍Word2Vec揭秘: 这是深度学习中的一小步,却是NLP中的巨大跨越,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶”
作者:Suvro Banerjee
编译:ronghuaiyang
前戏做NLP现在离不开词向量,词向量给了我们一个非常好的单词的向量表示,用一个有限长度的向量,可以表示出所有的词,还可以表示出词与词之间的上下文相互关系,是不是很神奇?那么,这么神奇的东西到底是怎么来的呢?今天的这篇文章会一点一点给大家说清楚。虽然有一点公式,但是总体上还是非常通俗易懂的,来看看吧。
让我们通过推理,举例和数学来揭秘word2vec

介绍
Word2Vec模型用于学习被称为“词嵌入”的词的向量表示。这通常是作为预处理步骤来完成的,在此之后,学习到的向量被输入判别模型(通常是RNN)来生成预测,完成各种各样有趣的事情。
为什么学习词嵌入Why learn word embeddings
图像和音频处理系统使用丰富的高维数据集,对于图像数据,这些数据编码成为单个像素的强度组成的向量,因此所有信息都编码在数据中,从而可以建立系统中各种实体(猫和狗)之间的关系。
但是,在自然语言处理系统中,传统上它将单词视为离散的原子符号,因此“cat”可以表示为Id537,“dog”表示为Id143。这些编码是任意的,并且不向系统提供关于可能存在于各个符号之间的关系的有用信息。这意味着该模型在处理关于“狗”的数据(比如它们都是动物、四条腿、宠物等等)时,能够利用的关于“猫”的知识非常少。
将单词表示为惟一的、离散的id还会导致数据稀疏,这通常意味着我们可能需要更多的数据才能成功地训练统计模型。使用向量表示可以克服其中一些障碍。
举个例子:
传统的自然语言处理方法涉及到语言学本身的许多领域知识。理解像音素和语素这样的术语是相当标准的,因为有整个语言课程专门用于他们的研究。让我们看看传统的NLP是如何理解以下单词的。
假设我们的目标是收集关于这个词的一些信息(描述它的情感,找到它的定义,等等)。利用我们的语言领域知识,我们可以把这个词分成三个部分。

我们知道前缀un表示相反或相反的意思,我们知道ed可以指定单词的时间段(过去时)。通过识别词干“兴趣”的含义,我们可以很容易地推导出整个词的定义和感情。看起来很简单,对吧?然而,当你考虑英语中所有不同的前缀和后缀时,需要非常熟练的语言学家来理解所有可能的组合和含义。
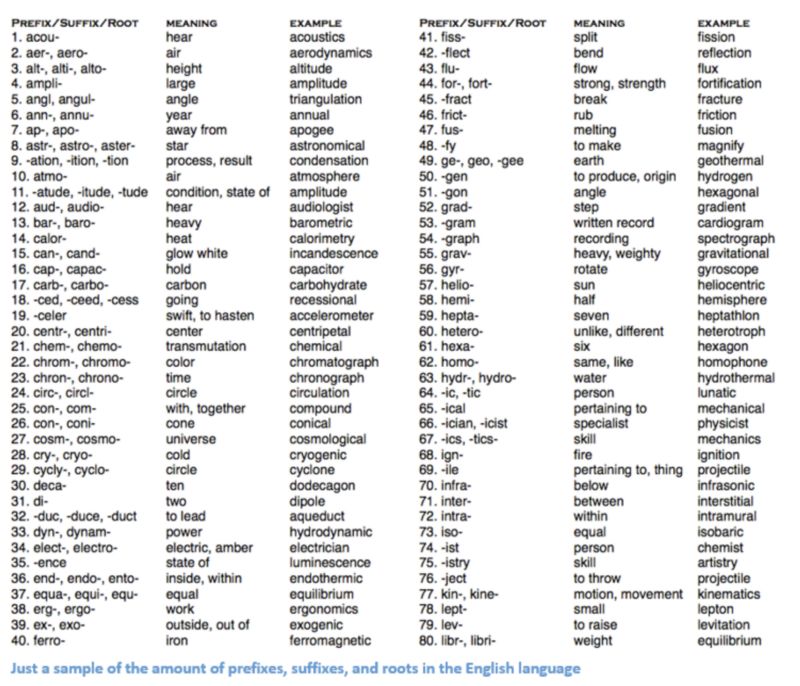
深层学习,在最基本的层面上,是关于表征学习的。在这里,我们将采用相同的方法,通过大型数据集创建单词的表示。
词向量
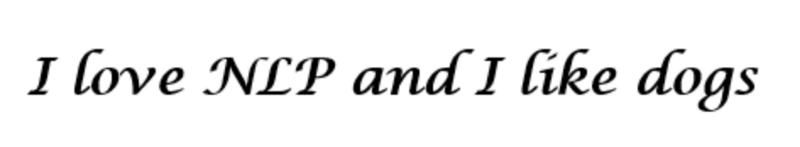
我们将每个单词表示为d维向量。我们用d = 6。从这个句子中,我们想为每个单词创建一个单词向量。

