本文主要是介绍如何轻松利用人工智能深度学习,提升半导体制造过程中的良率预测?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
背景
这个项目涉及半导体制造过程的监测领域。在半导体制造中,不断收集来自传感器或过程测量点的信号是常态。然而,并非所有这些信号在特定的监测系统中都同等重要。这些信号包括了有用的信息、无关的信息以及噪声。通常情况下,工程师获得的信号数量远远超过实际需要的数量。因此,需要进行特征选择,以找出最具相关性的信号,使工程师能够确定对产品良率产生影响的关键因素。这一过程有助于提高生产效率、缩短学习时间,并降低单位生产成本。
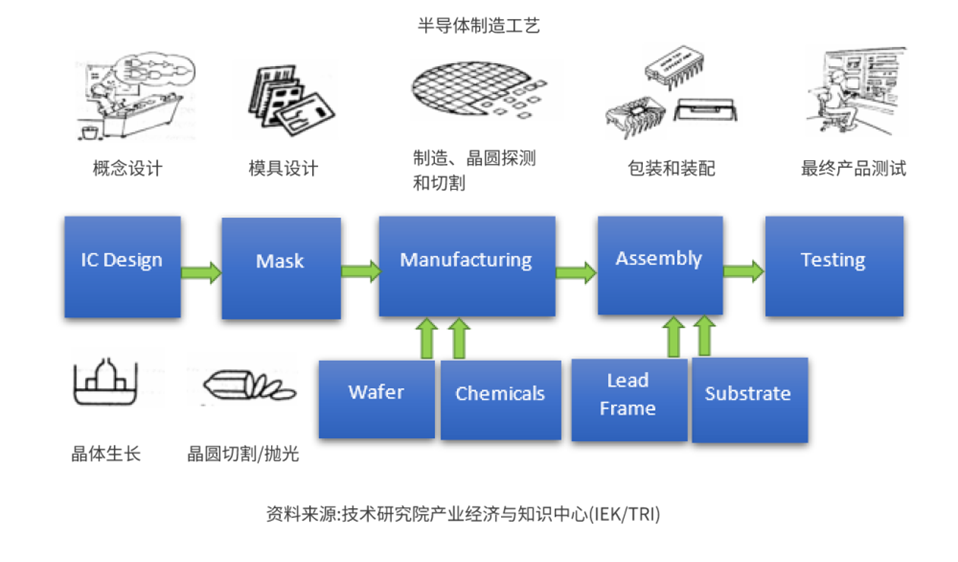
目标
项目的目标是构建一个分类器,用于预测特定过程实体的“通过/不通过”产品良率,并分析是否需要所有特征来构建模型。通过分析和尝试不同的特征组合,可以识别影响产品良率的关键信号。
数据集
项目使用名为 "sensor-data.csv" 的数据集,包含1567个样本,每个样本有591个特征(不包含日期和索引)。每个样本代表一个生产实体,具有关联的测量特征,并且标签表示内部线路测试的通过/不通过产品良率。数据集中的目标列 "Pass" 对应于通过,"Fail" 对应于不通过。
项目的步骤:
1. 导入CSV数据。
2. 检查数据的观察值和形状,检查是否存在缺失值,如果有则进行缺失值处理。
