本文主要是介绍跨语言翻译的突破:使用强化学习与人类反馈提升机器翻译质量,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在人工智能领域,知识问答系统的性能优化一直是研究者们关注的焦点。现有的系统通常面临知识更新频繁、检索成本高、以及用户提问多样性等挑战。尽管采用了如RAG(Retrieval-Augmented Generation)和微调等技术,但它们各有利弊,例如RAG在知识内容多的情况下检索成本高,而微调则面临算力成本高和训练效果不稳定的问题。
为了克服这些难题,研究者们开始探索使用强化学习与人类反馈(RLHF)的方法来进一步提升机器翻译和知识问答系统的质量。RLHF通过区分人类翻译和机器翻译的优劣,优化奖励模型,从而引导模型学习人类偏好的翻译质量。这种方法不仅能够有效提升翻译质量,而且改进可以惠及其他未经过RLHF训练的翻译方向。RLHF的优势在于其能够更好地利用人类反馈来调整和优化模型,使其更加符合人类的真实使用场景和偏好,这在传统的优化目标中往往难以实现。
为了构建一个符合人类翻译偏好的翻译模型,研究者首先使用一个通用的预训练语言模型πpre(例如LLaMA),然后遵循以下三个步骤的流程:1)在平行语料库上进行监督微调,得到具有基本翻译能力的模型πsft;2)在偏好数据集Drm上训练奖励模型r,该模型为符合人类偏好的翻译分配高奖励分数;3)使用r作为人类偏好的代理,通过强化学习提高模型的翻译质量。
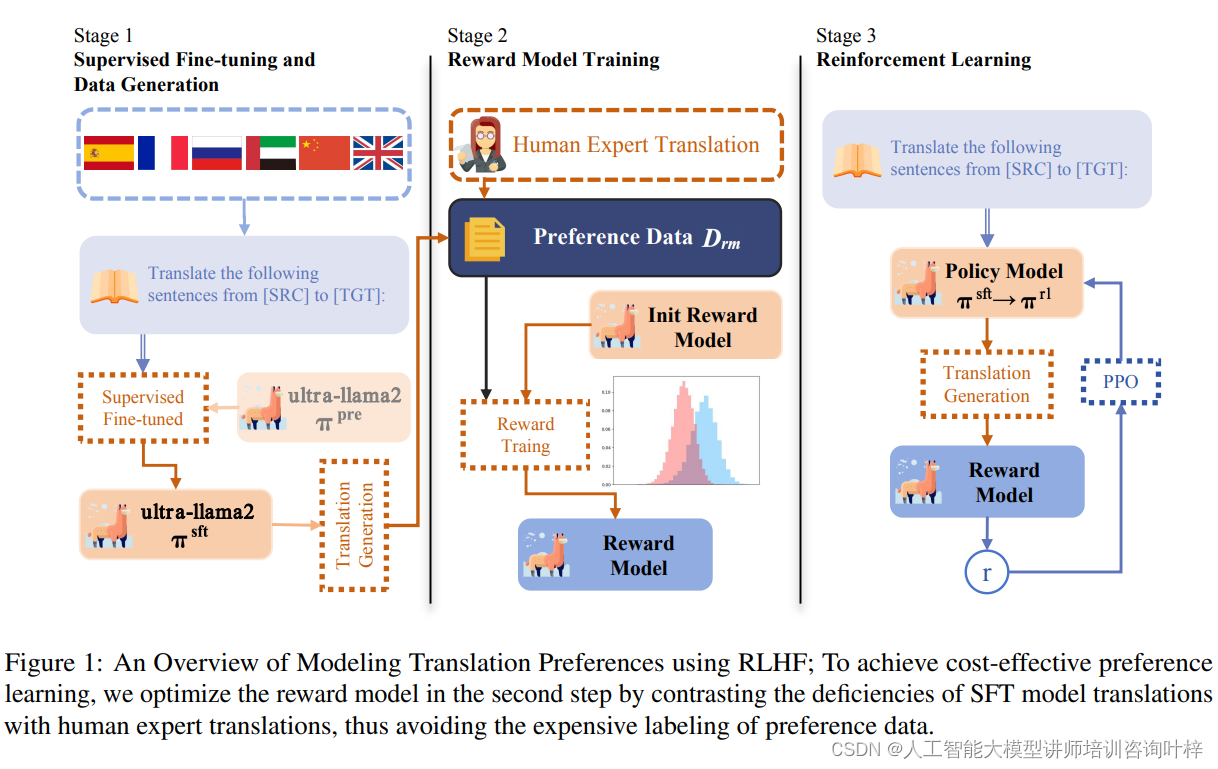
图1为使用强化学习与人类反馈(RLHF)建模翻译偏好的全面概览。在这个过程中,成本效益是一个关键考虑因素,尤其是在偏好学习阶段。为了实现这一点,研究者们在第二步中优化奖励模型,通过比较监督微调(Supervised Fine-tuning, SFT)模型生成的翻译与人类专家翻译之间的不足之处。