现在我们来考虑如何填充这些值。我们希望以这样一种方式填充值,即向量以某种方式表示单词及其上下文、含义或语义。一种方法是创建一个共现矩阵。
共现矩阵是一个矩阵,它包含出现在语料库(或训练集)中所有其他单词旁边的每个单词的计数。让我们把这个矩阵可视化。
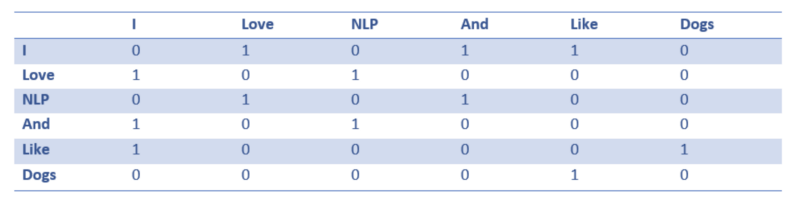

注意,通过这个简单的矩阵,我们可以获得非常有用的见解。例如,请注意,单词“love”和“like”都包含1,表示它们与名词(NLP和dogs)的计数,它们的“I”的计数也是1,这意味着单词必须是某种动词。有了比一个句子更大的数据集,您可以想象这种相似性将变得更加清晰,因为“like”、“love”和其他同义词将开始具有类似的单词向量,因为它们在类似的上下文中使用。
现在,尽管这是一个很好的起点,我们注意到每个单词的维度会随着语料库的大小线性增加。如果我们有一百万个单词(在NLP标准中不是很多),我们就会有一个百万×百万大小的矩阵,这个矩阵非常稀疏(很多0)。在存储效率方面肯定不是最好的。在寻找最优的方法来表示这些词向量方面已经取得了许多进展。其中最著名的是Word2Vec。
过去的方法
向量空间模型(VSMs)在一个连续的向量空间中表示(嵌入)单词,在这个空间中,语义相似的单词映射成的点相互靠近(“彼此嵌入到附近”)。VSMs在NLP中有着悠久而丰富的历史,但所有的方法都或多或少地依赖于分布假设,即出现在相同上下文中的词具有相同的语义。利用这一原则的不同方法可分为两类:
基于计数的方法(如潜在语义分析)
预测方法(如神经概率语言模型)
区别是:
基于计数的方法计算某个单词在大型文本语料库中与相邻单词共出现的频率,然后将这些计数统计信息映射成每个单词的小而密集的向量。
预测模型直接试图通过学习小的、密集的嵌入向量(考虑模型的参数)来预测相邻单词。
Word2vec是一种从原始文本中学习嵌入词的高效预测模型。它有两种风格,连续的词袋模型(CBOW)和跳格模型。从算法上来说,这些模型是相似的,CBOW从源上下文词预测目标词,而skip-gram则相反,从目标词预测源上下文词。
在接下来的讨论中,我们将重点讨论skip-gram模型。
其中的数学
神经概率语言模型使用极大似然原理进行传统的训练,给定前一个单词h(表示“历史”),使用softmax函数表示下一个单词wt(表示“目标”)的概率,并使得整个概率最大化。
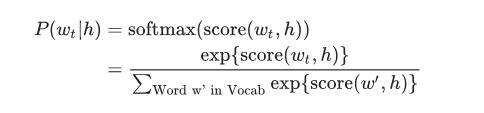
