本文主要是介绍细说MVC中仓储模式的应用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
概述要点
设计模式的产生,就是在对开发过程进行不断的抽象。
我们先看一下之前访问数据的典型过程。
在Controller中定义一个Context, 例如:
private AccountContext db = new AccountContext();
在Action中访问,例如获取用户列表:
var users=db.SysUsers;
类似于这种,耦合性太高。业务逻辑直接访问数据存储层会导致一些问题,如
重复代码;不容易集中使用数据相关策略,例如缓存;后续维护,修改增加新功能不方便 等等。
我们使用repository来将业务层和数据实体层分开来,业务逻辑层应该对组成数据源层的数据类型不可知,比如数据源可能是数据库或者Web service
在数据源层和业务层之间增加一个repository层进行协调,有如下作用:
1.从数据源中查询数据
2.映射数据到业务实体
3.将业务实体数据的修改保存到数据源 (持久化数据)
这样repository就将业务逻辑和基础数据源的交互进行了分隔。
数据和业务层的分离有如下三个优点:
1.集中管理不同的底层数据源逻辑。
2.给单元测试提供分离点。
3.提供弹性架构,整体设计可以适应程序的不断进化。
我们将会对原有做法进行两轮抽象,实现我们想要的效果。
理论基础
仓储和工作单元模式是用来在数据访问层和业务逻辑层之间创建一个抽象层。
应用这些模式,可以帮助用来隔离你的程序在数据存储变化。
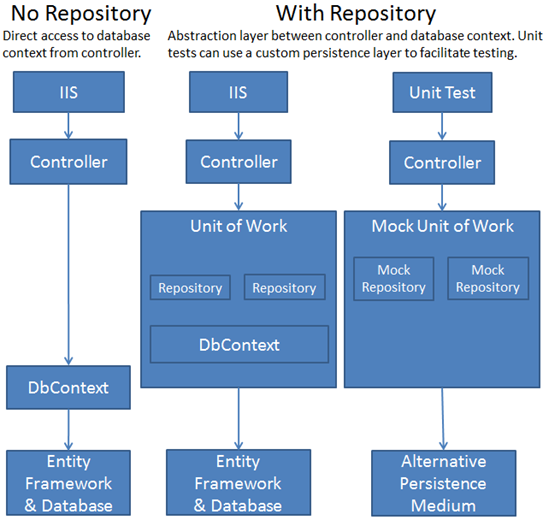
下图比较了不使用库模式和使用库模式时controller和context 交互方式的差异。
说明:库模式的实现有多种做法,下图是其中一种。
准备工作
首先我们先搭建好空的框架,准备基本的结构和一些测试数据。
我们不再在第一阶段的MVCDemo上进行更改了, 重新建立一个新项目XEngine作为我们第二阶段的演示项目 。
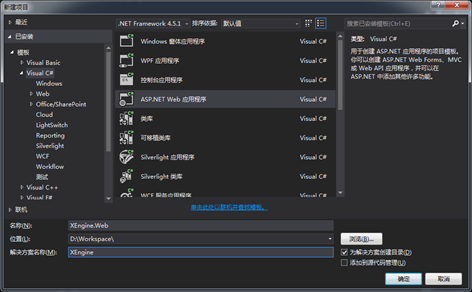
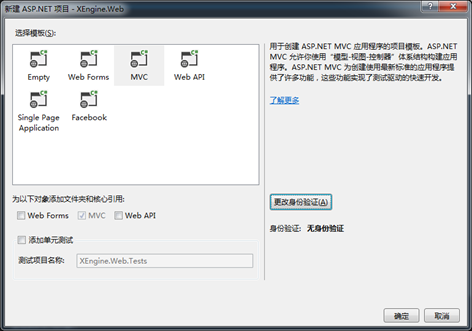
1.新建项目
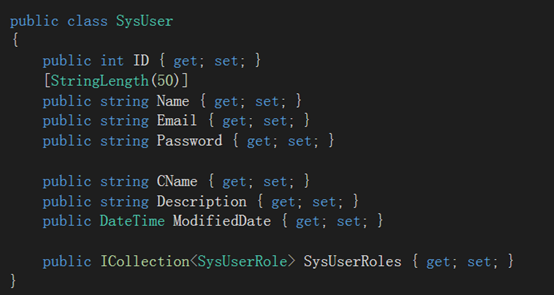
2.新建Model
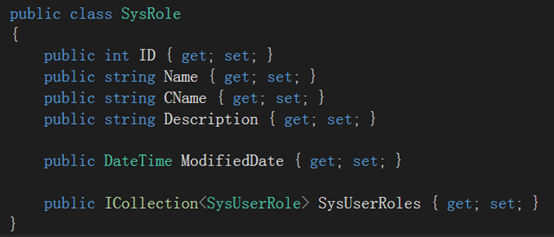
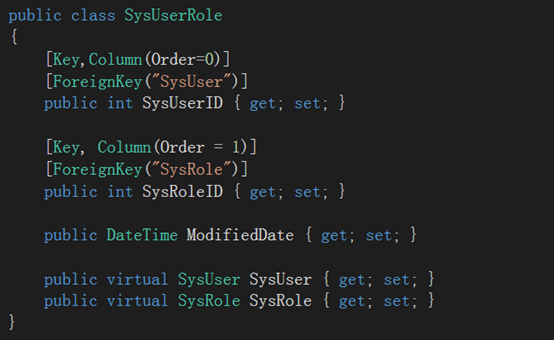
我们新建 SysUser, SysRole , SysUserRole
3. 安装EF, 准备测试数据
a.安装EF
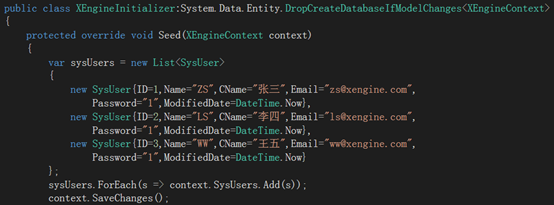
b.新建文件夹DAL
à 新建类 XEngineContext.cs
à 新建类 XEngineInitializer.cs


