本文主要是介绍使用超声波麦克风阵列预测数控机床刀具磨损,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
预测性维护是使用传感器数据来推断机器状态,并从这些传感器数据中检测出在故障发生之前存在的缺陷或故障的过程。预测性维护在所有工业领域都是一种日益增长的趋势,包括轴承故障检测、齿轮磨损检测或往复式机器中的活塞磨损等许多其他例子。在预测性维护领域,应用了大量传感器,包括声学、振动、热传感器、电流传感器以及几乎可以想象的任何其他传感模式。
在数控车床中,工件被安装在一个主轴上,然后主轴旋转,而切削则通过一个静止的切削工具来执行。切削工具的几何形状和材料种类繁多,其中硬质合金是制造这些切削工具的主要使用材料。尽管在几何形状和材料类型上有很大的变化,但这些工具的一个反复出现且重要的特性是锋利度。确实,切削工具的锋利度直接与工件的最终质量相关。
为了应对数控加工中固有的刀具磨损问题,已经设计了各种自动刀具磨损估计技术,如消耗的轴功率/电流、振动测量、多普勒雷达和声学等。在本文中,我们将重点关注使用0 kHz至60 kHz范围内的超声波声学信号,使用超声波麦克风阵列传感器。该传感器基于eRTIS超声波传感器,它允许通过波束形成实现宽带空间滤波器的实现。在如CNC操作这样的高噪声场景中使用波束形成过滤掉不需要的噪声源来提高信号的信噪比;然后,使用卷积神经网络来执行切削工具的剩余使用寿命(RUL)预测。
1 方法
1.1 数据采集
- 超声波麦克风阵列: 使用多个超声波麦克风组成的阵列,采集加工过程中刀具与工件相互作用产生的声波信号。
- 信号同步: 确保不同麦克风采集的信号时间同步,以便进行后续的信号处理。
- 其他传感器: 可以根据需要,采集其他传感器数据,例如振动传感器、电流传感器等,用于辅助刀具磨损预测。
1.2 信号处理
- 波束形成: 利用波束形成技术,将多个麦克风采集的信号进行加权求和,增强来自刀具方向的声音信号,抑制其他方向的噪声,提高信噪比。
- 滤波:对波束形成后的信号进行滤波,例如带通滤波,去除低频噪声和高频噪声,保留与刀具磨损相关的频率成分。
- 时频分析: 对滤波后的信号进行时频分析,例如短时傅里叶变换(STFT),将信号分解为不同时间和频率的成分,得到时频谱图。
- 特征提取: 从时频谱图中提取与刀具磨损相关的特征,例如能量、频率、熵等。
1.3 模型构建
- 卷积神经网络(CNN): 使用CNN模型对提取的特征进行学习,建立特征与刀具磨损状态之间的关系。
- 模型结构: CNN模型可以包含卷积层、池化层、全连接层等,可以根据具体问题进行调整。
- 损失函数: 选择合适的损失函数,例如均方误差(MSE)或交叉熵等,用于评估模型预测结果与真实值之间的差异。
1.4 模型训练
- 数据集划分: 将采集到的数据划分为训练集、验证集和测试集。
- 数据增强: 对训练数据进行增强,例如添加噪声、改变采样率等,提高模型的鲁棒性。
- 优化器: 选择合适的优化器,例如Adam、SGD等,用于更新模型参数。
- 超参数调整: 调整模型的各种超参数,例如学习率、批大小等,以获得更好的模型性能。
1.5 模型评估
- 预测精度: 使用测试集评估模型的预测精度,例如计算均方误差、平均绝对误差等指标。
- 泛化能力: 评估模型在不同工况下的泛化能力,例如使用不同材料、不同刀具、不同加工参数等数据进行测试。
- 可解释性: 研究如何解释CNN模型的预测结果,例如可视化CNN模型的特征图,帮助理解模型的决策过程。
