本文主要是介绍【软件测试大赛Web应用省赛】跳坑记录,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【软件测试大赛Web应用省赛】跳坑记录
本文写在预赛通过的基础上,默认后来者已经接触过web应用测试,并有一定的基础知识。
本文写于2020.11.8省赛结束,希望这些坑以后不会再有人跳进去。
【前排提示】没学过前端因为懒 ,所以有关网页的术语可能使用有误,烦请理性讨论_(:з)∠)_有错的地方可以在评论区指出~
1.frame的切换
今年的省赛功能测试题目是登录网易云进行操作(前两步操作如下图)
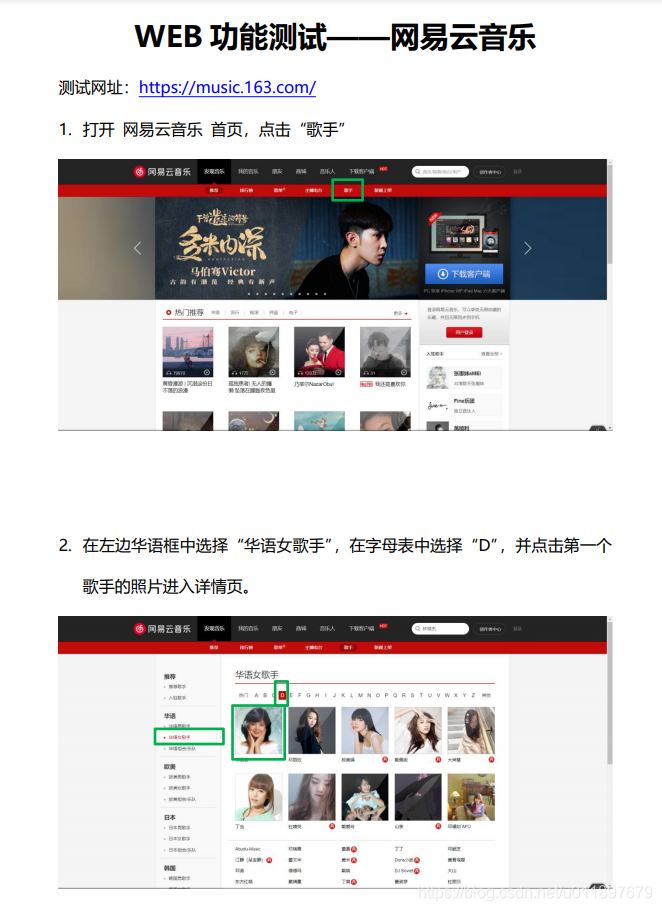
第一步点击“歌手”,没有问题,直接复制xpath然后click就行。
问题在第二步,进入到歌手页面,发现无论怎么复制“华语女歌手”的xpath,甚至是页面上其他地方的xpath,都无法进行点击操作,会提示你“not such element”。这是为什么呢?我们来看一下网页结构:
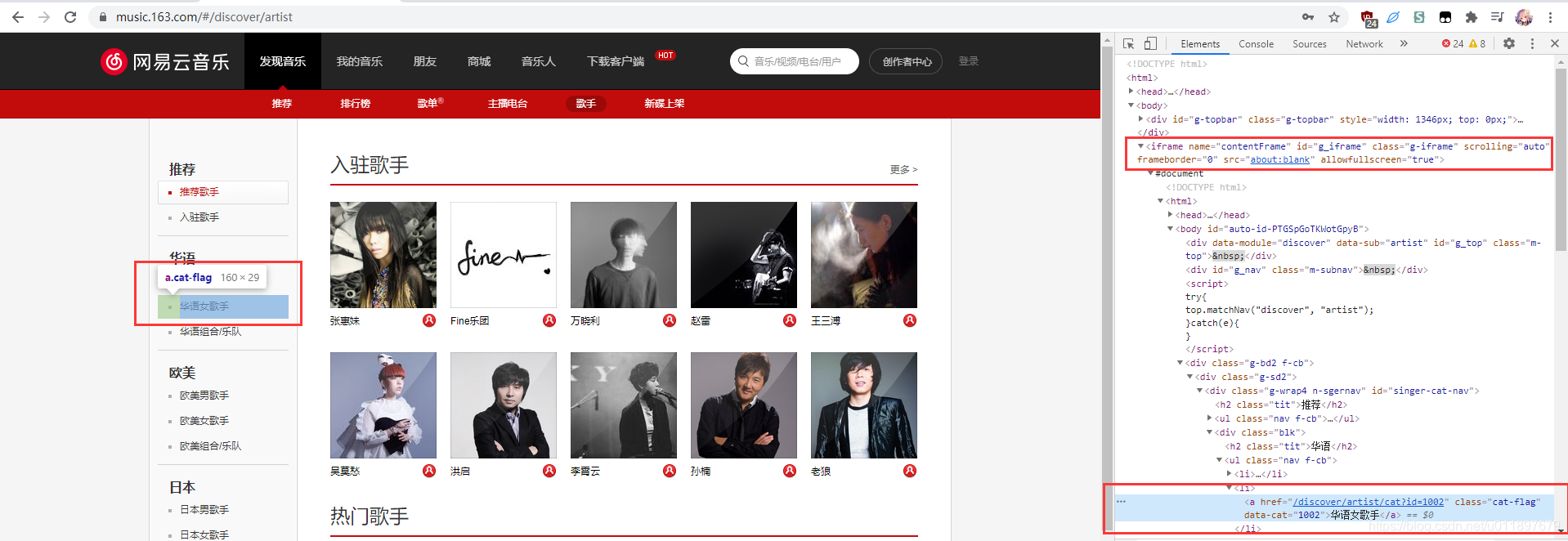
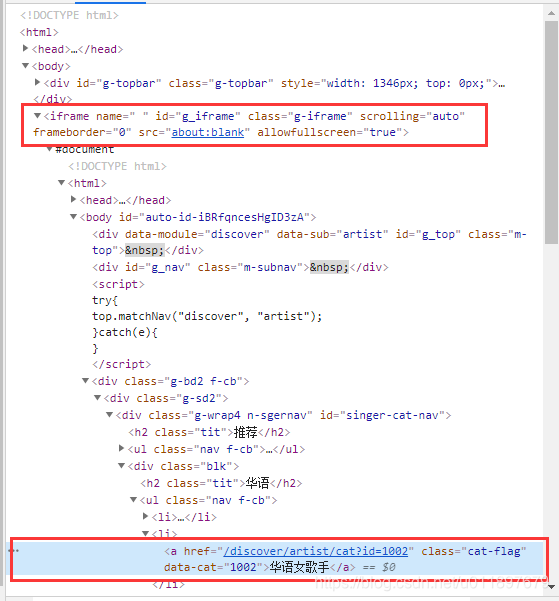
右上的红框表示,题目要求的元素包含在一个名字叫做“contentFrame”的iframe里面,这就是我们无法进行点击操作的原因。简单来说,网页的自动化操作是有空间限制的。我们第一步点进“歌手”页面的这步操作,“歌手”元素所在的空间是默认frame;而第二步点击“华语女歌手”,它所在的空间是另外一个iframe,我们需要通过语句来进入这个iframe才能进行自动化操作:
driver.switchTo().frame("contentFrame");//进入iframe
driver.switchTo().defaultContent();//返回默认frame
类比一下,上面的操作就像我们用命令提示符的时候,如果现在的工作目录是D盘,而你现在想删除C盘根目录的某个文件(这里假如它叫233.txt好了),那么直接 del 233.txt 是行不通的,要先把工作目录转换到C盘根目录,再 del 233.txt 。