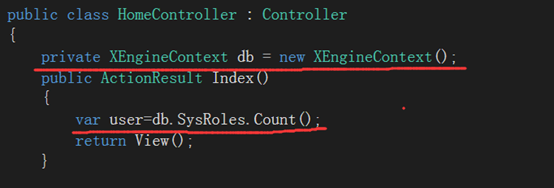
c.修改HomeController.cs,运行Index视图,来生成数据库结构和测试数据。
说明:准备工作有不清楚的请参考这篇文章:
https://blog.csdn.net/u011966339/article/details/90725613
至此,准备工作已经OK,下面就看看如何运用仓储模式来改造我们的项目。
详细步骤
整个过程分成两轮抽象。
第一轮抽象 : 解耦Controller和数据层
对每一个实体类型建立一个对应的仓储类。
以SysUser来说,新建一个仓储接口和仓储类。
在controller中通过类似于下面这种方式使用:
ISysUserRepository sysUserRepository = new SysUserRepository();
下面来看创建 SysUser 仓储类具体做法:
1.新建个文件夹 Repositories, 后面新建的仓储类都放在这个文件夹中
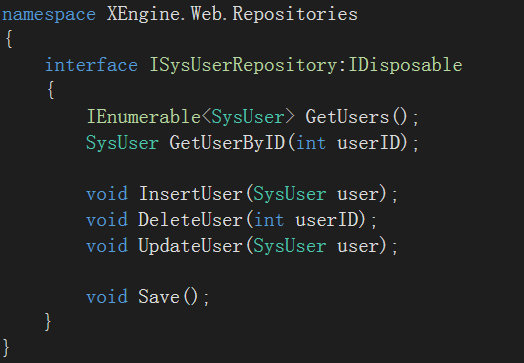
2.创建接口 ISysUserRepository
接口中声明了一组典型的CRUD方法。
其中查找方法有两个:返回全部和根据ID返回单个。
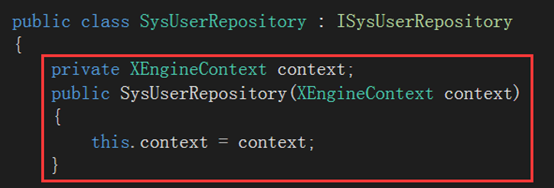
3.创建对应的仓储类 SysUserRepository
创建类 SysUserRepository, 实现接口 ISysUserRepository
a. 把接口中的方法全部实现


