本文主要是介绍[Mysql] 的基础知识和sql 语句.教你速成(上)——逻辑清晰,涵盖完整,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
前言
上篇的内容概况
下篇的内容概况
数据库的分类
关系型数据库
常见的关系型数据库系统
非关系型数据库
1. 键值对数据库(Key-Value Stores)
特点:
常见的键值对数据库:
2. 文档数据库(Document Stores)
特点:
常见的文档数据库:
3. 列族数据库(Column-Family Stores)
特点:
常见的列族数据库:
4. 图数据库(Graph Databases)
特点:
常见的图数据库:
Mysql 常见的数据类型
数值类型
字符串类型
日期类型
sql 语句
首先是数据库的操作
建立数据库
展示数据库
删除数据库
使用数据库
基础的表的操作
展示所有表
建立表
查看表的结构
删除表
修改表
表的增删查改
新增数据
查询数据(****)
全列查询
指定列查询
查询[字段为表达式]的查询
别名(as)
去重(distinct)
排序 (order by)
条件查询(where)
比较运算符
逻辑运算符
分页查询
查询语句的书写和执行顺序(****)
修改数据(update)
删除(delet)
上篇总结
前言
OK,笔者知道笔者这篇博客写完的时候,很多人已经考完数据库了,但是笔者还是要写,因为笔者还没考完捏
Mysql 作为一个开源的,易于安装和配置的,有着图形化工具的关系型数据库管理系统软件, 非常适合我们入门数据库,所以笔者会介绍Mysql 的基础知识和 sql 语句
上篇的内容概况
数据库的分类, Mysql的数据类型,基础的sql 语句
包括数据库的操作,表的操作 ,基础的 CRUD管理和组织表的数据
下篇的内容概况
数据库的约数,聚合查询,联合查询
索引,事物,Mysql 的 JDBC 编程
不想看前面的废话直接目录空降即可
数据库的分类
数据库分 关系型数据库 和 非关系型数据库 而我们的Mysql 就是前者
关系型数据库
所谓 关系型数据库 ,就是通过 我们说的 "表" 来 组织数据的,每个表都有自己的"行" 和 "列"
然后通过 sql 语句 来进行管理和操作,我们一般期末考试也就是考 sql 语句和画ER 图
(个人观点别骂我)不过有一说一,画ER 图是真没什么屁用,软件工程的项目需求几乎不需要成本去改,一天一个样,你画图纸除了骗骗未来啥都不知道的甲方和领导,真的有tm 一点用吗??????
常见的关系型数据库系统
- PostgreSQL
- Oracle Database
- Microsoft SQL Server
- SQLite
非关系型数据库
这个笔者没有学习过,不太了解, 大致理解是通过键值对和文档来组织数据,所以下面内容来自网络
1. 键值对数据库(Key-Value Stores)
键值对数据库使用简单的键值对存储数据,类似于字典或哈希表。每个键唯一标识一个值,这种模型非常适合快速查找和大规模分布式存储。
特点:
- 数据通过键来访问,操作非常快速。
- 适用于缓存、会话存储和简单数据存储等场景。
- 灵活性高,但不适合复杂查询。
常见的键值对数据库:
- Redis
- Amazon DynamoDB
- Riak
2. 文档数据库(Document Stores)
文档数据库使用文档来存储数据,通常以 JSON、BSON 或 XML 格式表示。文档可以包含复杂数据结构,包括嵌套的文档和数组。
特点:
- 数据结构灵活,适用于半结构化和非结构化数据。
- 支持丰富的查询和索引功能。
- 常用于内容管理系统、用户数据存储等场景。
常见的文档数据库:
- MongoDB
- CouchDB
- Amazon DocumentDB
3. 列族数据库(Column-Family Stores)
列族数据库使用列族(column families)来组织数据,类似于关系型数据库的表,但列族中的列是动态的,可以根据需要添加。数据以列为中心进行存储和查询。
