本文主要是介绍hdfs文件系统增删查原理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1、hdfs读取文件原理
1.1、读取流程图解
1.2、架构层面读取流程详解
1.3、源码层面读取流程详解
2、hdfs写入文件原理
2.1、写入流程图解
2.2、架构层面写入流程
2.3、源码层面写入流程
3、hdfs删除文件原理
3.1、删除文件图解
3.2、架构层面删除流程
3.3、源码层面删除流程
1、hdfs读取文件原理
1.1、读取流程图解
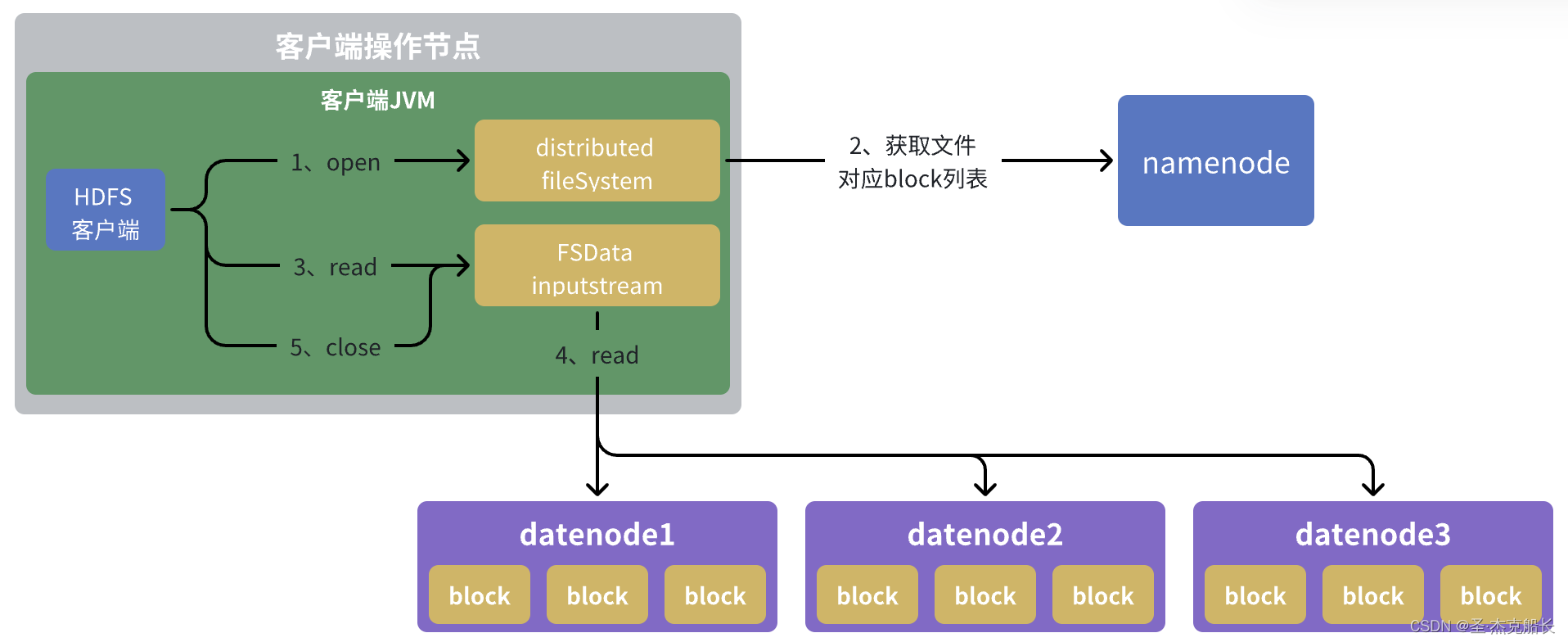
1.2、架构层面读取流程详解
- client向namenode节点发送rpc请求,获取block元数据信息,比如block存放位置;
- namenode会使情况返回文件的部分或者全部block列表,对于每个block,namenode都会返回该block副本的datanode地址;
- 客户端获取到返回的datanode地址,根据集群拓扑结构获取datanode与客户端的距离,然后进行排序,排序规则(网络拖布结构距离近的client靠前;心跳机制中超时汇报的datanode状态为STALE,这样的靠后);
- Client 选取排序靠前的 DataNode 来读取 block,如果客户端本身就是 DataNode,那么将从本地直接获取数据;底层上本质是建立 Socket Stream(FSDataInputStream),重复的调用父类 DataInputStream 的 read 方法,直到这个块上的数据读取完毕;
1.3、源码层面读取流程详解
1. 客户端请求文件信息
//客户端通过 DistributedFileSystem 类的 open 方法请求文件信息:
public FSDataInputStream open(Path f, int bufferSize) throws IOException {// 获取 DFSClient 实例DFSClient dfsClient = new DFSClient();// 调用 DFSClient 的 open 方法return dfsClient.open(f.toString(), bufferSize, true);
}2. DFSClient 获取文件信息
//在DFSClient类中,open方法与NameNode进行通信以获取文件信息:public DFSInputStream open(String src, int buffersize, boolean verifyChecksum) throws IOException {// 向 NameNode 发送打开文件请求return new DFSInputStream(src, buffersize, verifyChecksum);
}3. 获取数据块位置信息
//DFSInputStream 类负责获取文件的块信息
public DFSInputStream(String src, int buffersize, boolean verifyChecksum) throws IOException {this.src = src;this.buffersize = buffersize;this.verifyChecksum = verifyChecksum;// 获取文件的数据块信息openInfo();