b.关闭连接

说明:
GC.SuppressFinalize(this);
因为对象会被Dispose释放,所以需要调用GC.SuppressFinalize来让对象脱离终止队列,防止对象终止被执行两次。
4.Controller中使用SysUser仓储类
我们新建个Controller : UserController
用 List 模板生成视图。

修改Controller如下:

运行Index就可以看到用户列表了。
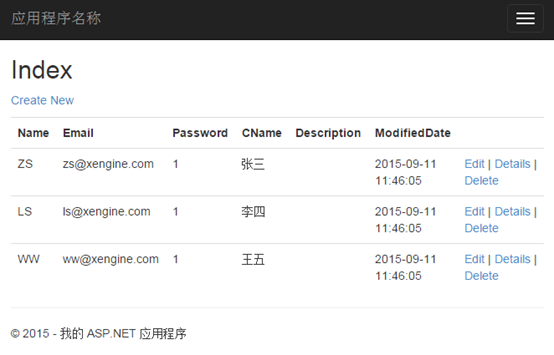
更新和删除就不再举例了,都比较简单,大家可以自己去试验,方法类似。
至此,第一次抽象就完成了。
可以看到,我们增加了一个抽象层,将数据连接的部分移到Repository中去,这样实现了Controller和数据层的解耦。
观察一下可以发现,还存在两个问题:
1.如果一个controller中用到多个repositories,每个都会产生一个单独的context
2.每个entity type 都要实现一个对应的repository class ,这样会产生代码冗余。
下面我们就再进行一次抽象,解决这两个问题。
说明:
为方便讲述,实体类型 和 仓储类 以下直接用 entity type 和 repository class表示。
第二轮抽象:通过泛型消除冗余的repository class
为每个 entity type 创建一个repository class 会
a. 产生很多冗余代码
b. 会导致不一致地更新
举例:
你要在一个 transaction中更新两个不同的 entity type
如果使用不同的context instance, 一个可能成功,另外一个可能失败。
我们使用 generic repository去除冗余代码
使用unit of work保证所有repositories使用同一个 context
说明:
后面将会新建一个unit of work class 用来协调多个repositories工作, 通过创建单一的context让大家共享。
一、首先解决代码冗余的问题。
我们对ISysUserRepository和SysUserRepository 再进行一次抽象,去除repository class的冗余。
仿照ISysUserRepository和SysUserRepository,新建IGenericRepository和GenericRepository
步骤和前面类似:
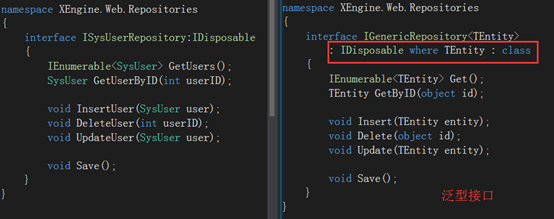
1. 创建泛型接口 IGenericRepository
下图中右边为IGenericRepository, 大家观察下两者的区别
2.创建对应的泛型仓储类 GenericRepository