特点:
- 高效地存储和查询大规模数据。
- 适用于数据分析、时间序列数据和大数据应用。
常见的列族数据库:
- Apache Cassandra
- HBase
- ScyllaDB
4. 图数据库(Graph Databases)
图数据库使用图结构来存储数据,节点表示实体,边表示实体之间的关系。这种模型非常适合处理复杂的关系和连接查询。
特点:
- 自然地表示和查询复杂关系。
- 适用于社交网络、推荐系统和网络分析等场景。
常见的图数据库:
- Neo4j
- Amazon Neptune
- JanusGraph
Mysql 常见的数据类型
常见的 数据类型就是 数值类型, 字符串类型,还有日期类型;
数值类型
|
笔者练习的时候 常用 int,declmai,double 其他都是在书上看了几眼
字符串类型
| 数据类型 | 描述 |
|---|---|
| char(m) | 固定长度字符串,最多 255 个字符 |
| varchar(m) | 可变长度字符串,最多 65535 个字符 |
| tinytext | 非常小的文本字符串,最多 255 个字符 |
| text |
如上,基本都是笔者从书上汇总来的
日期类型
| date | 日期值,格式:yyyy-mm-dd |
| datetime | 日期和时间值,格式:yyyy-mm-dd hh:mm |
| timestamp | 时间戳,格式:yyyy-mm-dd hh:mm,自动更新 |
有时候可以配合 now() 函数使用就是了
sql 语句
好的,终于来到了sql 语句速成 这一块了 基本思路就是 CRUD
首先是数据库的操作
建立数据库
create database (if not exists) 数据库的名字 charset utf8;记得手动指定编码方式为 utf8,不然无法使用中文
展示数据库
show databases;删除数据库
drop database if exists 数据库名字;使用数据库
use 数据库的名字管理表之前要使用数据库
基础的表的操作
展示所有表
show tables;建立表
create table 表的名字(你自己觉得) (id int,name varchar(20));在表的名字后面 打括号,写上你想要的 列名 数据类型,用逗号分隔,我这里随便举了个例子给你看看
查看表的结构
desc 表名
效果如图,会显示表的结构
删除表
drop table 表的名字修改表
alter table这个有点多,不好举例
表的增删查改
以下操作大概就是重点了, CRUD!!!
新增数据
insert into 表名 (指定列,如果不写就是默认所有列) values (插入数据,要符合每一列的数据类型)例如
insert into student values(1,'张三');可以一次性插入很多数据
insert into student values(1,'张三'),(2,'李四').(3,'王五');查询数据(****)
通过查询操作,我们将穿插一些子句语法
全列查询
顾名思义,可以查询表中的所有列和行
select * from 表名我的老师告诉我,这个在实际生产中要慎用,如果数据库存在大量数据,容易占用资源造成损失,当然了我们平时自己的数据库那是随便用了.
*号代表所有
指定列查询
为了放置我上述的情况产生,我们要指定列去查询
select (列名,用逗号隔开) from 表名查询[字段为表达式]的查询
请看图
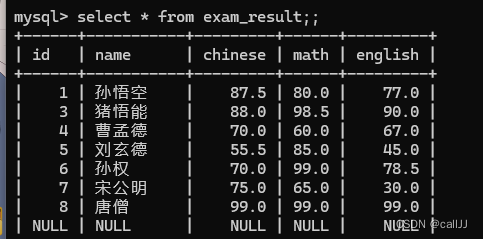
这是一个样例, 我可以查询 三科成绩之和(这就是一个表达式)
select id,name,chinese+math+english from exam_result;
效果如上图,可以得到表达式结果
别名(as)
我们可以给三科之和去一个别名
语法如下
select id,name,chinese+math+english as total from exam_result;效果如下