}private void openInfo() throws IOException {// 向 NameNode 请求文件信息LocatedBlocks locatedBlocks = dfsClient.getNamenode().getBlockLocations(src, 0, Long.MAX_VALUE);this.blocks = locatedBlocks.getLocatedBlocks();
}4. 读取数据块
//DFSInputStream通过read方法从DataNode读取数据块
@Override
public synchronized int read(byte[] buf, int off, int len) throws IOException {// 确保文件打开checkOpen();// 读取数据块if (pos < getFileLength()) {// 获取当前数据块信息LocatedBlock currentBlock = getCurrentBlock();// 从 DataNode 读取数据byte[] blockData = readBlock(currentBlock, pos, len);// 将数据写入缓冲区System.arraycopy(blockData, 0, buf, off, len);pos += len;return len;} else {return -1; // 文件读取完毕}
}private byte[] readBlock(LocatedBlock block, long offset, int len) throws IOException {// 获取 DataNode 列表DatanodeInfo[] nodes = block.getLocations();for (DatanodeInfo node : nodes) {try {// 与 DataNode 建立连接InetSocketAddress targetAddr = NetUtils.createSocketAddr(node.getXferAddr());Socket socket = new Socket();socket.connect(targetAddr, dfsClient.getConf().socketTimeout);// 发送读取请求DataOutputStream out = new DataOutputStream(socket.getOutputStream());out.writeLong(block.getBlock().getBlockId());out.writeLong(offset);out.writeInt(len);out.flush();// 接收数据DataInputStream in = new DataInputStream(socket.getInputStream());byte[] data = new byte[len];in.readFully(data);return data;} catch (IOException e) {// 处理读取失败continue;}}throw new IOException("Failed to read block " + block.getBlock().getBlockId());
}5. 数据组装
//客户端按顺序将读取到的数据块组装成完整的文件
@Override