第一步,研究者们通过监督微调预训练语言模型来赋予其基本的翻译能力。这一步骤涉及到使用平行语料库,即包含源语言和对应目标语言翻译的句子对。通过最大化参考翻译的概率,模型学习将源语言文本映射到准确的目标语言翻译。这个过程通常涉及到固定提示模板的使用,以及对模型进行优化,使其能够生成与人类翻译高度相似的输出。
在模拟人类对翻译质量的偏好方面,研究者们面临着获取高质量偏好数据的挑战。为了解决这一问题,提出了一种成本效益高的偏好学习策略。该策略通过对比人类翻译和机器翻译的输出,训练一个奖励模型来识别和学习人类翻译的优势。这种方法避免了昂贵的偏好数据标注工作,同时使模型能够更好地捕捉到人类对翻译质量的细微差别。
在强化学习阶段,研究者们利用上一步骤中获得的奖励函数来为语言模型提供反馈。这一过程涉及到优化策略模型,使其在生成翻译时能够最大化奖励函数的输出。具体来说,模型在生成翻译的过程中,会考虑奖励模型提供的信号,从而生成更符合人类偏好的翻译。此外,为了保持生成多样性并避免模型输出过于单一,还会在优化过程中加入熵奖励等技术。
通过这三个步骤,RLHF方法能够有效地提升机器翻译的质量,使其更贴近人类翻译的自然流畅和准确性。这种方法不仅提高了翻译质量,还具有跨语言的迁移能力,为低资源语言的翻译质量提升提供了可能。
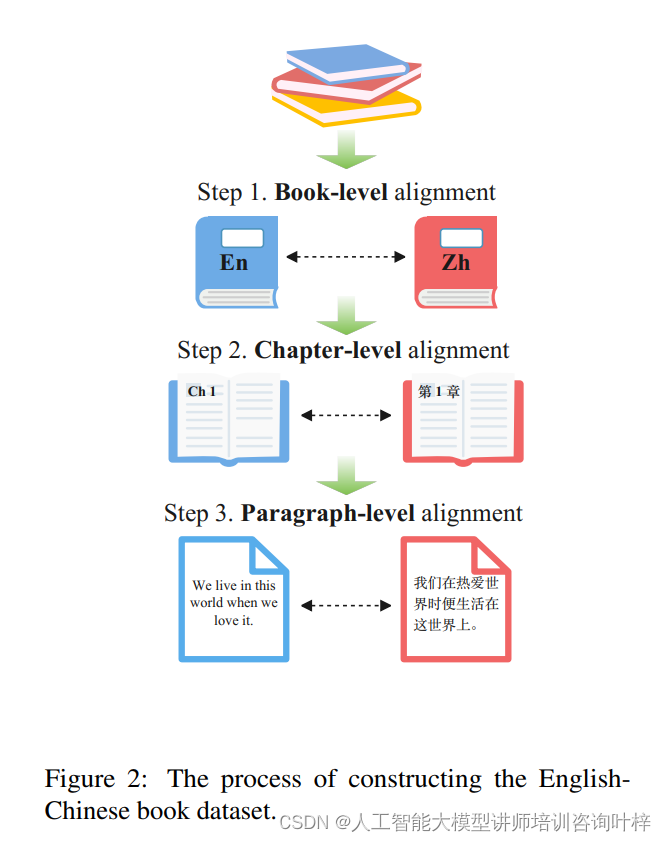
研究者们从多种渠道收集翻译训练数据,包括英汉书籍平行语料库、Yiyan语料库以及联合国平行语料库。这些数据经过精心筛选,确保了源语言和目标语言的文本质量,同时覆盖了丰富的语言现象和多样的领域知识。通过这些数据,模型能够学习到不同语境下的翻译模式。

在实验中,研究者们采用了两种基础模型:Ultra-LLaMA2-7B和LLaMA2-7B。Ultra-LLaMA2-7B是在超过200亿中文token上进一步预训练的LLaMA2-7B变体,它为实验提供了强大的语言理解能力。而LLaMA2-7B则是主要在英文上训练的大型语言模型,用作对照模型,以评估RLHF方法的效果。研究者采用了以下三种评估方法:
