本文主要是介绍SQLServer使用 PIVOT 和 UNPIVOT行列转换,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在SQL Server中,PIVOT是一个用于将行数据转换为列数据的操作。它特别适用于将多个行中的值转换为多个列的情况,并在此过程中执行聚合操作。以下是关于SQL Server中PIVOT操作的详细解释和示例:
1、本文内容
- 概述
- 语法
- 备注
- 关键点
- 简单 PIVOT 示例
适用于:
- SQL Server
- Azure SQL 数据库
- Azure SQL 托管实例
- Azure Synapse Analytics
- Analytics Platform System (PDW)
可以使用 PIVOT 和 UNPIVOT 关系运算符将表值表达式更改为另一个表。 PIVOT 通过将表达式中的一个列的唯一值转换为输出中的多列,来轮替表值表达式。 PIVOT 在需要对最终输出所需的所有剩余列值执行聚合时运行聚合。 与 PIVOT 执行的操作相反,UNPIVOT 将表值表达式的列轮换为列值。
PIVOT 的语法比一系列复杂的 SELECT…CASE 语句中所指定的语法更简单和更具可读性。
有关 PIVOT 语法的完整说明,请参阅 FROM (Transact-SQL)。
https://learn.microsoft.com/en-us/sql/t-sql/queries/from-using-pivot-and-unpivot?view=sql-server-ver16
https://learn.microsoft.com/en-us/sql/t-sql/queries/from-transact-sql?view=sql-server-ver16
2、PIVOT概述
- 目的:将列值旋转为列名(即行转列),并在必要时对最终输出中所需的任何其余列值执行聚合。
- 使用场景:当需要从多行数据中提取特定列的唯一值,并将这些值转换为列标题时。
3、语法
SELECT <non-pivoted column>, -- [非透视的列],[first pivoted column] AS <column name>, -- [第一个透视的列] AS [列名称1][second pivoted column] AS <column name>, -- [第二个透视的列] AS [列名称2] ... [last pivoted column] AS <column name> -- [最后一个透视的列] AS [列名称N]
FROM (<SELECT query that produces the data>) AS <alias for the source query>
PIVOT
( <aggregation function>(<column being aggregated>) -- [聚合函数]([要聚合的列])
FOR
[<column that contains the values that will become column headers>] -- [<包含要成为列标题的值的列>]IN ( [first pivoted column], [second pivoted column], ... [last pivoted column]) -- [第一个透视的列], [第二个透视的列], ... [最后一个透视的列]
) AS <alias for the pivot table>
<optional ORDER BY clause>;
4、备注
UNPIVOT 子句中的列标识符需遵循目录排序规则。 对于 SQL 数据库,排序规则始终是 SQL_Latin1_General_CP1_CI_AS。 对于 SQL Server 部分包含的数据库,排序规则始终是 Latin1_General_100_CI_AS_KS_WS_SC。 如果将该列与与其他列合并,则需要 collate 子句 (COLLATE DATABASE_DEFAULT) 以避免冲突。
在 Microsoft Fabric 和 Azure Synapse Analytics 池中,如果 PIVOT 输出的非 pivot 列上存在 GROUP BY,则 PIVOT 运算符的查询将失败。 解决方法是从 GROUP BY 中删除非 pivot 列。 查询结果是相同的,因为此 GROUP BY 子句是重复的。
5、关键点
- PIVOT必须列举值:在PIVOT操作中,必须明确列举出要转换为列标题的值。这些值将作为新表的字段名称。
- 聚合函数:PIVOT操作中通常需要使用聚合函数(如SUM、AVG、MAX、MIN等)对数据进行聚合。虽然语法中没有明确显示GROUP BY子句,但PIVOT实际上是隐式地对数据进行分组和聚合的。
