本文主要是介绍自注意力与卷积高效融合!多SOTA、兼顾低成本与高性能,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在自注意力机制中,模型计算输入序列中不同位置的相关性得分,以生成连接权重,从而关注序列中的重要部分。而卷积通过滑动窗口的方式,在输入上应用相同权重矩阵来提取局部特征。
如果将以上两者结合,就可以同时利用自注意力捕捉长距离依赖关系和卷积运算提取局部特征的能力,让模型更全面地理解输入数据(特别是在处理复杂任务时),实现更高的性能和更低的计算成本。比如典型案例X-volution与ACmix。
目前这种结合策略的高质量成果已有不少,我从中整理了10个比较有代表性的供同学们参考,原文以及开源代码都整理好了,希望能给各位的论文添砖加瓦。
论文原文以及开源代码需要的同学看文末
X-volution: On the unification of convolution and self-attention
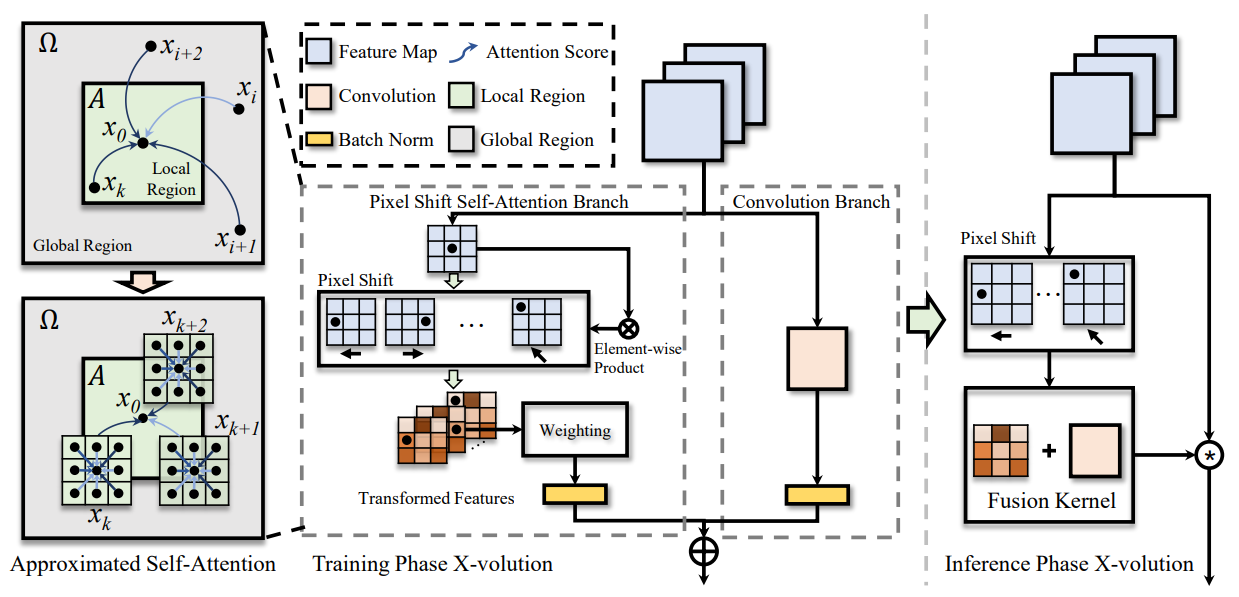
方法:本文提出了一种新的原子操作符X-volution,将卷积和自注意力操作符集成在一起,通过实验证明了它在图像分类、目标检测和实例分割等任务上取得了显著的性能改进。
创新点:
-
提出了X-volution原子操作符,将基本的卷积和自注意力操作符整合到一个统一的计算块中,从而在local vs. non-local/linear vs. non-linear这两方面都能获得非常显著的性能提升。
-
首次理论推导了一种全局自注意力近似方案PSSA,通过这种方案能够在计算上转换为卷积操作,从而简化了模型的拓扑结构。
-
在图像分类、目标检测和实例分割等主流视觉任务上进行了广泛的定性和定量评估,结果表明X-volution操作符取得了非常有竞争力的改进效果。

On the Integration of Self-Attention and Convolution
方法:本文揭示了自注意力和卷积之间的紧密关系,并提出了一种有效且高效的混合模型ACmix。该研究对于深入理解和改进卷积和自注意力模块在计算机视觉任务中的应用具有重要意义。

创新点:
-
将传统的卷积和自注意力模块结合在一起,形成一种混合模型,名为ACmix。ACmix利用了卷积和自注意力的优势,并且与纯卷积或自注意力相比,具有更小的计算开销。
-
揭示了自注意力和卷积之间的紧密关系,发现它们在投影输入特征图方面都使用了相同的1×1卷积操作。基于这一发现,提出了ACmix模型,通过共享相同的重型操作来将自注意力和卷积模块集成在一起。