3. 检查多重共线性,并丢弃不相关的列。
4. 对数据进行标准化并进行建模。
5. 将依赖列("Pass/Fail")与数据分离,并将数据集拆分为训练集和测试集(70:30的比例)。
6. 应用采样技术以处理类别不平衡问题。
7. 构建深度学习分类器模型,并打印测试数据的混淆矩阵。
8. PCA降维后重复步骤7。
9. 结论
数据科学
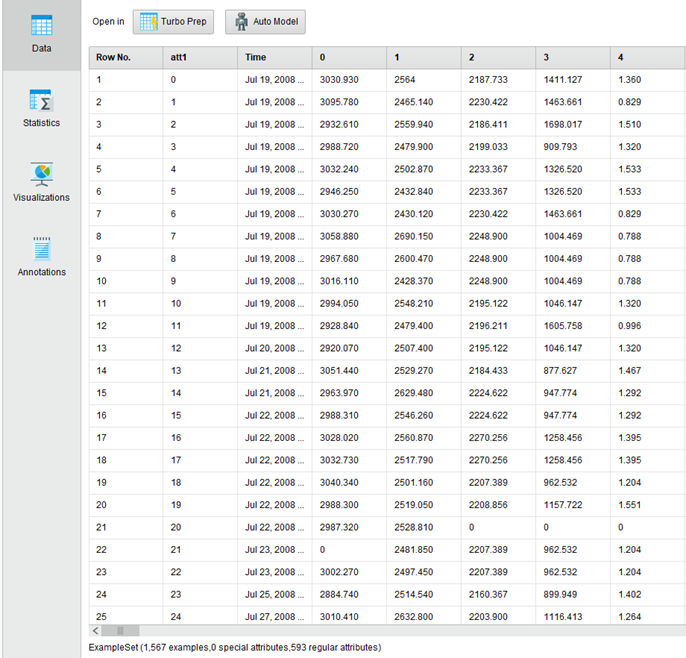
首先使用RapidMiner导入变量,并进行简单的描述性统计,可以看到数据的条数和变量。
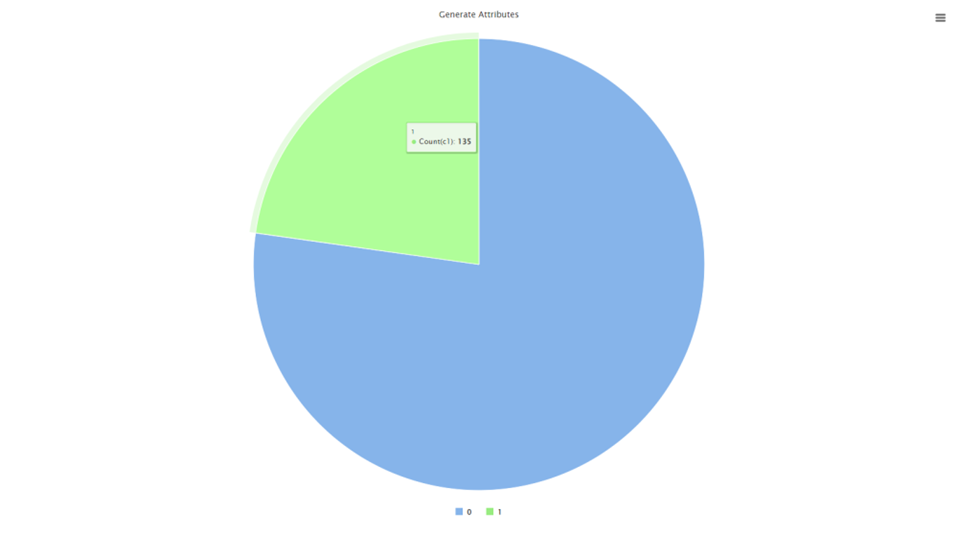
然后做一下数据的质量检验,尤其是稳定性的问题,这里我们把稳定性超过80%的数据给筛选出来,不难从下图中看出来,接近23%的数据存在稳定性过高的问题,直接在数据准备中把稳定性过高的数据进行删除。
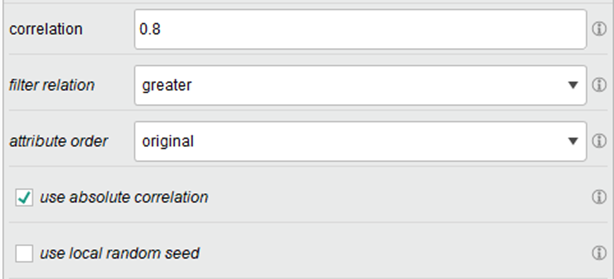
同时把删除后的变量进行多重共线性检验。在RapidMiner这种我们使用“Remove Correlated Attributes”算子查找相关性超过0.8的变量并进行删除。
并使用“Normalize”算子对自变量进行了标准化处理。
删除前的变量为461个(过滤掉稳定性过高的),删除后剩余216个。
A:为什么要做多重共线性检验?为何要剔除稳定性过高的变量?