下面折叠起来的部分没有任何变化。
3.修改UserController
把原来的注释掉,给泛型类指定SysUser,主要更改部分如红线表示。前端不用做任何更改。
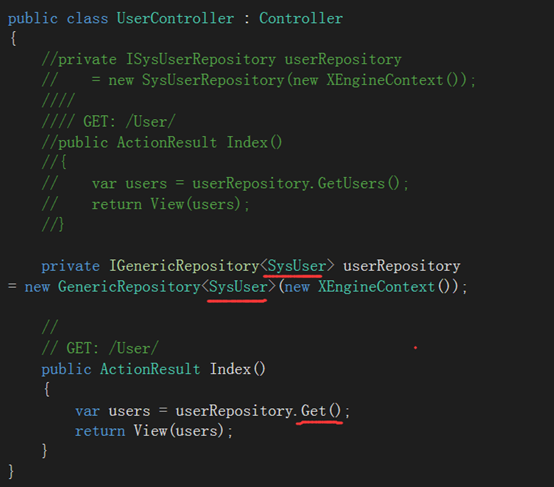
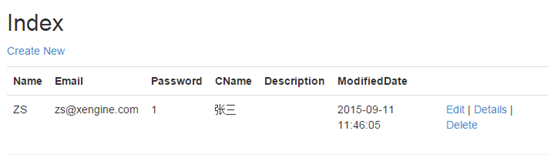
运行Index就可以看到和之前一样的结果了。
大家可以看到,通过泛型类已经消除了冗余。
如果有其他实体只需要改变传入的TEntity就可以了,不需要再重新创建repository class
二、接下来解决第二个问题:context的一致性。
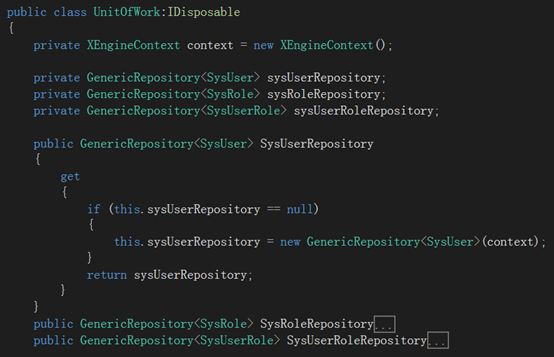
我们在DAL文件夹中新建一个类UnitOfWork用来负责context的一致性:
当使用多个repositories时,共享同一个context
我们把使用多个repositories的一系列操作称为一个 unit of work
当一个unit of work完成时,我们调用context的SaveChanges方法来完成实际的更改。由于是同一个context, 所有相关的操作将会被协调好。
这个类只需要一个Save方法和一组repository属性。
每个repository属性返回一个repository实例,所有这些实例都会共享同样的context.
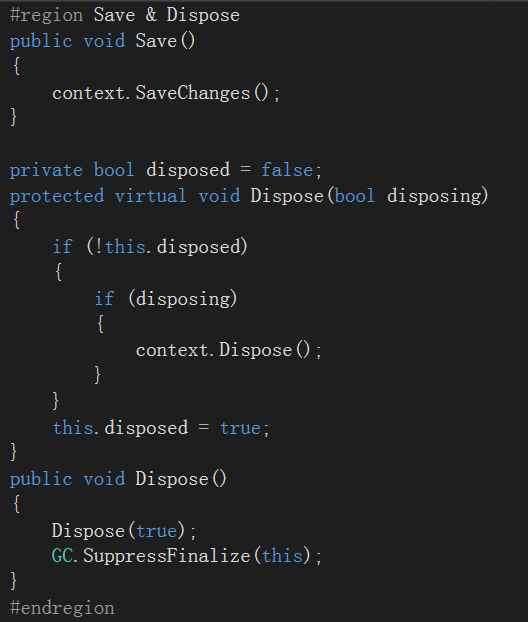
把 GenericRepository.cs 中的Save 和 Dispose 删除, 移到UnitOfWork中。
将IGenericRepository 中的IDisposable接口继承也去掉.
Save & Dispose 的工作统一在UnitOfWork中完成。
在UserController中使用UnitOfWork, 修改如下:
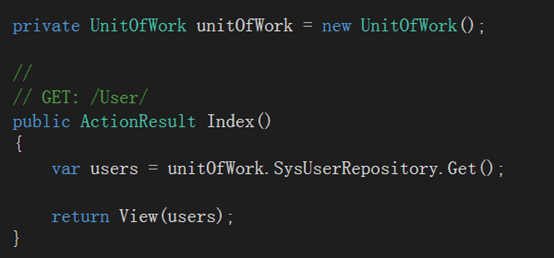
前端同样不用做任何更改,运行Index就可以看到和之前一样的结果了。