UniFormer: Unifying Convolution and Self-attention for Visual Recognition
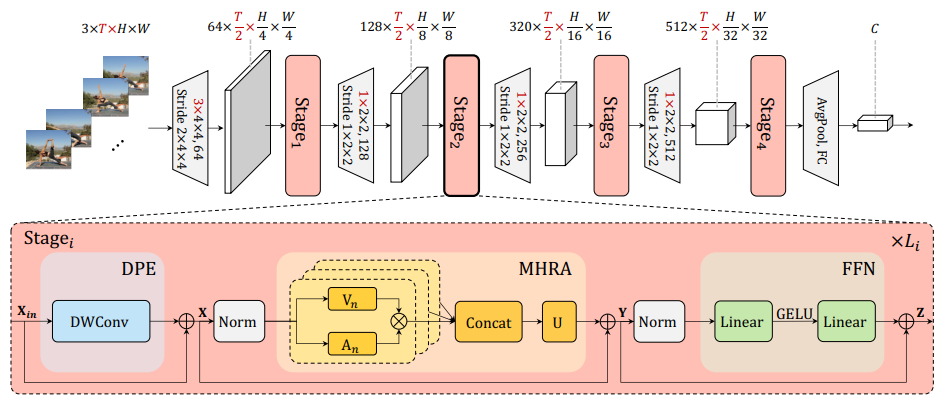
方法:论文提出了一种新颖的统一Transformer(UniFormer),它可以在简洁的Transformer格式中无缝整合卷积和自注意的优点。与典型的Transformer模块不同,UniFormer 模块中的关系聚合器在浅层和深层分别配备了局部和全局标记亲和力,从而可以同时解决冗余和依赖性问题,实现高效的表征学习。
创新点:
-
动态位置嵌入(Dynamic Position Embedding):该方法通过深度卷积和零填充的方式,灵活地将位置信息嵌入到Transformer中,以提高模型的灵活性和识别性能。
-
层级堆叠的UniFormer块:作者通过在不同阶段使用局部和全局UniFormer块的方式,逐步学习逐渐增长的视觉表示,以捕捉图像中的语义信息。
-
作者提出了一种关系聚合器设计,既能减少局部冗余又能学习全局依赖关系,通过将卷积和自注意力相结合,实现了高效而有效的特征学习。
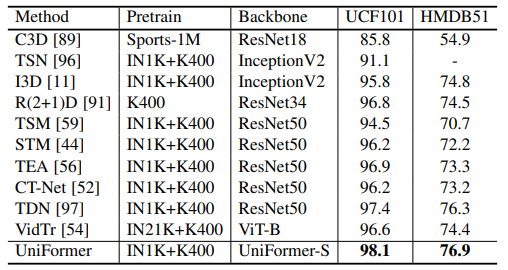
MixFormer: Mixing Features across Windows and Dimensions
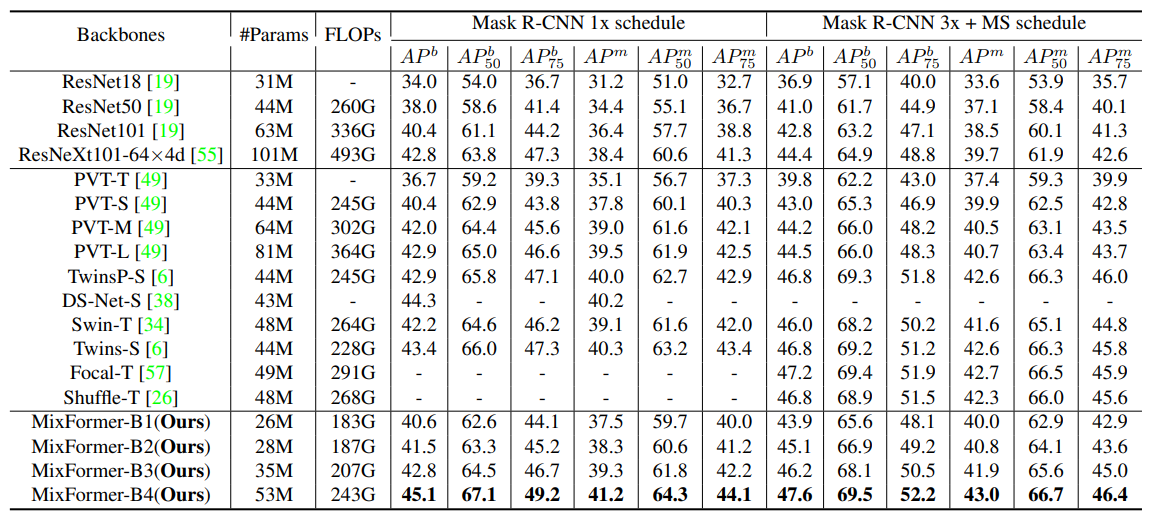
方法:本研究提出了MixFormer,针对局部窗口自注意力在视觉任务中存在的有限感受野和建模能力不足问题进行了解决。通过并行设计将局部窗口自注意力与深度卷积相结合,模拟窗口之间的连接以扩大感受野;同时,引入了双向交互设计,增强了通道和空间维度上的建模能力。

创新点:
-
并行设计:通过在不同的视觉任务中进行连续设计,验证了并行设计能够在特征表示学习方面取得更好的效果。
-
双向交互:引入了双向交互来增强通道和空间维度的建模能力。结果表明,通道交互和空间交互在所有不同的视觉任务中都优于没有交互的模型。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“自卷积”获取全部论文+代码
码字不易,欢迎大家点赞评论收藏
这篇关于自注意力与卷积高效融合!多SOTA、兼顾低成本与高性能的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


