本文主要是介绍从 0 打造私有知识库 RAG Benchmark 完整实践,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
背景介绍
最近从 0 构建了一个大模型知识库 RAG 服务的自动化 Benchmark 评估服务,可以基于私有知识库对 RAG 服务进行批量自动化测试与评估。本文是对这个过程的详细记录。
本文实际构建的是医疗行业知识库,基于高质量的医学指南和专家共识进行构建。而实际的问答对也基础知识库已有文档生成,避免参考源不存在导致的大模型幻觉,可以更加客观反映 RAG 服务的能力。当然整体的构建流程是与行业无关的,可以参考构建其他的测评知识库。
RAG Benchmark 评估
为什么需要 RAG 评估
从早期实现 从开发到部署,搭建离线私有大模型知识库 时就提到过 RAG 的评估体系的构建,RAG 评估体系不可或缺的原因如下:
- RAG 服务的质量评估困难,因为 RAG 服务最终输出的就是一段针对问题的文本回答,开发人员可能会缺乏行业背景知识,无法给出客观评估;
- RAG 服务是一个需要持续迭代的服务,优化手段多种多样。如何验证优化手段的有效性,需要存在一个量化的判断标准,否则可能会负优化;
为什么不用通用 Benchmark
目前针对 RAG 服务的部分环节的 Benchmark 是存在的,比如针对大模型有 Lmsys Benchmark,针对 Embedding 模型有 mteb leaderboard,但是很少有完整的针对 RAG 提供的 Benchmark,我理解原因如下:
- RAG 服务的质量与知识库内容存在很大关系,RAG 服务目前没有完全标准的知识库以及对应的高质量问答对;
- RAG 服务的自动化文本评测相对困难,很难根据问题和答案给出完全客观的打分;
同时考虑到外部的公共 Benchmark 数据集缺失行业信息,无法基于我们期望的行业知识进行评测,最终选择了自建大模型知识库自动化 Benchmark 评测服务。
自动化评估构建流程
自动化评估 Benchmark 构建流程如下所示:
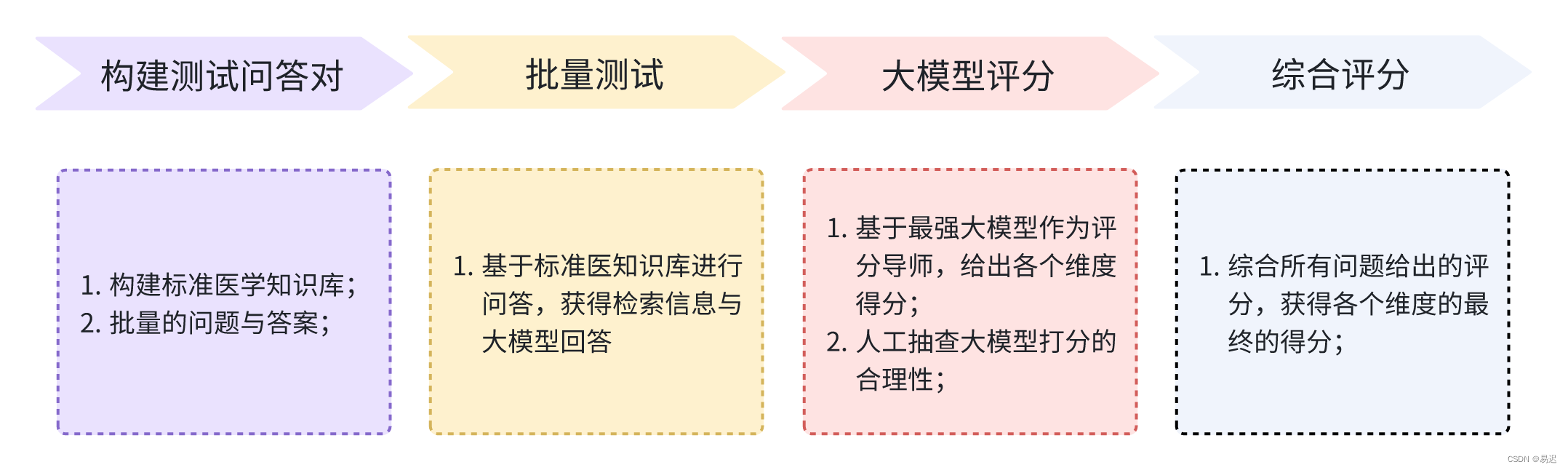
构建测试问答对
为了构建自动化测试,首先需要筛选出合适的行业文档信息,期望文档本身的质量比较高。在医疗领域,我们选择的是医学指南和专家共识,这样可以避免原始文档质量差带来的结果不佳的问题。