Q:多重共线性检验的主要目的是识别自变量之间的高度相关性,并采取适当的措施来解决这些问题。剔除稳定性过高的变量是解决多重共线性的一种方法,因为它有助于降低模型的复杂性和提高模型的解释性。
通过剔除高度相关的变量,可以减少模型中的冗余信息,使模型更加稳定,并更容易理解和解释。
接下来我们查看一下我们的分类变量,可以看到原始数据集中,Fail和Pass的比例大概是1:10。
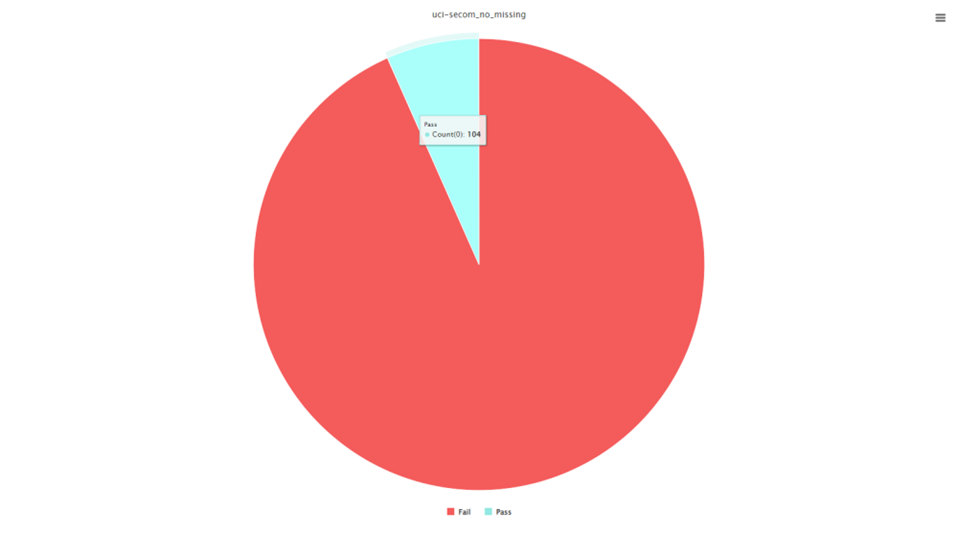
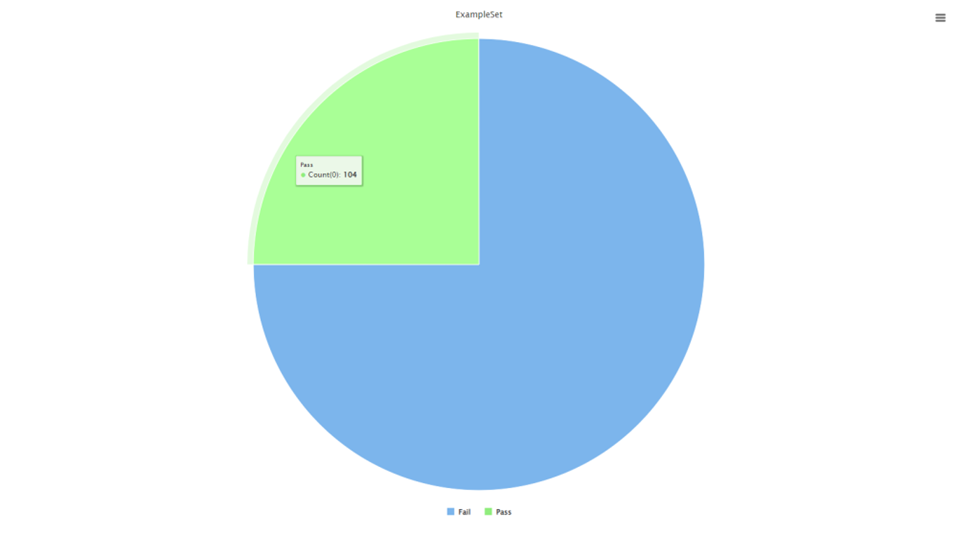
目前的数据存在极度不平衡的。所以我们需要进行欠采样。
Q:什么是欠采样?