public void readFully(long position, byte[] buffer, int offset, int length) throws IOException {// 确保文件打开checkOpen();// 逐个读取数据块并组装while (length > 0) {// 获取当前数据块信息LocatedBlock currentBlock = getCurrentBlock();// 计算读取长度int bytesToRead = Math.min(length, (int)(currentBlock.getBlockSize() - offset));// 从 DataNode 读取数据byte[] blockData = readBlock(currentBlock, position, bytesToRead);// 将数据写入缓冲区System.arraycopy(blockData, 0, buffer, offset, bytesToRead);offset += bytesToRead;length -= bytesToRead;position += bytesToRead;}
}2、hdfs写入文件原理
2.1、写入流程图解
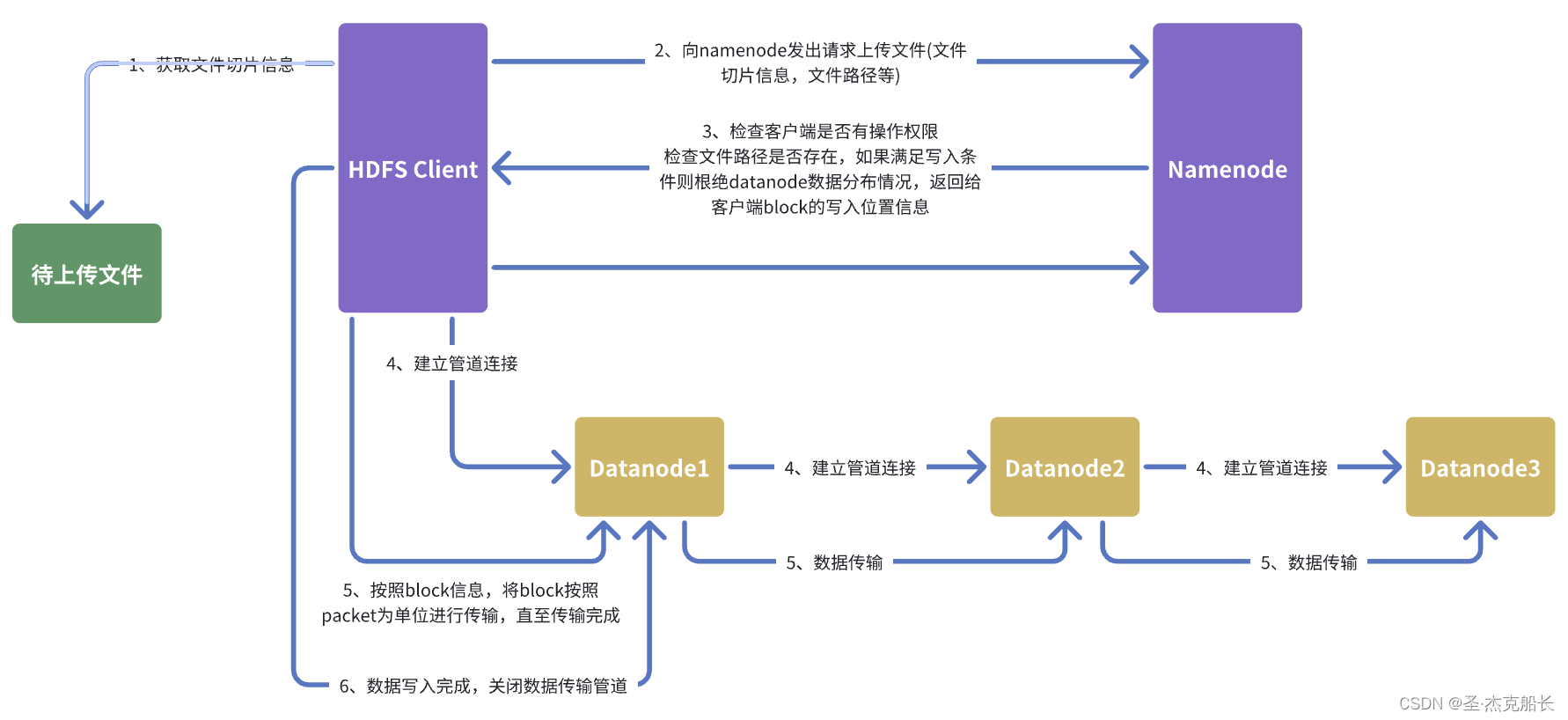
2.2、架构层面写入流程
1)客户端初始化写入请求
客户端向NameNode发送一个创建文件的请求,包括文件的路径和其他元数据信息。
NameNode检查是否有同名文件存在,如果没有则创建一个新的文件条目,并返回一个写入 的确认信息给客户端。
2)分块写入数据
HDFS将文件分成多个块(默认块大小为128MB,可以配置)。
客户端负责将数据分成适当大小的块进行写入。
3) 数据流和数据节点选择
客户端从NameNode获取数据块副本的存储位置,NameNode会选择若干个DataNode来存储 每个数据块的副本(默认3个副本)。
客户端通过Pipeline方式将数据块写入到这些DataNode。
4)数据写入DataNode
客户端首先将数据写入第一个DataNode。
第一个DataNode在接收到完整的数据块后,将数据传输给第二个DataNode,第二个 DataNode再传输给第三个DataNode,依此类推,形成一个数据流管道。
5)数据校验和确认
每个DataNode在接收到数据块后,会进行数据校验(使用CRC校验),DataNode向客户端 返回确认信息,确认数据块已经成功写入。
6)最终确认和元数据更新
客户端在接收到所有DataNode的确认信息后,向NameNode发送一个确认请求,表示数据块 已经成功写入。
NameNode更新文件的元数据信息,包括文件长度、数据块的位置和副本信息。
2.3、源码层面写入流程
1. 客户端请求文件写入
DFSOutputStream out = dfs.create(filePath, true);2. 创建文件并获取元数据
#客户端通过 NameNode 创建文件,并获取文件元数据,包括所需的 DataNode 列表。
namenode.create(filePath, clientName, true, replication, blockSize);#namenode创建block块
LocatedBlock addBlock(String src, String clientName, ExtendedBlock previous, DatanodeInfo[] excludeNodes, long fileId, String[] favoredNodes) throws IOException {// 分配新的数据块Block newBlock = allocateNewBlock(src, clientName, previous, excludeNodes, fileId, favoredNodes);return new LocatedBlock(newBlock, new DatanodeInfo[0]);