在需要的列后面 + as 新名字,as 可以省略,但推荐加上去
去重(distinct)
如果有重复的数据,可以通过如下语法去重
select DISTINCT (指定列) from 表名
太简单了就不举例演示了
排序 (order by)
记住这两个要点
语法如下,以上面的exam_result 表为例子 查询姓名和数学成绩,并且排序
select id,math from exam_result order by math desc;order by (指定列) desc/asc;
-- ASC 为升序(从小到大)
-- DESC 为降序(从大到小)
-- 默认为 ASC效果如图

如果没有指定 是升序还是降序,默认升序

可以配合别名使用,比如把三科成绩排序
select id,name,chinese+math+english as total from exam_result order by total desc;
条件查询(where)
在讲解之前,必须知道 逻辑运算符和比较运算符
因为在 MySQL 中,where 子句用于指定选择查询中的条件,以过滤符合特定条件的记录。逻辑运算符和比较运算符用于在 where 子句中构建条件表达式。
比较运算符
= | 等于 | column = value |
<> | 不等于 | column <> value |
!= | 不等于(同 <>) | column != value |
> | 大于 | column > value |
< | 小于 | column < value |
>= | 大于等于 | column >= value |
<= | 小于等于 | column <= value |
BETWEEN | 在范围内 | column BETWEEN value1 AND value2 |
NOT BETWEEN | 不在范围内 | column NOT BETWEEN value1 AND value2 |
IN | 在集合中 | column IN (value1, value2, ...) |
NOT IN | 不在集合中 | column NOT IN (value1, value2, ...) |
LIKE | 模糊匹配 | column LIKE pattern |
NOT LIKE | 不模糊匹配 | column NOT LIKE pattern |
IS NULL | 是空值 | column IS NULL |
IS NOT NULL | 不是空值 | column IS NOT NULL |
逻辑运算符
AND | 逻辑与 | condition1 AND condition2 |
OR | 逻辑或 | condition1 OR condition2 |
NOT | 逻辑非 | NOT condition |
我给标红的运算符举例,其他的大伙应该也会不用我说了
还是那张表,查询数学成绩在60-90 的
select name,math from exam_result where math between 60 and 90;
或者这么写
select name,math from exam_result where math >= 60 and math < 90;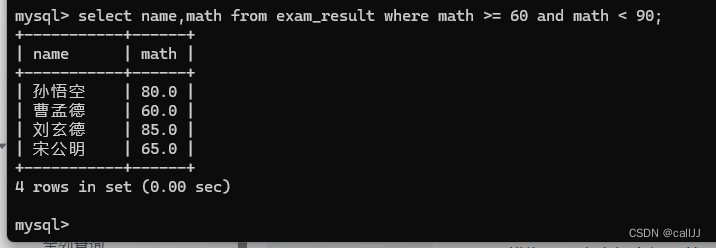
模糊匹配
-- % 匹配任意多个(包括 0 个)字符
总的来说,写条件查询就像英语写定语从句,多写几次就会了
分页查询
在数据库查询中,分页查询 (limit) 是一种非常常见的技术,尤其是在处理大量数据时。分页查询通过限制每次返回的记录数量,可以有效地管理和显示数据。
-- 从 0 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n;
-- 从 s 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT s, n;
-- 从 s 开始,筛选 n 条结果,比第二种用法更明确,建议使用
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n OFFSET s;比如,查询前三个的 id 和 name ,按 id 排序
select id,name from exam_result order by id limit 3;
可以看到,null 在首位,也确实只有前三个
其他的读者自己去练习吧
查询语句的书写和执行顺序(****)
看了那么多例子,很难记全东西, 所以记忆sql 语句需要一些逻辑
比如,顺序
书写顺序
select -- from --where--group--having--order by--limit ;
执行顺序
from -- where--group by--having--select--order by--limit;
查询还没结束哦,只不过我实在是写不动了,上述都是基础,还有进阶的聚合查询和联合查询,笔者以后更!!!!!
修改数据(update)
过了最多最全的查询,来到修改,这个是修改表的数据,而不是修改表的结构.
UPDATE table_name SET column = expr [, column = expr ...][WHERE ...] [ORDER BY ...] [LIMIT ...]语法如上
还是举例来看,还是那张表

我要修改孙十万的70的语文成绩改成90;
update exam_result set chinese=90 where name ='孙权';效果如下

把总成绩倒数前三的人的 数学加1分;
首先,找到倒数前三
select id,name,chinese+math+english as total from exam_result
order by total limit 1,3;然后,加分
update exam_result set math=math+1
order by chinese+math+chinese limit 4;效果如图

好的修改就到这里,也不难说实话
删除(delet)
删除数据
语法如下
DELETE FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT.....];举例,把孙悟空这一行从表上删了
delet from exam_result where name='孙悟空';

把表的数据删完
delete from exam_result;
注意,这和删表
drop table exam_result;有区别的, 一个是把里面的数据删了容器还在,后者是直接把锅砸了
看图

一个是表空了,一个是没有表了
删除写到这
上篇总结
总结就是写博客是最好的复习方式,我不是在写笔记,笔者是真的希望有人能看懂和学会!!!!!!!!
笔者花了大约3小时写完了上篇,主要是介绍了数据库的基础知识和一些基础的sql 语句
包括数据库的操作,表的操作 ,基础的 CRUD管理和组织表的数据
下篇,笔者写的是
数据库的约束,聚合查询,联合查询
索引,事物,Mysql 的 JDBC 编程
这篇关于[Mysql] 的基础知识和sql 语句.教你速成(上)——逻辑清晰,涵盖完整的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





