本文主要是介绍【SQLAlChemy】表之间的关系,外键如何使用?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
表之间的关系
数据库表之间的关系分为三种:
- 一对一关系(One-to-One):在这种关系中,表A的每一行都与表B的一行关联,反之亦然。例如,每个人都有一个唯一的社保号,每个社保号也只属于一个人。
- 一对多关系(One-to-Many):在这种关系中,表A的一行可以与表B的多行关联,但表B的每一行只能与表A的一行关联。例如,一位母亲可以有多个孩子,但每个孩子只能有一个生物学上的母亲。
- 多对多关系(Many-to-Many):在这种关系中,表A的一行可以与表B的多行关联,表B的一行也可以与表A的多行关联。例如,一个学生可以选修多门课程,一门课程也可以被多个学生选修。
在数据库中,这些关系通常通过使用外键(Foreign Key)来建立。
外键
外键(Foreign Key)是一种特殊类型的数据库约束,主要用于创建表之间的链接或关系。
外键是在一个表中创建的,它是另一个表的主键(Primary Key)。这个外键用来指向另一个表的主键,从而建立两个表之间的关系。
外键的主要目的是维护数据的引用完整性。这意味着,如果试图在一个表中插入一行,而这行数据的外键值在相关表中不存在,数据库将不允许这个操作。同样,如果试图删除一个表中的行,而这行数据的主键在其他表中作为外键存在,那么数据库也不会允许这个删除操作,除非先删除或更改引用这个主键的所有外键。
例如,假设有两个表,一个是学生表,一个是课程表。每个学生可以注册多个课程,所以在课程表中,可能会有一个列叫做 "student_id",这个列是学生表的外键。这样,就可以通过学生的 ID 查询他们注册的所有课程,同时也保证了每个课程都有一个注册的学生。
使用 SQLAlchemy 创建外键的步骤:
- 定义表格:首先,需要定义数据库表格。每个表格对应一个 SQLAlchemy 类,类中的每个属性对应表格中的一个列。
- 设置外键:在定义表格的过程中,可以使用
ForeignKey函数来设置外键。ForeignKey函数的参数是想要链接的表格的列名。例如,如果有一个Order表,想让它链接到Customer表的id列,可以这样写:customer_id = Column(Integer, ForeignKey('customer.id'))。 - 创建关系:在设置了外键之后,还需要在 SQLAlchemy 类中使用
relationship函数来创建两个表格之间的关系。例如,可以在Customer类中添加如下的代码:orders = relationship("Order", backref="customer")。 这段代码表示一个客户可以有多个订单,每个订单都有一个关联的客户。 - 创建数据库:最后,需要使用 SQLAlchemy 的
create_all函数来创建数据库。这个函数会根据定义的 SQLAlchemy 类来创建表格,并设置好所有的外键和关系。
实例
实现学生 Student 与 Lesson 之间的关系表的建立。
python 代码:
Base = declarative_base()# 定义 Student 表
class Student(Base):__tablename__ = 'student'id = Column(Integer, primary_key=True)name = Column(String(50), nullable=False)age = Column(Integer)def __repr__(self):return "<Student(name='%s', age='%s')>" % (self.name, self.age)# 定义 Lesson 表
class Lesson(Base):__tablename__ = 'lesson'id = Column(Integer, primary_key=True)name = Column(String(50), nullable=False)description = Column(String(100), nullable=False)student_id = Column(Integer, ForeignKey('student.id'))def __repr__(self):return "<Lesson(name='%s', description='%s')>" % (self.name, self.description)Base.metadata.create_all(engine)
sql语句代码:
create table student
(id int auto_incrementprimary key,name varchar(50) not null,age int null
