本文主要是介绍合合信息文档解析工具重磅升级!智能识别,效率翻倍!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

官.网地址:合合TextIn - 合合信息旗下OCR云服务产品
智能文档处理(IDP)是利用人工智能技术,自动从复杂的非结构化和半结构化文档中抽取关键数据,并将其转换成结构化数据的技术。能够自动识别、提取并结构化处理文档中的关键信息。这种技术通常基于自然语言处理(NLP)和计算机视觉等先进技术,可以应用于各种类型的文档,如PDF、Word、Excel、图片等。
智能文档抽取的主要功能包括:
文本抽取:从文档中提取出所有文字内容,包括标题、正文、表格等。
实体识别:识别文档中的特定实体,如人名、地名、组织名、日期、金额等。
关键信息提取:根据预设的规则或模型,从文档中提取出关键信息,如合同条款、财务数据、项目进度等。
结构化输出:将提取出的信息以结构化的形式输出,如JSON、XML、CSV等。
自动化处理:可以与业务流程集成,实现自动化的文档处理,提高工作效率。
智能文档抽取在许多领域都有广泛的应用,如金融、法律、医疗、人力资源等。
下面将以金融场景为例,对金融大数据业务场景进行详细介绍。
一、智能文档解析赋能金融大数据场景
在金融大数据服务行业,尤其是在财报和年报季,企业面临着巨大的数据处理挑战。传统的数据录入方法依赖于数据清洗和正则表达式来提取网页内容,然而这些方法在处理格式多样、版面复杂的文档时效果不佳。这导致重要信息难以高效准确地转换为可用数据,给企业带来了很大的困扰。
随着大模型的企业级应用的推广,金融大数据行业开始采用“数据+文档解析+ LLM + Prompt”的模式,以简化工作流并提高效率。
这种新方法相比传统的正则表达式具有明显的优势。编写Prompt更加易于维护,降低了使用门槛,并且借助大模型的强大能力,显著提升了内容解读和数据分析的效率。
为了解决如何将文档内容转化为LLM友好格式的问题,合合信息提供了一种高效、稳定、可靠的文档解析工具。该工具能够将各种格式的文档内容转化为LLM可以读取和分析的数据格式,从而极大地提高了数据处理的效率和准确性。
通过使用合合信息的文档解析工具,企业可以在短时间内处理大量数据输入。同时,该工具还能够确保数据质量高,避免了传统方法中可能出现的数据错误和遗漏问题。这使得企业在财报和年报季等关键时期能够更加高效地获取和利用数据,为企业决策提供有力支持。
二、TextIn vs. X:当前产品能实现的解析速度
目前,合合信息TextIn文档解析100页文档的速度提升至最快2秒内,这在业内处于怎样的水准?
要回答这个问题,速度测试可以展现最直观的数据。
以一份企业年报为例,技术团队对当前产品能够实现的解析速度进行对比测试。选择的企业年报文件大小为38.8MB,共49页,文中包含形式多样的图表、数据、证照等页面,如下图所示。

测试使用了TextIn、Llamaparse及国内某常用大模型问答产品对文档进行解析。
LlamaParse是由LlamaIndex创建的一项技术,用于解析和表示PDF文件,以便通过LlamaIndex框架进行高效检索和上下文增强,适用于复杂PDF文档,是目前讨论度较高的开源解析器。
使用对话式大模型进行文档解析与问答则是现在C端的常用场景。使用同一份文件,选择这两款产品与TextIn进行测试,速度测试结果如下。

对TextIn与Llamaparse,使用的方式均为调用API接口,并使用测试脚本,可以直观地看到运行所用时长。
对于大模型产品,上传一份PDF后,界面上会先后显示“上传中...”和“解析中...”两种状态,表格中端到端时间计算方式为上传与解析时间总和。其中,“上传中”这个状态,在控制面板中对应的是一个xhr请求。上传完成后转换到“解析中”状态,该状态对应的是“parse_process”这个请求。
上表列出了各个产品的解析速度与端到端速度(含上传时间)。测试均在相同网络情况下进行。其中,Llamaparse不支持解析速度的单独获取,仅可测量端到端速度。
对于同一份文档,TextIn文档解析具体展现了强大的速度优势。在企业级的使用场景下,当文档数量以百万,甚至千万页计,解析速度将成为影响业务场景落地、大模型开发效率重要的因素之一。
三、体验入口
在TextIn平台,开发者可以注册账号并随时试用最新版TextIn文档解析工具。
访问链接:
TextIn - 机器人市场

点击【免费体验】,即可在线试用,如下图所示:
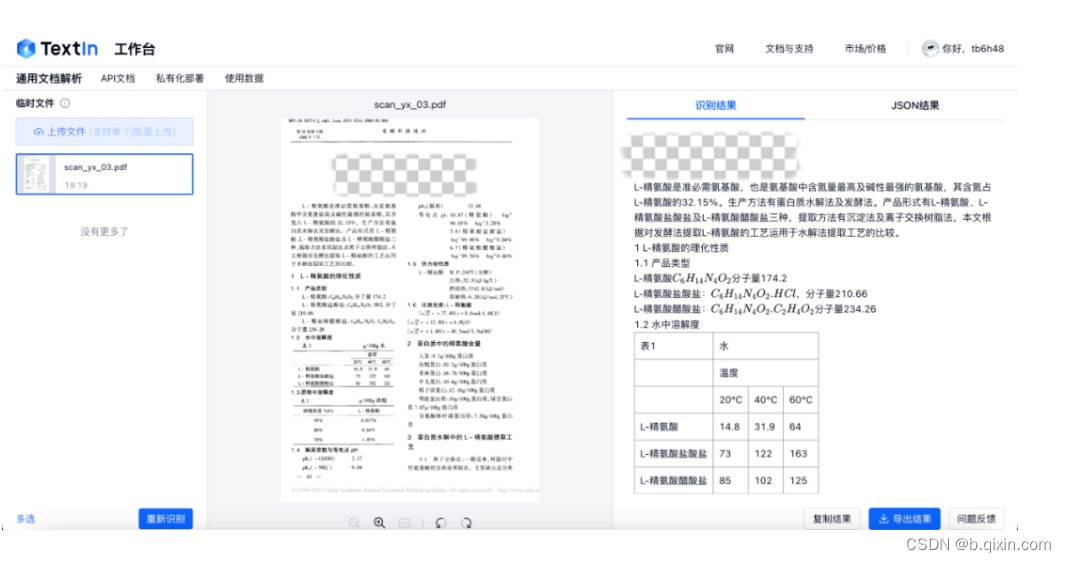
如果想试试用代码调用,也可以访问对应的接口文档内容:
TextIn - API中心 - 通用文档解析
这篇关于合合信息文档解析工具重磅升级!智能识别,效率翻倍!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







