本文主要是介绍如何快速高效的训练ResNet,各种奇技淫巧(三):正则化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶”
作者:David Page
编译:ronghuaiyang
导读
这个系列介绍了如何在CIFAR10上高效的训练ResNet,到第4篇文章为止,我们使用单个V100的GPU,可以在79s内训练得到94%的准确率。里面有各种各样的trick和相关的解释,非常好。
我们发现了一个性能瓶颈,并增加了正则化,从而将训练时间进一步缩短到154秒。
我们要和8个gpu竞争
在最后一篇文章的结尾,我们在CIFAR10上,在256秒内训练达到了94%的测试准确度。相比之下,最初的基准是341s,而基于单个V100 GPU上100%计算效率的40s目标有些不切实际。今天我们的目标是实现一个中间目标——超越fast.ai的DAWNBench entry。我们将继续使用一个GPU,因为我们离用上所有的 FLOPs还有很长的路要走。
通过选择性地删除部分计算并运行其余部分,我们可以得到当前设置的粗略计时概要。例如,我们可以将随机的训练数据预加载到GPU上,以消除数据加载和传输时间。我们还可以删除优化器优化的步骤、ReLU和batch norm层,只留下卷积。如果我们这样做,我们得到了在一系列batch size上的粗略的时间细分:
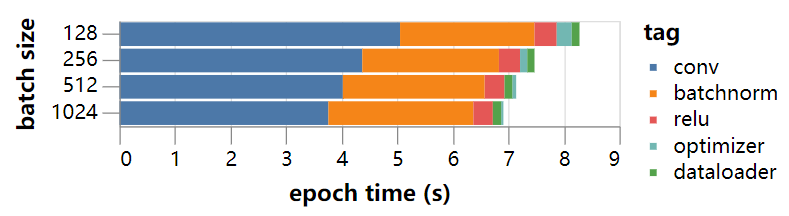
有几件事很突出。首先,大量时间花在batch norm的计算上。其次,主要的卷积骨干网(包括池化层和逐点加法)的计算效率比预计的大约1秒(100%计算效率)要长得多。第三,优化器和dataloader步骤似乎不是一个主要瓶颈,也不是立即进行优化的重点。
在GPU专家Graham Hazel的帮助下,我们看了一些资料,并很快在那里找到了batch norm的问题——PyTorch(版本0.4)中默认的将模型转换为半精度的方法触发了一个缓慢的代码路径,没有使用优化的CuDNN方法。如果我们将batch norm的权重转换回单精度,那么快速代码就会被触发,并且看起来会更好:
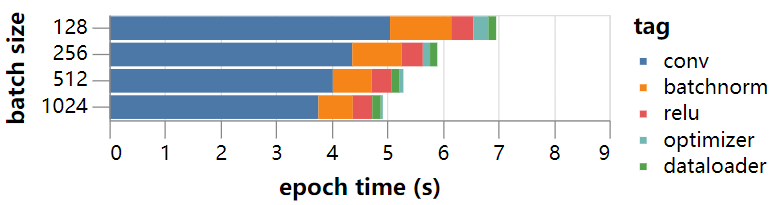
随着这个改进,使用35个epochs的训练到94%的准确率的时间下降到186s,接近我们的目标!
有很多事情我们可以试着越过这条线,把训练降到174s以下。GPU代码的进一步优化是可用的,例如激活数据目前以NCHW格式存储,而TensorCores的快速CuDNN卷积方法希望数据按NHWC顺序存储。正如这里所描述的,向前和向后计算在每个卷积之前和之后执行转置,占整个运行时的很大一部分。由于PyTorch 0.4不支持本机NHWC计算,而且在其他框架中似乎也没有成熟的支持,所以我们暂时不讨论这个问题,可能会在稍后的文章中重新讨论。
将训练时间缩短到30个epochs,就可以完成161秒的训练,轻松地超过我们目前的目标,但简单加速基线的学习率策略,0/5的训练达到94%的准确率。
一个简单的正则化方案在CIFAR10上已经被证明是有效的,它被称为Cutout正则化,它包括将每个训练图像的随机子集归零。除了填充、剪切和随机左右翻转等标准数据增强之外,我们还对训练图像的随机8×8平方子集进行了尝试了这种方法。
基线35个epoch训练计划的结果是有前途的,5/5次跑达到94%的准确率,中位数跑达到94.3%,比基线略有改善。稍微手动优化学习率策略(将峰值学习率提前,用简单的线性衰减代替阶段衰减,因为过拟合的最后阶段似乎对额外的正则化没有帮助)可以使中值运行到94.5%。
如果我们对学习率策略加速,加快到30个epoch, 4/5次运行达到94%,中间值为94.13%。我们可以将batch size大小提高到768,4/5达到94%,中间值为94.06%。epoch运行30次的时间是batch size为512的161秒和batch size为768的154秒,轻松地超过了我们的目标,并为训练CIFAR10到94%测试准确度的任务设置了一个新的速度记录,所有这些都在一个GPU上!为供参考,新的30个epochs的学习率策略表如下图所示。其他超参数(动量=0.9,重量衰减=5e-4)保持在初始训练设置的值。
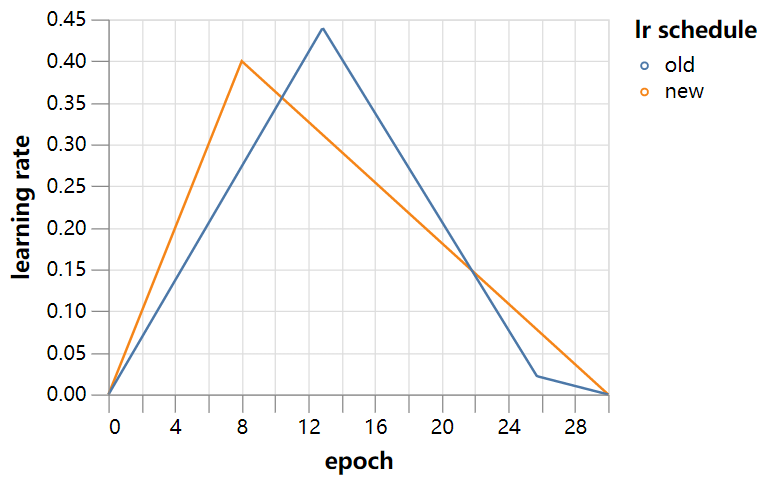
已经完成了我们在文章开头设定的目标,是时候结束今天的工作了。这些计时的代码可以在这里找到:https://github.com/davidcpage/cifar10-fast/blob/master/ents.ipynb。我们的新记录,尽管如此,应该很容易改进。首先,我们在一个GPU上仍然保持低于25%的计算效率,有已知的优化可以改善这一点。其次,应该可以使用Mixup规范化和AdamW训练等技术来减少训练周期的数量。我们还没有探索参数平均来加速最终的收敛,如果我们准备在推理时间上做更多的工作,就有可能使用测试时间增加来进一步减少训练时间。有传言说可以用少于20个epochs的训练运行,这些技术的组合尽管是为更大的网络用的,对这些途径进一步的探索会非常有趣。
然而,我们将暂时不探讨这些途径,而是看看我们迄今为止一直在使用的网络体系结构。我们将发现,这是一个用于优化的异常丰富的地方。
在第4部分中,我们简化了网络体系结构,让训练变得更快。

—END—
英文原文:https://myrtle.ai/how-to-train-your-resnet-3-regularisation/

请长按或扫描二维码关注本公众号
喜欢的话,请给我个好看吧!![]()
这篇关于如何快速高效的训练ResNet,各种奇技淫巧(三):正则化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