接下来需要根据这些文档生成对应的问答对。问答对需要能根据知识库可以得到正确答案,否则就很难验证 RAG 服务的能力了。
但是构建问答对十分耗时,最终选择了提供文档给线上大模型,基于线上的大模型自动生成问题,答案以及答案参考的原文片段。通过这种方式可以大幅减轻人工总结文档生成问题和答案的工作量。人工只需要参考大模型给出的原文片段判断问题和答案的合理性即可。实际的问答对如下所示:

人工过滤掉不合适的问题,以及答案有误的情况,这样就得到了一份可用的知识库,以及对应的问答对。我利用这种方式构建了包含 100 份高质量行业文档的知识库和 1000 个标准问答对。
批量测试
批量的自动化测试是基于 ragas 实现的,如果期望选择其他 RAG 自动化评测库,可以参考 之前的文章 查看其他可选方案。
批量测试基于下面的代码生成自动化测试的数据集:
import asynciofrom datasets import Datasetasync def batch_evaluate_chat(questions: list[str], ground_truths: Optional[list] = None):# 批量调用 RAG 服务接口获取回答与对应的上下文tasks = [search_knowledge_base_iter(q, ground_truth)for q, ground_truth in zip(questions, ground_truths)]results = await asyncio.gather(*tasks)question_list, answer_list, contexts_list, ground_truth_list = [], [], [], []for question, answer, contexts, ground_truth in results:question_list.append(question)answer_list.append(answer)contexts_list.append(contexts)ground_truth_list.append(ground_truth)# 构建测试获得的问题,答案,上下文以及标准答案data_samples = {"question": question_list,"answer": answer_list,"contexts": contexts_list,"ground_truth": ground_truth_list,}return Dataset.from_dict(data_samples), data_samples
大模型评分
在实际测试时,我期望获得所有测试问答对的详细信息,包括测试项中的问题,答案,上下文,正确答案以及各个评分项的得分。但是 ragas 只会给出测试数据集整体的平均得分,因此实际调用上面的 batch_evaluate_chat() 构建测试数据集时,会基于单个问题构建了自动化测试数据集,之后所有问题独立进行评分。具体如下所示:
from ragas import evaluate
from ragas.metrics import (answer_correctness,answer_relevancy,context_precision,context_recall,context_relevancy,faithfulness,
)# 每个问题构造对应的数据集,独立评分,得到每个问题详细评分async def do_evaluate(question, ground_truth, llm, embedding_model):questions = [question]ground_truths = [ground_truth] if ground_truth else Nonedataset, original_dataset = await batch_evaluate_chat(questions, ground_truths)result = evaluate(dataset,# 设置相关评测指标 https://docs.ragas.io/en/stable/concepts/metrics/index.htmlmetrics=[context_relevancy,faithfulness,answer_relevancy,answer_correctness,context_recall,context_precision,],llm=llm,embeddings=embedding_model,)# 