其中score(wt, h)计算目标词wt与上下文h的兼容性(通常使用点积)。
我们通过在训练集中最大化它的对数似然来训练这个模型:
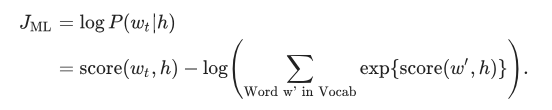
这为语言建模提供了一个适当规范化的概率模型。
同样的参数也可以用一个稍微不同的公式来表示,它清楚地显示了选择变量(或参数),这个变量是为了最大化这个目标而改变的。
我们的目标是找到对预测当前单词周围单词有用的词表示。特别是,我们希望最大化整个语料库的平均对数概率:
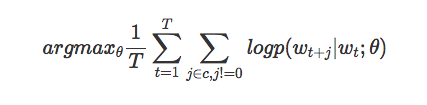
这个方程本质上是说,在当前单词wt上,大小为c 的窗口内,观察某个特定单词的概率p。这个概率取决于当前单词wt和某个参数theta的设置(由我们的模型决定)。我们希望设置这些参数theta,使这个概率在整个语料库中最大化。
基本参数化:Softmax模型
基本的skip-gram模型通过softmax函数定义了概率p,正如我们前面看到的那样。如果我们认为wi是一个独热编码向量,维数是N,theta是维数为N * K的嵌入矩阵在我们的词汇表中有N个单词而我们学出来的嵌入表示的维数是K,那么我们可以定义:
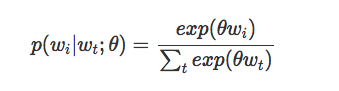
值得注意的是,在学习完了之后,矩阵theta可以被认为是一个嵌入查找表矩阵。
在结构上,它是一个简单的三层神经网络。
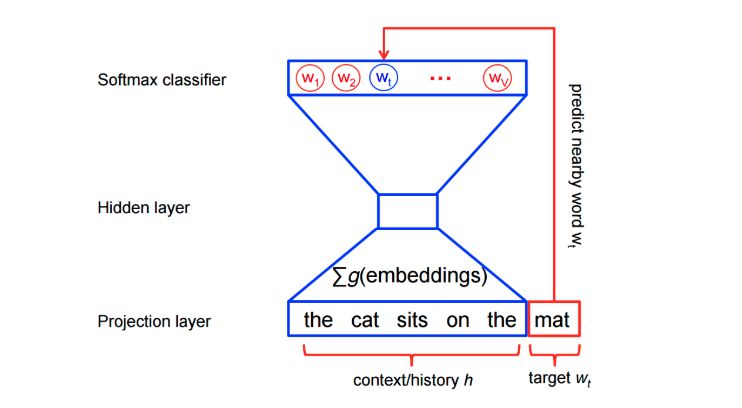
以3层神经网络为例。(1个输入层+ 1个隐藏层+ 1个输出层)
喂它一个词,训练它预测它的邻接词。
删除最后一层(输出层),保留输入层和隐藏层。
现在,从词汇表中输入一个单词。在隐藏层给出的输出是输入词的“词嵌入”。
这种参数化有一个主要缺点,限制了它在非常大的公司的情况下的有用性。具体来说,我们注意到为了计算模型的单个前向传递,我们必须对整个语料库词汇表进行求和,以便计算softmax函数。在大型数据集上,这是非常昂贵的,因此为了计算效率,我们寻求该模型的替代近似。
提高计算效率
对于word2vec中的特征学习,我们不需要一个完整的概率模型。CBOW和skip-gram模型使用二元分类目标(逻辑回归)进行训练,以便在相同的上下文中从k个虚构的(噪声)词~w中区分出真实的目标词(wt)。
从数学上看,目标(对于每个样本)是进行最大化

