本文主要是介绍异步爬虫:aiohttp 异步请求库使用:,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
使用requests 请求库虽然可以完成爬虫业务,但是对于异步任务来说,它是做不到的, 这时候我们需要借助 aiohttp 异步请求库来完成异步爬虫的编写:
话不多说,直接看示例:
注意:楼主使用的python版本是最新的,3.12的py版本, 另外pycharm使用的也是最新版的 2024版本的。 请务必与我保持一致, 否则会报很多莫名其妙的异常信息。
下载:
使用aiohttp 异步请求库请先pip 下载:
pip install aiohttp基本实例:
import asyncio
import aiohttpasync def get(session, url):async with session.get(url) as response:return await response.text(), response.statusasync def test():url = "http://www.baidu.com"async with aiohttp.ClientSession() as session:html_text, status = await get(session, url)print(html_text)print(status)if __name__ == '__main__':asyncio.run(test())以上代码示例首先我们需要导入两个库,分别是aiohttp, asyncio, 因为要实现异步任务,而启动异步需要使用asyncio, 关于异步的知识点请自行查阅补充。
其次使用 async 关键字定义了一个 get 异步函数, 它接受了 session, url 两个参数, 而session则为aiohttp 中客户端ClientSession() 对象, 因为aiohttp 它提供了两套业务功能, 分别是服务端和客服端, 服务端主要就是实现处理客户端发送请求的异步业务, 而客户端,就是发送请求的,我们学爬虫,就需要学aiohttp 提供的客户端操作功能。 言归正传, 在这个get 方法中, 使用 async 关键字来声明一个异步上下文管理器<with ... as ...>, 然后返回所得到的响应,
而在test 异步函数中, 创建了一个ClientSession 对象, 然后调用get 函数,将session对象和url传递进去, 最后调用asyncio.run 启动协程任务。
请求:
GET:
对于一些有关于Get 请求携带参数的情况,我们可以使用 params 形参来完成
async def test():params = {"name": "I love Python", "code": 520}url = "https://www.httpbin.org/get"async with aiohttp.ClientSession() as session:# 使用params 形参传递get 请求数据async with session.get(url=url, params=params) as response:print(await response.text())if __name__ == '__main__':asyncio.run(test())aiohttp 也提供了 POST, PUT, DELETE, HEAD, PATCH, OPTIONS 等请求方式。
POST:
而对于post 请求表单提交的数据, 例如Content-Type 为: application/X-www-form-urlencoded 的数据, 我们可以使用 data 形参来完成, 楼主看了一下源码,如果post 传递的数据为 json, 楼主斗胆猜一下,应该为json 形参,我们可以看一下源码:
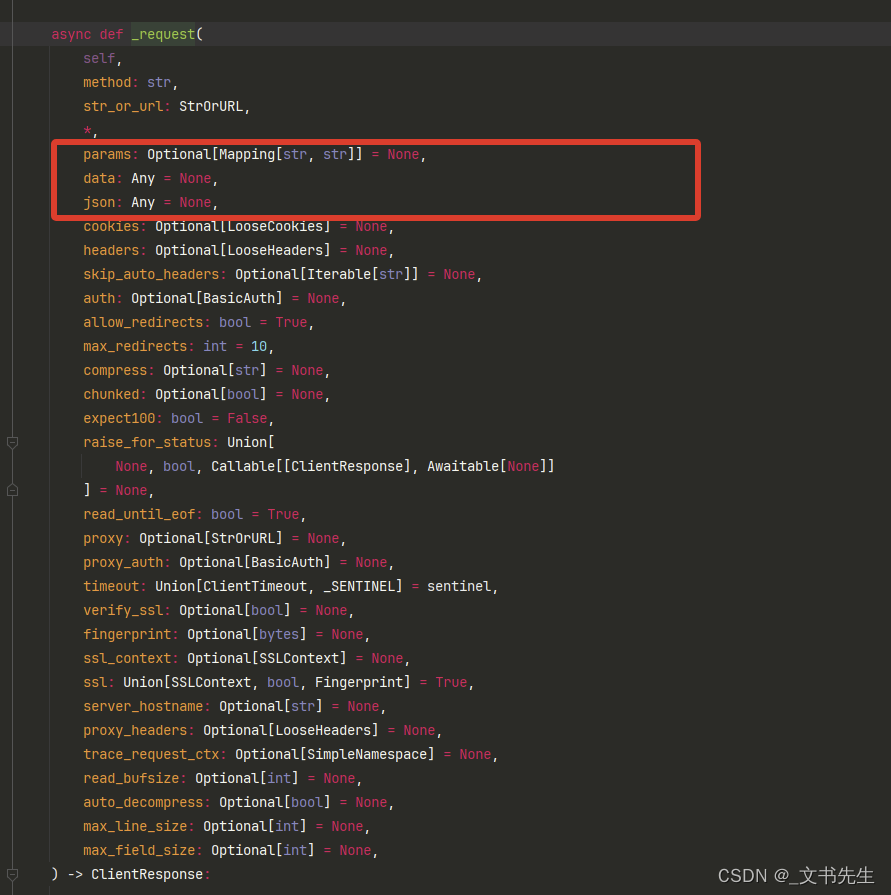
由此可见,它的使用方式几乎和 requests 同步请求库一模一样