}3. 初始化写入流
#客户端初始化 DFSOutputStream,准备写入数据块。
DFSOutputStream out = new DFSOutputStream(...);#datastream写入数据包
class DataStreamer extends Daemon {public void run() {while (!closed && !hasError) {Packet packet = getPacket();if (packet == null) {continue;}dfsClient.datanode.writeBlock(packet);}}
}4. 块的分配
#在 DFSOutputStream 的构造函数中,分配第一个数据块。通过 DFSOutputStream#nextBlockOutputStream 方法,调用 DFSClient#namenode.addBlock 方法向 NameNode 请求分配一个新的数据块。
ExtendedBlock block = namenode.addBlock(src, clientName, previous, excludeNodes, fileId, favoredNodes);
5. 数据流写入 DataNode
#DFSOutputStream 维护一个 DataStreamer 对象,该对象负责将数据写入 DataNode。数据以数据包的形式写入,具体通过 DataStreamer#run 方法进行。
class DataStreamer extends Daemon {public void run() {// 数据包的生成与写入Packet packet = new Packet();dfsClient.datanode.writeBlock(packet);}
}6. 数据包的传输
#数据包通过 DataStreamer 传输给 DataNode。DataNode 接收到数据包后,写入本地磁盘并通过数据流传递给下一个 DataNode(如果存在副本)。
DataNode datanode = new DataNode(...);
datanode.receiveBlock(block, ...)7. 确认接收
#每个 DataNode 接收到数据包并写入后,会发送确认信息给客户端,确认数据已经被成功写入。
DataNode.sendAck();8. 数据块的关闭
#所有数据块写入完成后,客户端关闭写入流。
out.close();#在DFSOutputStream的close方法中,调用DFSClient的namenode.complete方法通知NameNode文件写入完成。
namenode.complete(src, clientName, lastBlock);
9. 元数据更新
NameNode 更新元数据,标记文件状态为已完成,并记录文件的块信息和副本位置。
10. 错误处理
如果写入过程中出现错误,DFSOutputStream 会处理错误并进行重试或失败处理。源码中会有重试逻辑和错误处理代码。
3、hdfs删除文件原理
3.1、删除文件图解
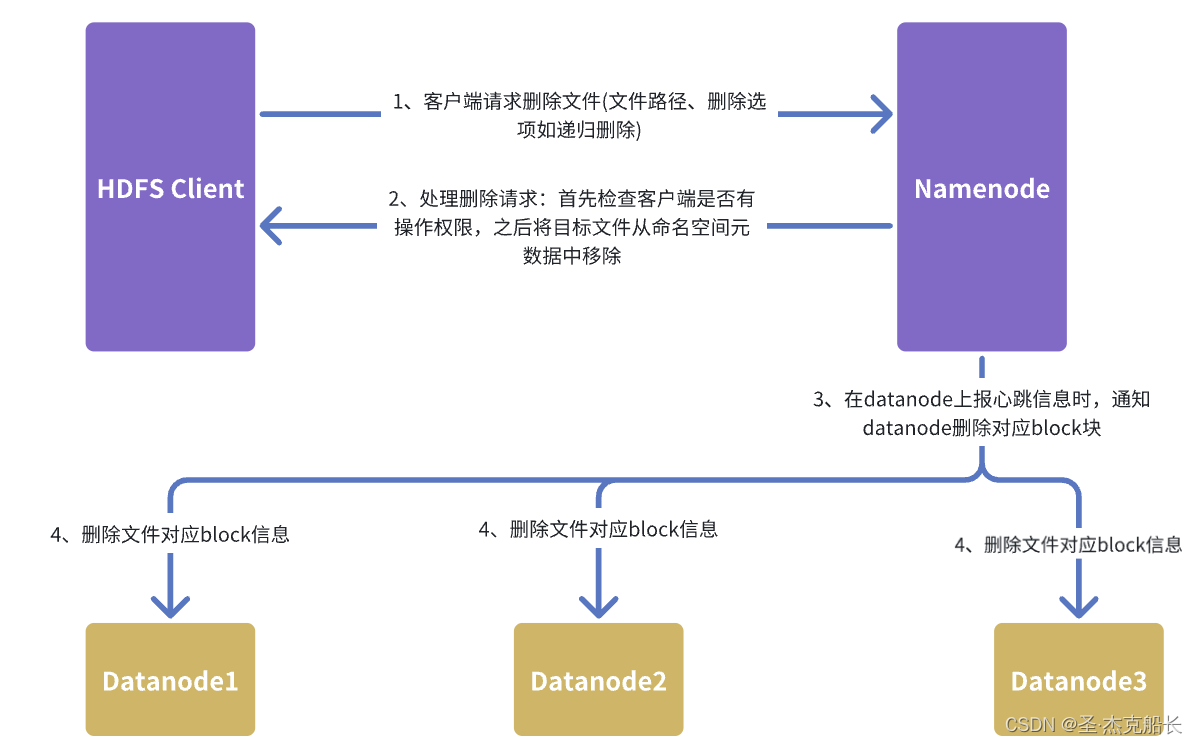
3.2、架构层面删除流程
1)客户端请求删除文件
