本文主要是介绍【数据挖掘】机器学习中相似性度量方法-余弦相似度,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
写在前面:
首先感谢兄弟们的订阅,让我有创作的动力,在创作过程我会尽最大能力,保证作品的质量,如果有问题,可以私信我,让我们携手共进,共创辉煌。
路虽远,行则将至;事虽难,做则必成。只要有愚公移山的志气、滴水穿石的毅力,脚踏实地,埋头苦干,积跬步以至千里,就一定能够把宏伟目标变为美好现实。
“相似性度量(similarity measurement)”系列文章:、
【数据挖掘】机器学习中相似性度量方法-欧式距离
Hello,大家好。
继续更新"相似性度量(similarity measurement)"系列文章,今天介绍的是余弦相似度。多的不说,少的不唠,下面开始今天的教程。
以下内容,完全是我根据参考资料和个人理解撰写出来的,不存在滥用原创的问题。

1、余弦相似度
余弦相似度(Cosine Similarity)是一种用于衡量两个非零向量之间角度 cosine 值的度量方法,以此来评估这两个向量在多维空间中的方向性相似度。它是通过计算两个向量的点积(内积)后,除以两个向量的模长(即长度)的乘积得到的。
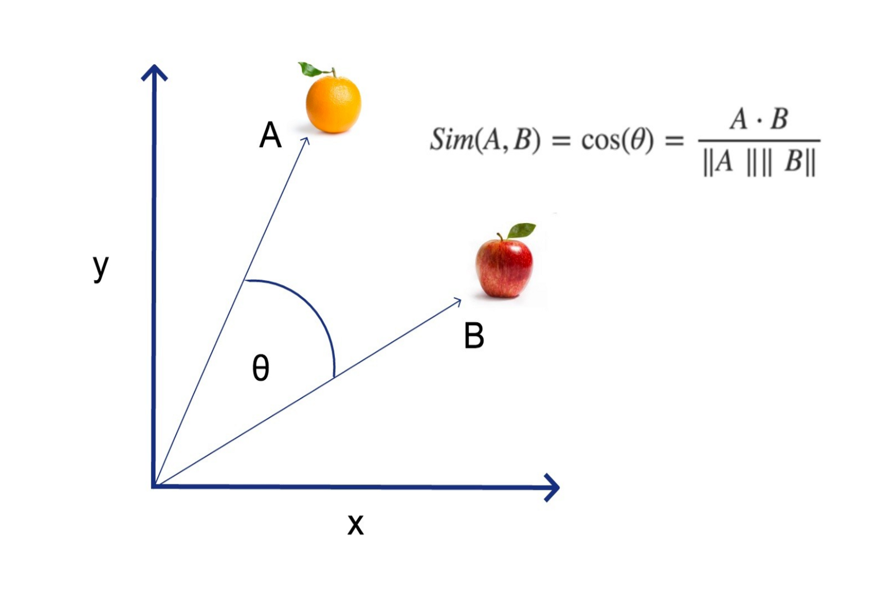
2、计算公式
数学上,对于向量A=[ x 1 , x 2 , . . . , x n x_ 1,x_ 2,...,x_ n x1,x2,...,xn]和向量B=[ y 1 , y 2 , . . . , y n y_ 1,y_ 2,...,y_ n y1,y2,...,yn],余弦相似度cos( θ \theta θ)定义为:
S i m ( A , B ) = cos ( θ ) = A ⋅ B ∥ A ∥ ∥ B ∥ = ∑ i = 1 n A i B i ∑ i = 1 n A i 2 ∑ i = 1 n B i 2 \ Sim(A,B)= \cos({\theta}) = \frac{\mathbf{A} \cdot \mathbf{B}}{\|\mathbf{A}\| \|\mathbf{B}\|} = \frac{\sum_{i=1}^{n} A_i B_i}{\sqrt{\sum_{i=1}^{n} A_i^2} \sqrt{\sum_{i=1}^{n} B_i^2}} Sim(A,B)=cos(θ)=∥A∥∥B∥A⋅B=∑i=1nAi2∑i=1nBi2∑i=1nAiBi
- A⋅B 表示向量 A 和向量 B 的点积
- ∥𝐴∥和 ∥B∥ 分别表示向量 A 和向量 B 的模(即长度)
- 𝜃是向量 A 和向量 B 之间的夹角
余弦相似度的值范围是 [-1, 1]:
- cos( θ \theta θ)=1,表示向量A和B方向完全相同
- cos( θ \theta θ)=-1,表示向量A和B方向完全相反
- cos( θ \theta θ)=0,表示向量A和B正交,没有任何方向上的相似性
3、余弦距离
余弦距离(Cosine Distance),从余弦相似度转换为距离概念,也是用来衡量两个向量间的相似性。余弦距离定义为:
d ( A , B ) = 1 − cos ( θ ) = 1 − A ⋅ B ∥ A ∥ ∥ B ∥ = 1 − ∑ i = 1 n A i B i ∑ i = 1 n A i 2 ∑ i = 1 n B i 2 \ d(A,B)= 1- \cos({\theta}) = 1- \frac{\mathbf{A} \cdot \mathbf{B}}{\|\mathbf{A}\| \|\mathbf{B}\|} = 1- \frac{\sum_{i=1}^{n} A_i B_i}{\sqrt{\sum_{i=1}^{n} A_i^2} \sqrt{\sum_{i=1}^{n} B_i^2}} d(A,B)=1−cos(θ)=1−∥A∥∥B∥A⋅B=1−∑i=1nAi2∑i=1nBi2∑i=1nAiBi
通过公式可以看到,余弦距离是由1减去余弦相似度得到的。
- 如果A和B两个向量完全相同,它们的余弦相似度是1,则余弦距离就是0,即A和B两个向量之间没有距离,完全一致
- 如果A和B两个向量完全相反,它们的余弦相似度是-1,则余弦距离就是2,即A和B两个向量之间距离最大
4、代码实现
编写代码实现余弦相似度或余弦距离,在Python中,可以使用numpy、scipy或者sklearn来计算两个向量之间的余弦相似度或余弦距离:
# -*- coding: utf-8 -*-
"""
Created on Fri Jun 14 22:36:45 2024@author: AIexplore微信公众号
"""import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