- GPT-4比较评估:利用GPT-4模型的先进能力,通过比较给定句子的原始文本和两种模型(SFT和RLHF)的翻译结果,选择更优秀的翻译。
- COMET指标:COMET是一个神经网络框架,用于训练多语言机器翻译评估模型。它与人类评估具有高相关性,被广泛用于机器翻译评估。
- 人类评估:由熟练的双语母语者进行评估,比较翻译质量,确保翻译的自然性和准确性。
为了全面评估模型性能,研究者们使用了WMT23测试集和Flores-200 dev-test集。WMT23测试集是机器翻译领域的标准测试集,而Flores-200 dev-test集则提供了额外的评估角度。这些测试集覆盖了多种语言对,允许研究者们评估模型在不同语言环境下的表现。
实验的主要结果显示,在没有明确偏好注释的情况下,通过对比机器翻译和人类翻译的不足,RLHF方法能够有效地模拟翻译偏好。在WMT23和FLORES数据集上,偏好优化模型相较于SFT模型展现出显著的改进。
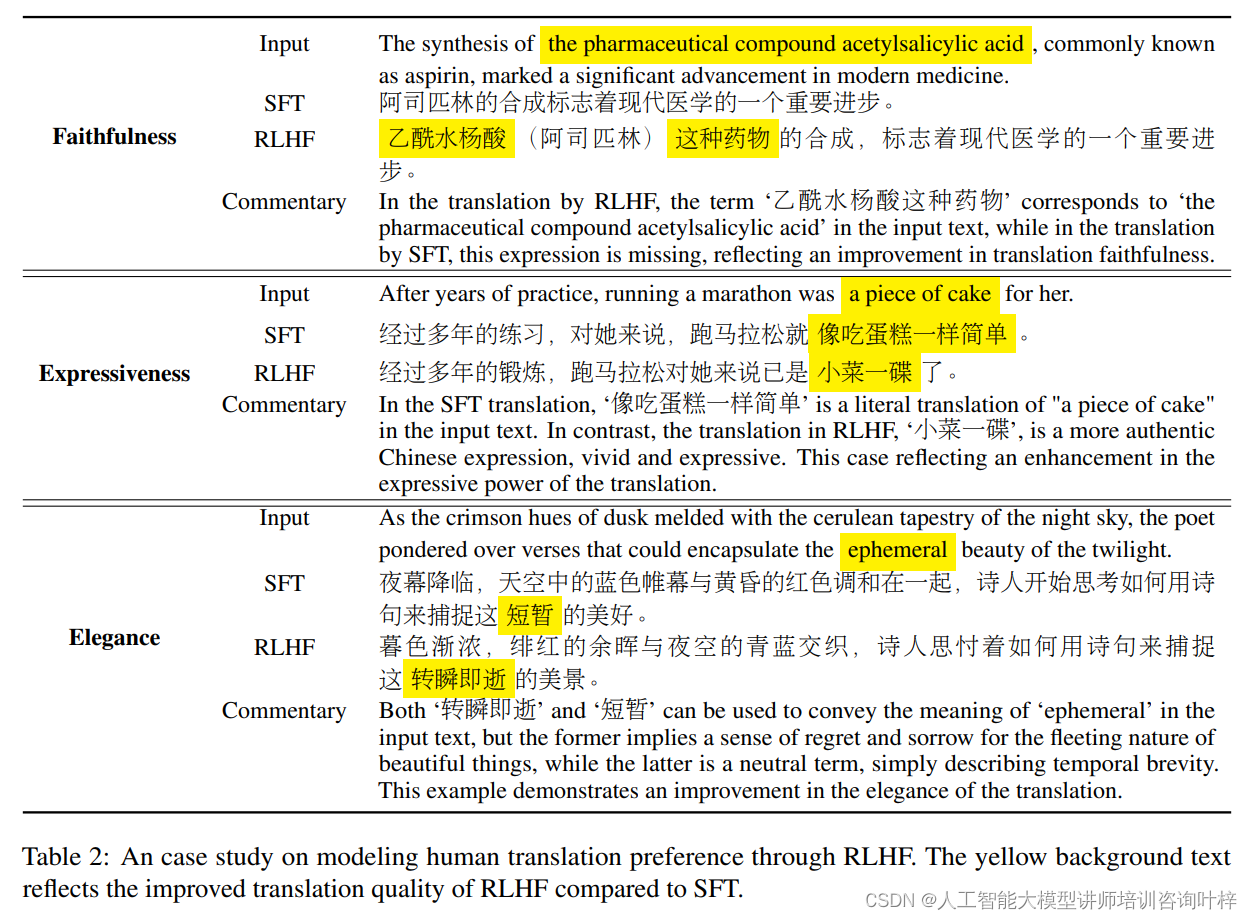
特定领域的数据集,如联合国语料库,可能在语言结构上不如书籍语料库复杂,这可能会降低偏好学习的效果。


实验还考察了学习到的翻译偏好是否能够跨语言转移。结果表明,RLHF方法学习到的偏好在一定程度上可以转移到其他语言对中,这为低资源语言的翻译质量提升提供了新的可能性。

实验结果表明,RLHF不仅能够有效地优化翻译模型,使其更贴近人类翻译的质量和风格,而且还能够实现跨语言的偏好迁移,为低资源语言的翻译质量提升开辟了新途径。本文的研究成果不仅对学术界具有重要意义,也为工业界提供了实用的技术参考。随着RLHF技术的不断成熟和应用,我们期待看到更多高质量的机器翻译产品问世,进一步促进全球化交流和合作。
这篇关于跨语言翻译的突破:使用强化学习与人类反馈提升机器翻译质量的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