客户端通过HDFS API发起删除文件的请求。客户端将文件路径和删除选项(例如是否递归删 除)发送到NameNode。
2)NameNode 处理删除请求
NameNode接收到客户端的删除请求后,首先会进行权限检查,以确保请求发起者有删除该 文件的权限。
3) 更新元数据和记录日志
通过权限检查后,NameNode会更新文件系统的元数据,将目标文件或目录从命名空间中删 除。同时,NameNode会将这一操作记录到EditLog中,以确保操作的持久化。
4)通知DataNode清理数据块
NameNode不会立即通知DataNode删除对应的数据块文件。相反,NameNode将这些数据块 标记为“待删除”,并将这一信息加入到一个待处理的删除队列中。在DataNode的定期心跳汇 报中,NameNode会将需要删除的数据块信息传递给相应的DataNode。
5) DataNode 执行数据块删除
DataNode接收到来自NameNode的删除指令后,会从本地存储中删除相应的数据块文件,并 释放相关的存储空间。
3.3、源码层面删除流程
1. 客户端请求删除文件
//客户端通过 DistributedFileSystem 类的 delete 方法请求删除文件
public boolean delete(Path f, boolean recursive) throws IOException {// 获取 DFSClient 实例DFSClient dfsClient = new DFSClient();// 调用 DFSClient 的 delete 方法return dfsClient.delete(f.toString(), recursive);
}2. DFSClient 向 NameNode 发送删除请求
//在 DFSClient 类中,delete 方法与 NameNode 进行通信以删除文件:
public boolean delete(String src, boolean recursive) throws IOException {checkOpen();try {// 向 NameNode 发送删除文件请求return namenode.delete(src, recursive);} catch (RemoteException re) {throw re.unwrapRemoteException(AccessControlException.class,FileNotFoundException.class,SafeModeException.class,UnresolvedLinkException.class);}
}3. NameNode 处理删除请求
//NameNode 在接收到删除请求后,更新文件系统的元数据,将文件标记为已删除,并记录操作到 EditLog 中。关键类是 FSNamesystem 和 INode。
public boolean delete(String src, boolean recursive) throws IOException {// 获取写锁writeLock();try {// 调用 FSNamesystem 的 delete 方法处理删除请求return fsNamesystem.delete(src, recursive);} finally {// 释放写锁writeUnlock();}