当模型将高概率赋给真实的词,低概率赋给噪声词时,该目标达到了最大化。从技术上讲,这被称为负采样,它提出的更新在极限上近似于softmax函数的更新。但从计算上来说,它特别有吸引力,因为计算损失函数现在只根据我们选择的(k)噪声词的数量进行缩放,而不是根据词汇表(V)中的所有词进行缩放,这使得训练速度快得多。像Tensorflow这样的包使用了一个非常类似的损失函数,称为噪声对比估计(NCE)损失。
Skip-gram模型中的直觉
作为一个例子,我考虑这样的数据集:
我们首先形成一个词的数据集和它们出现的上下文。现在,让我们继续使用普通的定义,并将“上下文”定义为目标词的左边和右边的单词窗口。使用窗口大小为1,我们就得到了(上下文、目标)对的数据集。
回想一下,skip-gram颠倒了上下文和目标,试图从目标词中预测每个上下文词,因此任务变成了从“quick”中预测“the”和“brown”、从“brown”中预测“quick”和“fox”中预测,等等。
因此,我们的数据集将(输入,输出)对变为:
目标函数是在整个数据集上定义的,但是我们通常使用随机梯度下降(SGD),一次使用一个样本(或batch_size个样本的“批量”,其中通常有16 <= batch_size <= 512)来优化它。我们来看看这个过程的一个步骤。
让我们想象在训练步骤中,我们观察上面的第一个训练案例,目标是从quick中预测the。我们从一些噪声分布中选择num_noise个噪声(对比)样本,通常是unigram分布(unigram假定每个单词的出现独立于所有其他单词的出现。例如,我们可以把生成过程看作是掷骰子的序列),P(w)
为了简单起见,我们假设num_noise=1,并选择sheep作为一个噪声示例。接下来,我们计算这一对观测到样本对以及噪声样本的损失,即目标在时间步' t '变成了:
我们的目标是更新嵌入参数theta,使这个目标函数最大化。我们通过推导关于嵌入参数的损失的梯度来实现这一点。
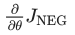
然后,我们在渐变方向上迈出一小步,对嵌入进行更新。当这个过程在整个训练集中重复进行时,就会产生“移动”每个单词的嵌入向量的效果,直到模型成功地从噪声词中识别出真实词为止。
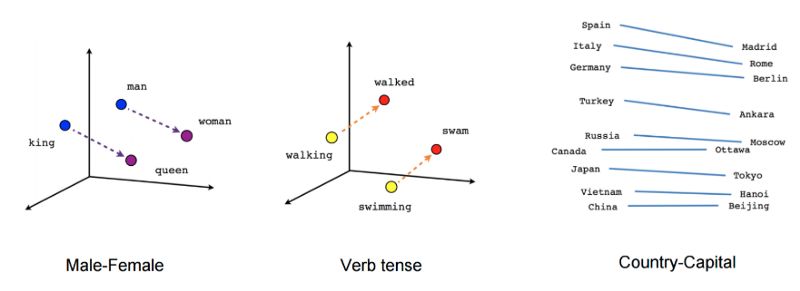
我们可以把学过的向量投影到二维空间来形象化。当我们观察这些可视化时,很明显,这些向量捕获了一些关于单词及其相互关系的一般的、实际上非常有用的语义信息。

往期精彩回顾
1、深度学习物体检测论文阅读路线图以及官方实现
2、一步一步动画图解LSTM和GRU,没有数学,包你看的明白!
3、工欲善其事必先利其器,哪个才是数据科学的最佳Python IDE?
4、动画图解RNN; LSTM 和 GRU,没有比这个更直观的了!
5、重磅资源!PyTorch的福音,用PyTorch 1.0进行教学的免费深度学习课程,来自idiap和瑞士洛桑联邦理工学院
本文可以任意转载,转载时请注明作者及原文地址。

请长按或扫描二维码关注本公众号
来,给我好看吧!![]()
这篇关于Word2Vec揭秘: 这是深度学习中的一小步,却是NLP中的巨大跨越的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