2 实验
2.1 硬件设置

- 上图面板a):两个eRTIS超声波传感器,带有32个麦克风的超声波麦克风阵列传感器,采样率为450 kHz。一个eRTIS传感器被放置在车床内部,另一个放置在操作员站立位置的外部。eRTIS传感器以10 Hz的速率测量了40毫秒的声学数据块(即信号是间歇性采样的)
- 上图面板b):使用了一台工业级数控车床(Mazak QT10N)
- 上图面板c):展示了安装在车床内的eRTIS传感器内部
- 上图面板d):加工的材料
- 上图面板e):拉伸试验样品的模型
- 制造了350个拉伸测试样品,使用了两种材料(1.1191 C45和1.7225 Chromoly)
- 使用Fluke i1000s电流钳的轴电流,连接到National Instruments NI-USB6363 DAQ,该DAQ以500 kHz的采样率同时采样电流信号和同步信号。
2.2 频谱图
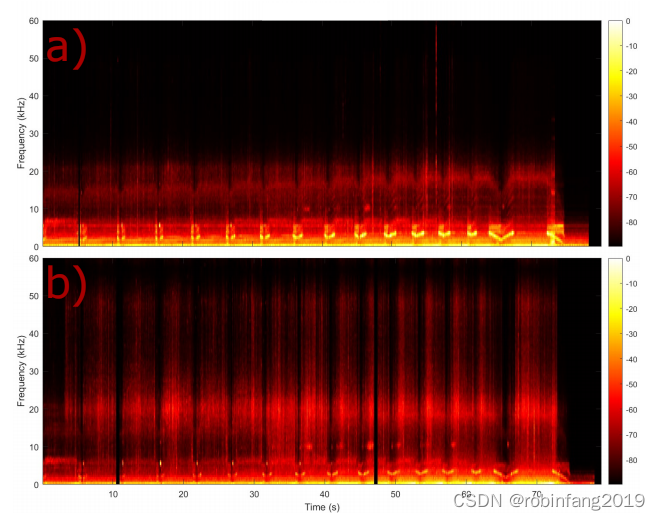
- 上图为eRTIS传感器在车削运行期间记录的声学数据的频谱图表示。
- 上图面板a)显示了在车床外部由eRTIS传感器测量的数据。
- 上图面板b)显示了从车床内部记录的数据。
- 在低频部分,信号主要由机器的运动声音支配,而频谱图的高频部分则是由切削操作产生的。
3 信号处理和实验结果
3.1 信号处理
3.1.1 数据采集
- 传感器: 使用两个 eRTIS 超声波传感器,一个放置在机床内部,另一个放置在机床外部,采集超声波信号。
- 采样频率: 450 kHz
- 采样时长: 40 ms
- 采样间隔: 10 Hz
3.1.2 波束形成
- 目的: 通过聚焦麦克风信号到刀具位置,提高信噪比,滤除噪声和干扰。
- 方法: 使用波束形成技术,根据麦克风阵列的几何结构和传感器与刀具之间的距离,计算每个麦克风的权重,并进行加权求和。
- 参数: 波束方向指向刀具位置,即传感器指向刀具的向量。
3.1.3 频域转换
- 目的: 将时域信号转换为频域信号,揭示不同频率成分的能量分布,从而更容易提取与刀具磨损相关的特征。
- 方法: 使用 Welch 功率谱密度估计器,对波束形成后的信号进行傅里叶变换。
- 参数: 窗口长度 1024 个样本,汉明加权。
3.1.4 数据拼接
- 目的: 将所有频谱图拼接成一个大矩阵,形成类似于声谱图的表示形式,方便后续的 CNN 模型处理。
- 方法: 将每个频谱图按照时间顺序排列,形成一个三维矩阵,其中两个维度表示频率和帧号,第三个维度表示麦克风编号。
3.2 CNN模型架构
构建一个包含 4 个卷积层(leaky ReLu激活函数,平均池化,批量归一化和dropout(10%))的 CNN 模型,用于预测刀具剩余使用寿命 (RUL)。模型输入为超声波声谱图,输出为工件编号,从而间接预测刀具磨损程度。
- 卷积层:网络包含四个卷积层,这些层负责从输入数据中提取特征。每个卷积层都会对输入的声学频谱图数据进行卷积操作,以识别和提取重要的特征。
- 激活函数:在卷积层之后,使用leaky ReLu(线性整流单元)激活函数。Leaky ReLu是一种改进版的ReLU激活函数,它允许负值通过一个很小的斜率,从而解决了ReLU在负值时梯度消失的问题。
- 池化层:接着是平均池化层,它用于降低特征的空间维度,同时保留最重要的信息。这有助于减少计算量,并使特征检测更加鲁棒。