from scipy.spatial.distance import cosineimport numpy as npdef cosine_similarity_v1(vector_a, vector_b):"""计算两个向量的余弦相似度。参数:vector_a -- 第一个向量,类型为NumPy数组或列表vector_b -- 第二个向量,类型为NumPy数组或列表返回:两个向量的余弦相似度"""# 将输入转换为NumPy数组(如果还不是的话)vector_a = np.array(vector_a)vector_b = np.array(vector_b)# 计算向量的点积dot_product = np.dot(vector_a, vector_b)# 计算向量的模长(欧几里得范数)norm_a = np.linalg.norm(vector_a)norm_b = np.linalg.norm(vector_b)# 防止除以零的错误if norm_a == 0 or norm_b == 0:return 0 # 如果任一向量为空,则认为相似度为0# 计算并返回余弦相似度return dot_product / (norm_a * norm_b)def cosine_similarity_v2(vec1, vec2):vec1 = np.array(vec1)vec2 = np.array(vec2)# 计算余弦相似度cos_sim = 1 - cosine(vec1, vec2) # cosine函数直接返回的是距离,所以用1减去得到相似度return cos_simdef cosine_similarity_v3(vec1, vec2):vec1 = np.array([vec1])vec2 = np.array([vec2])sim = cosine_similarity(vec1, vec2)return sim[0][0]# data
vec1 = [1, 2, 3]
vec2 = [4, 5, 6]# 计算相似度
similarity = cosine_similarity_v1(vec1, vec2)
print("余弦相似度 v1:", similarity)similarity = cosine_similarity_v2(vec1, vec2)
print("余弦相似度 v2:", similarity)similarity = cosine_similarity_v3(vec1, vec2)
print("余弦相似度 v3:", similarity)
输出结果:
余弦相似度 v1: 0.9746318461970762
余弦相似度 v2: 0.9746318461970761
余弦相似度 v3: 0.9746318461970762
上面代码提供了三种实现方式,殊途同归,根据需要选择性使用。
5、应用场景
余弦相似度因其特性在多个领域和应用场景中扮演着重要角色,下面列举一些典型的应用场景:
- 推荐系统:在电商、短视频、音乐平台等推荐系统中,通过计算用户历史偏好向量(基于用户对项目的评分或互动)和待推荐项目特征向量之间的余弦相似度,可以发现与用户兴趣最为接近的项目,从而实现个性化推荐
- 图像识别与检索:在计算机视觉CV领域,将图像特征(如通过深度学习模型提取的特征向量等)映射到高维空间,利用余弦相似度来比较不同图像间的相似度,可以实现图像检索、图像分类以及内容相似的图像分组
- 聚类分析:在无监督学习的聚类任务中,余弦相似度可用作距离度量,帮助将具有较高相似性的数据点聚集在一起,形成有意义的簇
当然,还可以应用到文本相似性判断、信息检索、社交网络分析、文本分类、用户行为分析等。
参考文章
[1]https://www.cnblogs.com/BlogNetSpace/p/18225493
[2]https://blog.csdn.net/Hyman_Qiu/article/details/137743190
[3]https://blog.csdn.net/qq_39780701/article/details/137007729
[4]https://www.cnblogs.com/ghj1976/p/yu-xian-xiang-shi-ducosine-similarity-xiang-guan-j.html
写在最后
作者介绍:CSDN人工智能领域优质创作者,CSDN博客专家,阿里云专家博主,阿里云技术博主,有机器学习、深度学习、OCR识别项目4年以上工作经验,专注于人工智能技术领域。会根据实际项目不定期输出一些非商业的技术,内容不限,欢迎各位朋友关注。
1、关注下方公众号,让我们共同进步。
2、需要技术指导、交流合作,点击"关于我-与我联系"添加微信交流。

这篇关于【数据挖掘】机器学习中相似性度量方法-余弦相似度的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