将原始的问答对与结果合并在一起,方便后续生成详细结果evaluate_detail = dict()for key in original_dataset:evaluate_detail[key] = original_dataset[key][0]evaluate_detail.update(result)return evaluate_detail
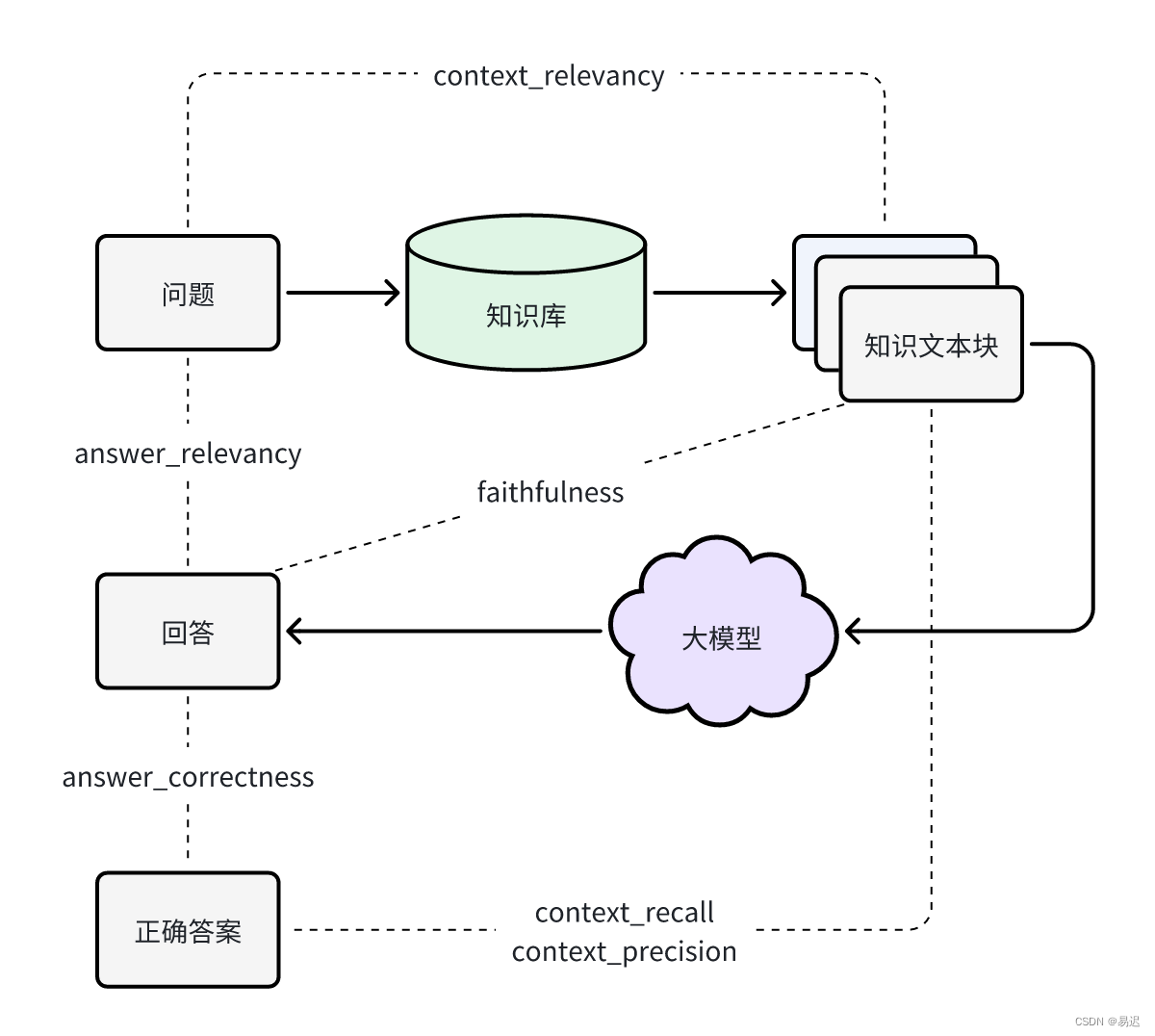
实际选择的指标除了经典的三维度的指标 context_relevancy, faithfulness 和 answer_relevancy,从实用角度出发,补充了下面指标:
answer_correctness: 根据生成答案与标准答案相比,得出生成答案的准确性,可以整体了解 RAG 服务的可靠性;context_recall: 根据上下文与标准答案相比,用于衡量正确答案是否被正确召回,可以判断 RAG 的检索能力;context_precision: 根据上下文与标准答案以及问题综合判断,确认召回的正确内容是否排名靠前,可以判断 RAG 检索的排序是否合适;
最终整体的评估维度如下所示:
测试结果分析
在完成构建了自动化测试之后,最终得到的结果导出为 excel,类似如下所示:
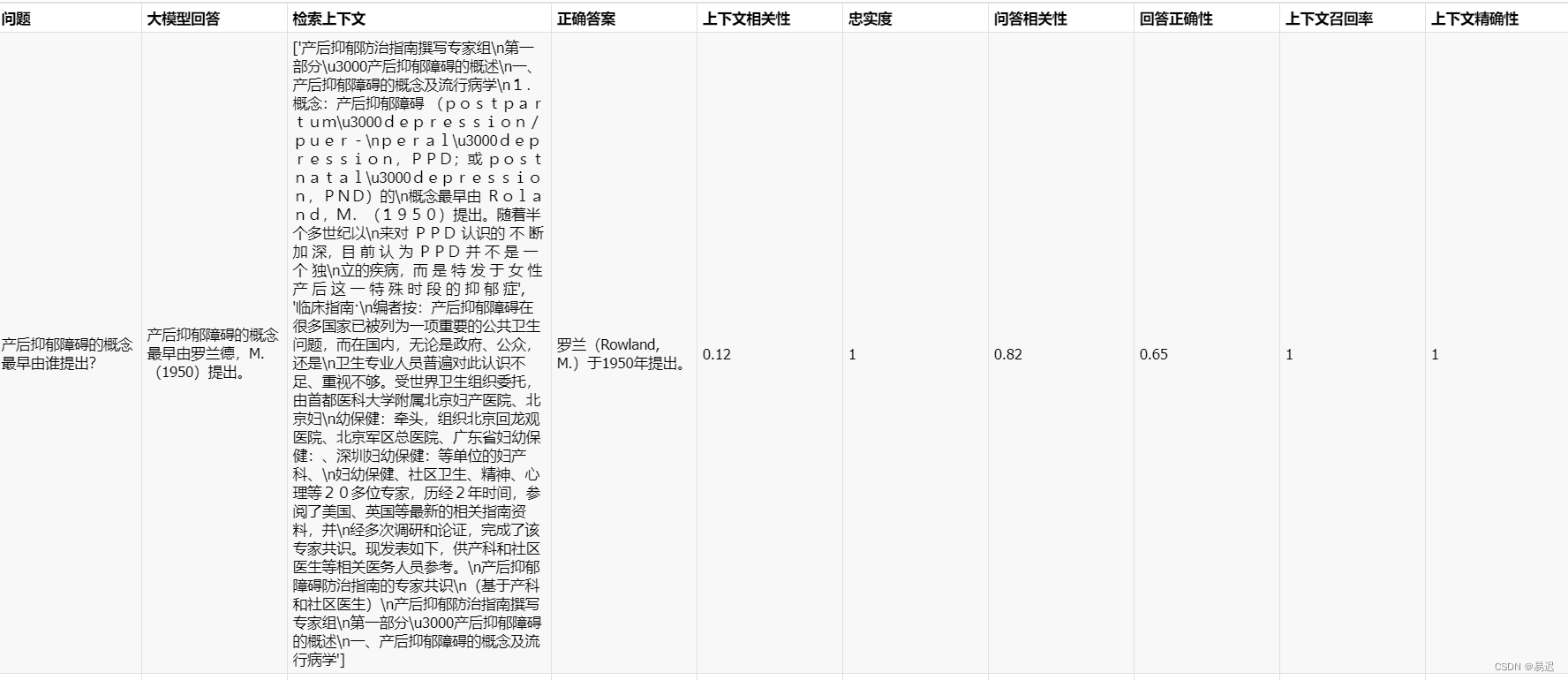
在得到大模型完整的自动化测试的结论后,还是需要人工进行分析,主要关注两部分的优化:
- 自动化测试指标的表征能力,现有的自动化测试指标是否正确反映 RAG 服务本身存在的问题,这一部分主要涉及自动化测试流程的优化;
- RAG 模块的优化,通过指标以及人工归因,确定 RAG 服务各个模块中存在的待优化问题,并根据影响范围确定优化的优先级;
总结
本文是对构建完整的 RAG 自动化评估 benchmark 的介绍,通过上面的流程,可以从 0 构建一个符合要求的自动化评估服务,在客观的数据的指导下定位 RAG 服务中存在的问题,从而迭代优化重点问题,提升 RAG 服务的质量。
这篇关于从 0 打造私有知识库 RAG Benchmark 完整实践的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