);create table lesson
(id int auto_incrementprimary key,name varchar(50) not null,description varchar(100) not null,student_id int null,constraint lesson_ibfk_1foreign key (student_id) references student (id)
);create index student_idon lesson (student_id);
表关系图:
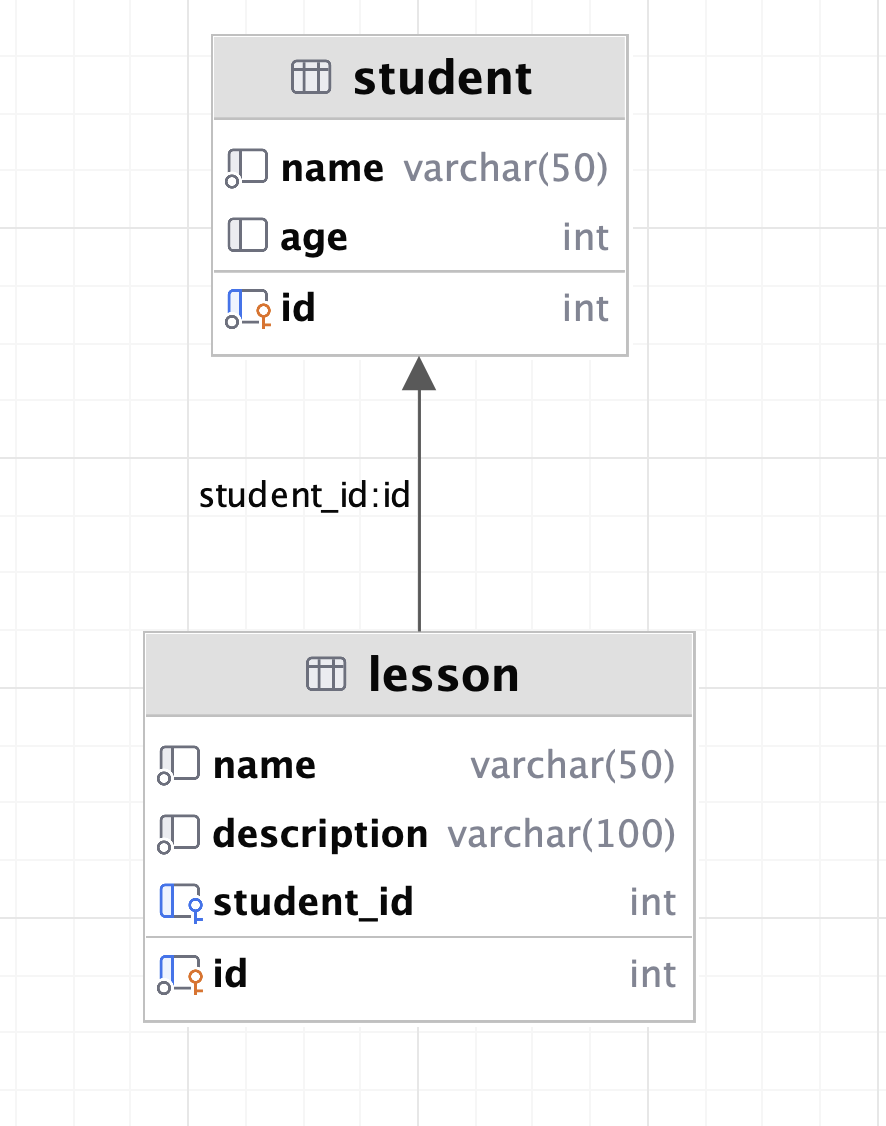
测试插入数据:
# 测试插入数据# Student 数据
stu1 = Student(name='zmz', age=10)
stu2 = Student(name='ypb', age=18)
stu3 = Student(name='gll', age=20)session.add_all([stu1, stu2, stu3])
session.commit()# Lesson 数据
l1 = Lesson(name='java', description='this is java', student_id=stu1.id)
l2 = Lesson(name='java', description='this is java', student_id=stu2.id)
l3 = Lesson(name='python', description='this is python', student_id=stu1.id)
session.add_all([l1, l2, l3])
session.commit()
数据库 student 表:

数据库 lesson 表:

外键约束分类
- RESTRICT:这是默认选项。当尝试删除父表中的数据时,如果子表中存在与之关联的数据,那么这个删除操作将会被阻止。也就是说,只有当没有任何子表行与父表行关联时,才能删除父表中的行。
- NO ACTION:在 MySQL 中,这个选项的行为与 RESTRICT 选项相同。也就是说,如果子表中存在与父表行关联的行,那么尝试删除父表中的行将会被阻止。
- CASCADE:这个选项表示级联删除。当你删除父表中的行时,所有在子表中与之关联的行也会被自动删除。这种选项需要谨慎使用,因为它可能会导致大量的数据被删除。
- SET NULL:当父表中的行被删除时,这个选项会将子表中所有与之关联的行的外键列设置为 NULL。这意味着,子表中的这些行不再与父表中的任何行关联。注意,为了使用这个选项,子表的外键列必须允许 NULL 值。
修改 lesson 表:
# 定义 Lesson 表
class Lesson(Base):__tablename__ = 'lesson'id = Column(Integer, primary_key=True)name = Column(String(50), nullable=False)description = Column(String(100), nullable=False)student_id = Column(Integer, ForeignKey('student.id', ondelete='CASCADE'), nullable=False)def __repr__(self):return "<Lesson(name='%s', description='%s')>" % (self.name, self.description)
注意事项
问题:
加入在添加数据时,我们先提交了 student 中的数据,之后在提交了 lesson 中的数据,会造成 lesson 中 student_id 为空。
分析:
在 SQLAlchemy 中,当使用 session.add() 方法时,数据并不会立即被写入数据库,而是被添加到了会话的事务队列中。只有当调用 session.commit() 方法时,才会将这些变更写入数据库。在这之前,新创建的 Student 对象的 id 属性是 None,因为它们还没有被分配数据库中的 id。
在代码中,首先创建了几个 Student 对象,并使用 session.add_all() 添加到会话中,但是在添加 Lesson 对象之前,没有调用 session.commit()。因此,当试图访问 stu1.id 时,它其实是 None,这就是为什么在插入 Lesson 数据时会出现错误。
为了解决这个问题,需要在添加 Lesson 对象之前,先提交 Student 对象。
这篇关于【SQLAlChemy】表之间的关系,外键如何使用?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