要注意,题目之后的操作要求中,有的元素在iframe里面,有的在默认frame里面,要根据情况使用上面的语句来切换工作frame。
2.变化的xpath
先来看一下题目的第三步操作要求:

这个所谓的“添加到播放列表”的xpath复制出来是这样的:
driver.findElement(By.xpath("//*[@id=\"2287551604833444877\"]/td[3]/div/a")).click();
你会发现无法进行点击,显示“not such element”。更绝望的是,你每次复制出来的xpath都不一样。这是因为网抑云的这个按钮,在采用复制相对xpath的时候,复制出来的是包含时间戳的xpath(就是代码中“id=\”后面那一串数字),这个时候我们就不能用这个xpath了(毕竟每时每刻都不同),我们要采用绝对xpath,或者说full xpath。
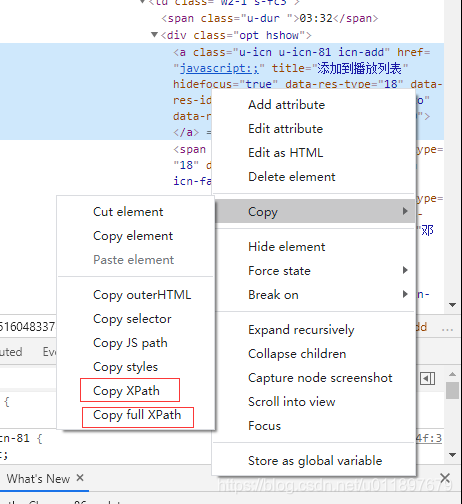
我们复制出来的绝对xpath长这样:
driver.findElement(By.xpath("/html/body/div[3]/div[1]/div/div/div[3]/div[2]/div/div/div/div[1]/table/tbody/tr[3]/td[3]/div/a")).click();
平常的时候用相对就行,因为绝对太长了()
3.(此条不确定是否为得分点)用文字定位元素
有一步操作是这样的:

这时候可以直接
driver.findElement(By.linkText("模特")).click();
由于时间仓促,没有测试这步操作是否正确得分,仅供参考。
今年主要是没想到用iframe,浪费了大概两个小时(而且之前也没有很多web应用测试的文章),希望这篇文章能为后来者提供一定的帮助。
随意转载
大概没人会转载吧(
这篇关于【软件测试大赛Web应用省赛】跳坑记录的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