A:欠采样是减少多数类别样本的方法,以使其与少数类别样本数量相匹配。
当我们观察到"Pass"类别只有104个样本时,为了更好地进行机器学习建模,我们希望实现一个更平衡的分类比例,1:2或者1:3,这意味着104个"Pass"样本需要对应312个"Fail"样本。
接下来使用深度学习建模。
Q:什么是深度学习?
A:深度学习是一种机器学习方法,它试图模拟人脑神经网络的工作方式来处理和理解复杂的数据。它的核心思想是构建深层神经网络,这些网络由多层神经元组成,每一层都对数据进行不同层次的特征提取和抽象表示,最终实现高级的模式识别和决策。
深度学习的关键特点包括:
1. 深层结构:深度学习模型通常包括多个隐藏层,允许它们学习数据的多层次表示。这使得它们能够捕获数据中的复杂关系。
2. 神经网络:深度学习使用人工神经网络模拟生物神经元之间的连接。神经元之间的权重和激活函数通过训练来调整,以最大程度地减小预测误差。
3. 大规模数据:深度学习模型通常需要大规模的数据集进行训练,以获得高性能。这有助于模型学习数据的广泛分布和复杂模式。
4. 端到端学习:深度学习模型可以直接从原始数据中学习特征表示,而不需要手动提取特征。这使得模型的构建更加自动化和通用。
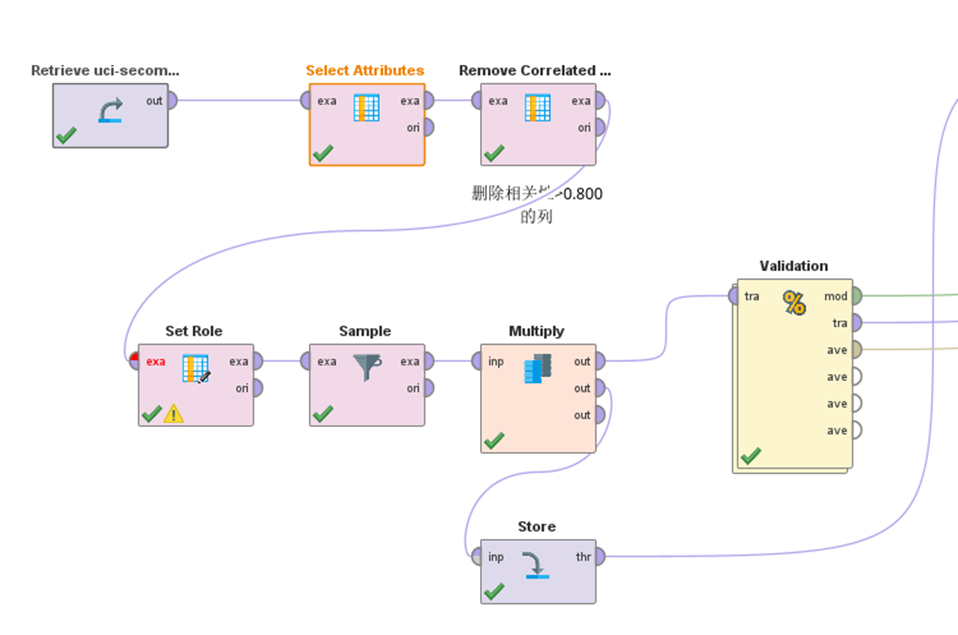
通过构建模型后可以看到准确率为76.8%。但是从混淆矩阵上来看,实际为Pass的有很大一部分被预测成了Fail,出现了假阴性率。

如果接下来使用PCA降维,我们查看一下PCA是否有助于改善模型性能。
Q:什么是PCA(主成分分析)?