}boolean delete(String src, boolean recursive) throws IOException {checkOperation(OperationCategory.WRITE);FSPermissionChecker pc = getPermissionChecker();boolean ret = false;writeLock();try {checkOperation(OperationCategory.WRITE);ret = deleteInt(pc, src, recursive);} finally {writeUnlock();}return ret;
}private boolean deleteInt(FSPermissionChecker pc, String src, boolean recursive)throws IOException {// 查找文件对应的 INodeINode targetNode = dir.getINode(src);if (targetNode == null) {throw new FileNotFoundException("File/Directory does not exist: " + src);}// 权限检查checkPermission(pc, targetNode, FsAction.WRITE);// 递归删除子目录和文件if (targetNode.isDirectory() && !recursive) {throw new IOException("Cannot delete directory: " + src + " without recursive flag");}// 从目录中删除节点boolean removed = dir.remove(src, targetNode);if (removed) {// 记录操作到 EditLoglogAuditEvent(true, "delete", src);}return removed;
}4. 更新 DataNode
//在删除文件的过程中,NameNode 不会立即通知 DataNode 删除对应的数据块。DataNode 会定期向 NameNode 汇报数据块的状态,NameNode 在收到汇报后会通知 DataNode 删除不再需要的数据块。
void removeBlocks(List<Block> blocks) {for (Block block : blocks) {addToInvalidateBlocks(block);}processPendingInvalidateBlocks();
}void addToInvalidateBlocks(Block block) {invalidateBlocks.put(block.getBlockId(), block);
}void processPendingInvalidateBlocks() {for (Block block : invalidateBlocks.values()) {DataNode dn = getDataNode(block);if (dn != null) {dn.removeBlock(block);}}
}5. DataNode 删除数据块
void removeBlock(Block block) {File blockFile = getBlockFile(block);if (blockFile != null && blockFile.exists()) {blockFile.delete();}
}这篇关于hdfs文件系统增删查原理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