三、And one more thing
前面已经将代码冗余和context不一致的问题全都解决了。
不过还有个问题。
大家看我们的查询方法:
IEnumerable<TEntity> Get();
TEntity GetByID(object id);
上面的方法一个是返回所有结果,一个是根据id返回单笔记录。
在实际应用中,有个问题肯定会遇到:
需要根据各种条件进行查询。
比如 查询用户, 要实现类似 GetUsersByName 或者 GetUsersByDescription 等等。
解决这个问题常用的一种做法是:
创建一个继承类,针对特定的entity type 添加 特定的Get方法,比如前面说的 GetUsersByName.
这样做有一个缺点,会产生冗余代码。特别是在一个复杂程序中,可能会产生大量的继承类和特定的方法,维护起来又需要花费很多工作。我们不用这种做法。
我们使用表达式参数的方法。
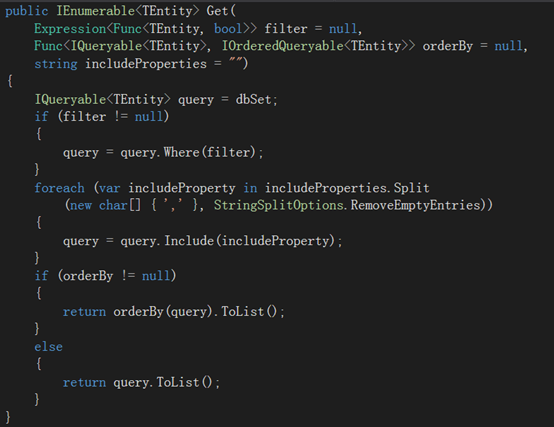
改造一下Get方法。
先分析一下需求,常用的有三点:
1. 过滤条件
2. 排序
3. 需要Eager loading 的相关数据
针对这三点,我们给Get加入三个可选参数

再来看下GenericRepository 中的实现
最后修改下Index方法做测试:
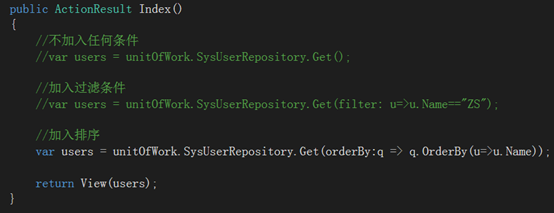
a. 不加入任何条件

b. 加入过滤条件,选出张三
c. 按姓名排序
好了,到目前为止,应该接近完美了,数据层的问题应该可以解决一半了。
总结
本篇是MVC系列文章,第二阶段专题篇的第一篇。
首先将Controller和Context之间抽象出一层来专门负责数据访问。
然后进行第二次抽象,将共有的方法进行泛化,提取出一个GenericRepository出来,将每个具体的类型放到UnitOfWork中进行统一处理。
最后改造了查询方法,通过传入表达式可以根据条件灵活返回查询结果。
需要说明的是,EF本身的设计其实就是repository+unit of work , 如果是简单应用直接用原来的做法就可以了。
另外MVC中仓储模式的实现也有多种做法,本文介绍的微软官方文档提供的做法,个人觉得是比原生的做法更方便灵活,也更容易扩展。
这篇关于细说MVC中仓储模式的应用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