- 处理空值:如果在原始表中某个分组没有对应的数据,那么PIVOT后的新表中该分组对应的列将以NULL值存在。
- 与UNPIVOT的关系:PIVOT和UNPIVOT是相反的操作。UNPIVOT将列转换为列值,而PIVOT则将列值转换为列。
6、简单 PIVOT 示例
示例表信息,显示2024年每月的V-CUT和UV固化,背钻流程工步的过账面积
select * from t_PassOver_pivot
goPassOver_Month OutTechNo TechName OutQty_Area
-------------- --------- ------------------------------ ----------------------
2024-02 1803 V-CUT 454.96
2024-03 1803 V-CUT 1054.38
2024-04 1803 V-CUT 1139
2024-01 1803 V-CUT 891.28
2024-05 1803 V-CUT 1248.33
2024-02 1610 UV固化 2881.89
2024-01 1610 UV固化 4281.75
2024-04 1610 UV固化 4832.2
2024-03 1610 UV固化 5430.31
2024-05 1610 UV固化 4840.63
2024-01 1715 背钻 1807.23
2024-05 1715 背钻 1406.53
但是 1715 背钻 没有 2024-02,2024-03,2024-04 3月的过账面积。
以下代码显示相同的结果,该结果经过透视以使 PassOver_Month 过账月份值成为列标题。
SELECT OutTechNo,TechName,[2024-01] AS Month_202401,[2024-02] AS Month_202402,[2024-03] AS Month_202403,[2024-04] AS Month_202404,[2024-05] AS Month_202405FROM t_PassOver_pivot /*数据源*/
AS P
PIVOT
(SUM(OutQty_Area/*行转列后 列的值*/) FOR p.PassOver_Month/*需要行转列的列*/ IN ([2024-01],[2024-02],[2024-03],[2024-04],[2024-05]/*列的值*/)
) AS T
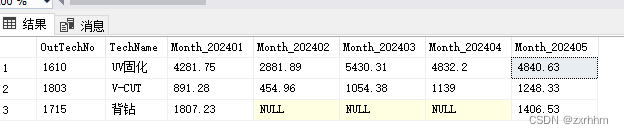
提供个五列表示2024年前五个月份,因1715 背钻流程工步 没有 2024-02,2024-03,2024-04 3月的过账面积,即使结果为 NULL。
- 重要提示
如果聚合函数与 PIVOT 一起使用,则计算聚合时将不考虑出现在值列中的任何空值
7、UNPIVOT
UNPIVOT 逆透视示例
与 PIVOT 执行的操作几乎相反,UNPIVOT将列转换为列值即多列转换为一列,而PIVOT则将列值转换为列即一列的多行数据转为多列。
select * from t_PassOver_unpivot
数据表t_PassOver_unpivot如下信息
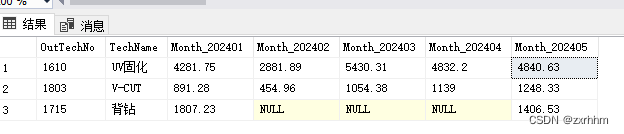
SELECT PassOver_Month,OutTechNo,TechName,OutQty_Area
FROM (SELECT OutTechNo,TechName,Month_202401, Month_202402,Month_202403,Month_202404,Month_202405FROM t_PassOver_unpivot) p
UNPIVOT (OutQty_Area FOR PassOver_Month IN (Month_202401, Month_202402,Month_202403,Month_202404,Month_202405)
)AS unpvt;
GO 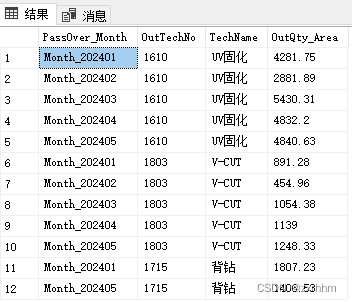
请注意,UNPIVOT 并不完全是 PIVOT 的逆操作。 PIVOT 执行聚合,并将多个可能的行合并为输出中的一行。 UNPIVOT 不重现原始表值表达式的结果,因为行已被合并。
另外,UNPIVOT 输入中的 NULL 值也在输出中消失了。 如果值消失,表明在执行 PIVOT 操作前,输入中可能就已存在原始 NULL 值。
这篇关于SQLServer使用 PIVOT 和 UNPIVOT行列转换的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