async def test():data = {"name": "I love Python", "code": 520}url = "https://www.httpbin.org/post"async with aiohttp.ClientSession() as session:# 使用 data 形参 传递 表单提交的数据async with session.post(url=url, data=data) as response:print(await response.text())if __name__ == '__main__':asyncio.run(test())响应:
对于响应结果,我们可以调用一下方法来获取其中的:状态码,响应头,响应体,响应体二进制内容,响应体JSON数据。
async def test():data = {"name": "I love Python", "code": 520}url = "https://www.httpbin.org/post"async with aiohttp.ClientSession() as session:async with session.post(url, data=data) as response:print(response.status) # 响应状态码print(response.headers) # 响应头print(await response.text()) # 获取响应体print(await response.read()) # 获取二进制数据print(await response.json()) # 获取相响应的JSON数据if __name__ == '__main__':asyncio.run(test())超时设置:
我们可以借助aiohttp 提供的 ClientTimeout 对象来实现超时, 如果超时还未请求到数据,则抛异常
async def test():data = {"name": "I love Python", "code": 520}url = "https://www.httpbin.org/post"timeout = aiohttp.ClientTimeout(total=1) # 设置超时时间,单位为 秒async with aiohttp.ClientSession(timeout=timeout) as session:async with session.post(url, data=data) as response:passif __name__ == '__main__':asyncio.run(test())ClientTimeout 对象同样还提供了其它参数, 例如:connect, socket_connect 等等, 详细参考官方文档:
https://docs.aiohttp.org.en.stable/client_quickstart.html#timeouts
并发限制:
由于异步爬虫拥有非常非常高的并发量, 如几万,几十万,甚至上百万都有可能, 但是如此高的并发量,目标服务器很可能无法再短时间内响应,而且有瞬间将目标服务器爬挂掉的危险, 所以,我们需要控制一下爬取的并发量。
我们可以借助asyncio 的 Semaphore 来控制并发量:
# 最高并发 5 个
CONCURRENCY = 5url = "http://www.baidu.com"# 创建信号量对象 并将最大并发量常量传递进来
semaphores = asyncio.Semaphore(CONCURRENCY)session = Noneasync def test():# 使用信号量对象创建异步上下文即可控制最高并发量async with semaphores:print("爬取ing: ", url)async with session.get(url) as response:await asyncio.sleep(1)return await response.text()async def main():global sessionsession = aiohttp.ClientSession()test_tasks = [test() for i in range(1000)]await asyncio.gather(*test_tasks)if __name__ == '__main__':asyncio.run(main())完了.... aiohttp 官方网站: https://docs.aiohttp.org/
这篇关于异步爬虫:aiohttp 异步请求库使用:的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






