本文主要是介绍34 Debian如何配置ELK群集,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者:网络傅老师
特别提示:未经作者允许,不得转载任何内容。违者必究!
Debian如何配置ELK群集
《傅老师Debian知识库系列之34》——原创
==前言==
傅老师Debian知识库特点:
1、拆解Debian实用技能;
2、所有操作在VMware虚拟机实测完成;
3、致力于最终形成Debian知识手册;
适合人群:想通俗易懂地学习Debian相关知识的同学
阅读建议:无。过于精炼易懂,正常看就行。
所用版本:Debian 12.4
一、概念
ELK其实就是一个用来管理日志的“神器组合”。想象一下,你的服务器们每天都在产生大量的日志,这些日志里记录着各种信息,有时候你想找某个特定的信息或者分析一下日志,那可就头疼了。但是有了ELK,这个问题就轻松解决了!
Elasticsearch就像是一个超级大的图书馆,它可以存储海量的数据,并且能快速地帮你找到你想要的信息。
Logstash就像是一个勤劳的图书管理员,它负责把各种各样的日志搜集起来,然后按照一定的规则进行整理和分析,最后送到Elasticsearch这个大图书馆里去。
Kibana呢,它就是一个非常友好的用户界面,你可以通过它来查询、分析和展示存储在Elasticsearch里的数据。你可以很直观地看到各种统计图表,帮助你更好地理解数据。
二、前置知识
1、Elasticsearch群集:
- 比较吃内存,每个节点至少4G起步。
- 依赖Java,但是从Elasticsearch7版本开始内置了Java,不用预先安装了。
2、Logstash的数据处理流程:
- Input:负责从指定数据源接收数据。
- Filter:对接收到的数据进行过滤,包括解析、转换、筛选等。Filter不是必须的。
- Output:将数据发送到指定的目标位置,如Elasticsearch。
三、操作方法
案例:如图34.1所示。部署ELK群集使其协同工作,实现Logstash获取Apache2的日志并发送到Elasticsearch,然后在Kibana的web界面查看。
为了节约实验资源,Kibana就安装在节点Node1上,另外apache2就和Logstash装在同一台主机上。
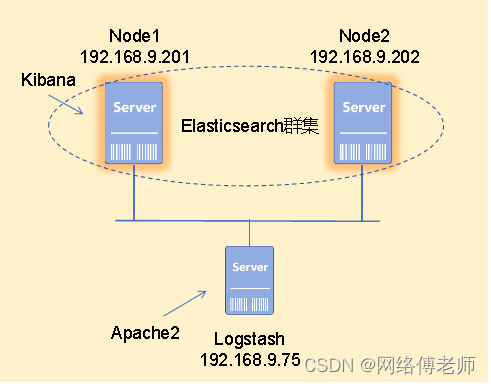
图33.1 Zabbix案例环境
1、配置两个节点的主机名解析
root@Node1:~# nano /etc/hosts
127.0.0.1 localhost
127.0.0.1 Node1
192.168.9.201 Node1
192.168.9.202 Node2root@Node2:~# nano /etc/hosts
127.0.0.1 localhost
127.0.0.1 Node2
192.168.9.201 Node1
192.168.9.202 Node22、安装Elasticsearch群集节点1
(1)Node1安装Elasticsearch
root@Node1:~# wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | gpg --dearmor -o /usr/share/keyrings/elasticsearch-keyring.gpg
//下载并导入Elasticsearch的GPG密钥,以验证软件包的真实性和完整性
root@Node1:~# apt install apt-transport-https
//安装apt-transport-https软件包。这个软件包提供了对HTTPS APT仓库的支持
root@Node1:~# echo "deb [signed-by=/usr/share/keyrings/elasticsearch-keyring.gpg] https://artifacts.elastic.co/packages/8.x/apt stable main" | tee /etc/apt/sources.list.d/elastic-8.x.list
//向APT源列表中添加Elasticsearch的APT仓库
root@Node1:~# apt update
root@Node1:~# apt install elasticsearch注意:安装完成后,一定要把这个elastic用户的初始密码E5Fzpl4NC1vGuO*zLui*记下来,后面要用!!如图34.2所示。
这篇关于34 Debian如何配置ELK群集的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