- 批量归一化:网络还包含批量归一化层,这有助于加速训练过程,并减少对初始化权重的敏感性。批量归一化通过对每个小批量数据进行归一化处理来工作,这有助于稳定和加速神经网络的训练。
- Dropout:为了提高网络的泛化能力并防止过拟合,网络使用了dropout技术。Dropout以一定的概率随机丢弃一些网络连接,迫使网络学习更加鲁棒的特征表示。
- 全连接层:在卷积层和池化层之后,输出被展平并通过两个全连接(FC)层。全连接层是神经网络中负责进行高级特征融合和最终预测的部分。
- 输出层:第一个全连接层的输出维度为10,使用ReLu非线性激活函数。最后一个全连接层是输出层,它有一个单一的输出节点,用于预测基于输入声学频谱图的工件编号,即预测刀具的剩余使用寿命。
3.3 模型训练
- 优化器选择:使用了Adam优化器来训练神经网络。Adam优化器是一种自适应学习率优化算法,它结合了动量(Momentum)和RMSprop的关键思想,通常在训练深度学习模型时表现良好。
- 学习率设置:为Adam优化器设置的学习率为0.01,这是一个常用的初始学习率值,有助于模型在训练初期快速收敛。
- 训练周期:设定了最多100个训练周期(epoch),每个周期中,整个数据集都会被用来更新网络的权重一次。
- 验证损失检查点:在训练过程中,使用验证损失来监控模型的性能。我们保留了具有最佳验证损失的网络参数作为最终模型,这有助于防止过拟合,并确保模型在未见数据上也能表现良好。
- 数据增强:为了提高模型的泛化能力,我们对训练数据进行了增强,包括在时间维度上的平移和添加噪声。数据增强有助于模型学习到更加鲁棒的特征,减少对特定训练样本的依赖。
- 数据集划分:将增强后的数据集随机分为三个部分:训练集(占总数据的75%),验证集(占10%),和测试集(占15%)。这样的划分有助于我们在训练过程中评估模型的性能,并在训练结束后使用测试集来评估模型的最终性能。
- 训练时长:在单个NVidia RTX4090 GPU上进行模型训练,包括数据预处理,大约需要一个小时。这表明我们的训练流程相对高效,能够在合理的时间内完成模型的训练。
3.4 模型评估
- 预测误差:使用均方误差 (MSE) 作为预测误差指标,衡量预测值与真实值之间的差异。
- 误差方差:分析预测误差的方差,评估模型的稳定性。方差越小,说明模型的预测结果越稳定。
- 模型结构比较:比较不同模型结构的性能,选择最优模型。例如,比较使用不同数量卷积层和全连接层的模型性能。
- 数据增强效果:分析数据增强技术对模型性能的影响。例如,比较使用和不使用数据增强技术的模型性能。
- 交叉验证:使用交叉验证评估模型的泛化能力。例如,将数据集分成训练集和测试集,训练模型并在测试集上进行评估。
3.5 实验结果
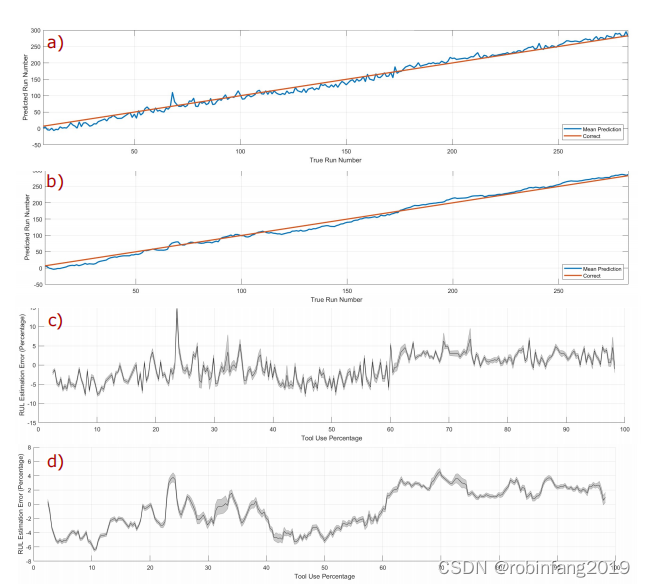
- 上图面板a):显示了基于单个声学频谱图的运行编号预测
- 上图面板b)显示了使用五个以所需运行编号为中心的频谱图的预测。
- 上图面板c)和d):显示了平均运行编号预测误差,包括预测的方差带(灰色阴影),占总工具寿命的百分比。
结果表明,通过超声波传感器和深度学习模型的结合,可以有效地预测数控车削中的刀具磨损。通过分析声学信号的频谱图,CNN能够以较高的精度估计刀具的剩余使用寿命,这对于预测性维护任务具有潜在的应用价值。
这篇关于使用超声波麦克风阵列预测数控机床刀具磨损的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