A:PCA(Principal Component Analysis,主成分分析)是一种常用于数据降维和特征选择的数学方法。它的主要目标是通过线性变换将原始数据转换成一组新的不相关特征,这些新特征被称为主成分,以便降低数据的维度,同时保留尽可能多的信息。
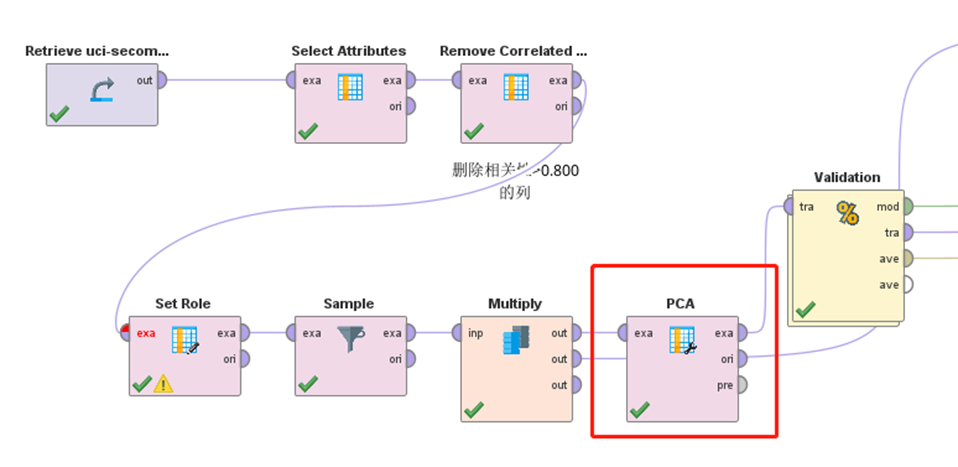
我加了一个PCA,保留了95%的主成分。通过降维找到了129个变量。

但是模型并没有更改多少,所以本质上可能是标签不准确造成的。但是从分析中不难发现。146、91、224、218和139对于Pass/Fail是影响最大的,我们可以着重的关注一下这几个变量。

结论
在本次研究中,我们探讨了使用RapidMiner进行半导体制造过程中产品良率预测的易用性和可解释性。通过对半导体制造过程的数据进行分析和建模,我们得出以下结论:
首先,RapidMiner提供了强大的数据预处理和特征选择功能,使我们能够有效地处理复杂的半导体制造数据。其直观的用户界面和丰富的工具库使数据科学家能够轻松地导入、清理和准备数据,从而为建模工作奠定了坚实的基础。
其次,RapidMiner在建模方面表现出色。我们使用了深度学习模型(有更多可以选择),通过RapidMiner轻松构建了这些模型。通过调整模型参数和应用采样技术,我们成功地提高了产品良率的预测准确性。RapidMiner的模型评估功能还允许我们深入分析模型性能,包括混淆矩阵和特征重要性。
最重要的是,RapidMiner提供了模型可解释性的工具。我们能够轻松地理解模型对产品良率的预测依据,识别了对产品良率产生重大影响的关键特征。这有助于制造工程师更好地理解制造过程中的关键因素,并采取相应的措施来提高产品良率。
综上所述,RapidMiner在半导体制造过程中产品良率预测方面表现出色,具有良好的易用性和可解释性,为制造行业提供了有力的数据分析和建模工具。它有助于提高生产效率、降低成本,并提高产品质量,对于半导体制造企业来说是一项强大的工具。
若您对数据分析以及人工智能感兴趣,欢迎与我们一起站在全球视野关注人工智能的发展,与Forrester 、德勤、麦肯锡等全球知名企业共探AI如何加速工业变革,共享众多优秀行业案例,开启AI人工智能全球新视野!!
共同参与6月20日由Altair主办的面向工程师的全球线上人工智能会议“AI for Engineers”。
点击立即免费报名
(注:现在注册参会,即可于会后第一时间获得Altair全球100个客户案例资料)
关于 Altair RapidMiner
Altair RapidMiner 数据分析与人工智能平台,是 Altair 澳汰尔公司旗下仿真、HPC 和数据分析三块主营业务中的解决方案,它在数据分析领域最早实现将自动化数据科学、文本分析、自动特征工程和深度学习等多种功能同时集成的一站式数据分析平台,帮助用户解决从数据清洗、准备、数据科学建模到模型管理和部署,同时又支持数据和流数据的实时分析可视化的数据分析平台。
欲了解更多信息,欢迎关注公众号:Altair RapidMiner
这篇关于如何轻松利用人工智能深度学习,提升半导体制造过程中的良率预测?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






